Mybatis
1.Mybatis入门
1.1 Mybatis定义
MyBatis是一款优秀的 持久层 框架,用于简化JDBC的开发。
MyBatis本是 Apache的一个开源项目iBatis,2010年这个项目由apache迁移到了google code,并且改名为MyBatis 。2013年11月迁移到Github。
在上面我们提到了两个词:一个是持久层,另一个是框架
- 持久层:指的是就是数据访问层(dao),是用来操作数据库的
- 框架:是一个半成品软件,是一套可重用的、通用的、软件基础代码模型。在框架的基础上进行软件开发更加高效、规范、通用、可拓展
1.2 入门程序分析
现在使用Mybatis操作数据库,就是在Mybatis中编写SQL查询代码,发送给数据库执行,数据库执行后返回结果
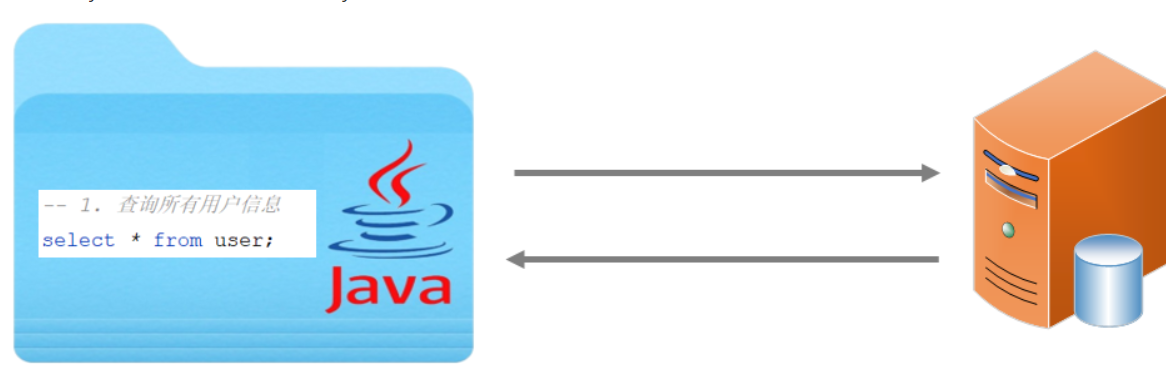
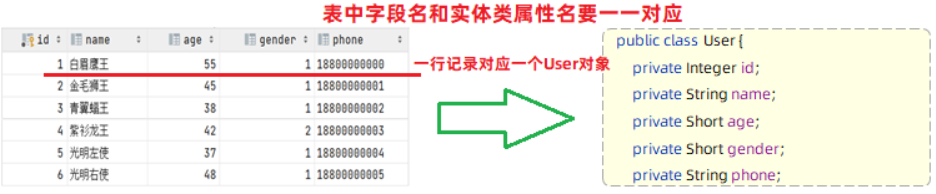
Mybatis会把数据库执行的查询结果,使用实体类封装起来(一行记录对应一个实体类对象)
1.3 入门程序实现步骤
- 准备工作(创建springboot工程、数据库表user、实体类User)
- 在pom.xml中引入Mybatis的相关依赖,
- yml文件中配置Mybatis(数据库连接信息)
- mapper层编写SQL语句(注解/XML):resources目录/mapper/XX.xml文件配置
- sringboot启动类增加自动扫描:@MapperScan(“xx.xx.mapper”) //告诉springboot扫描
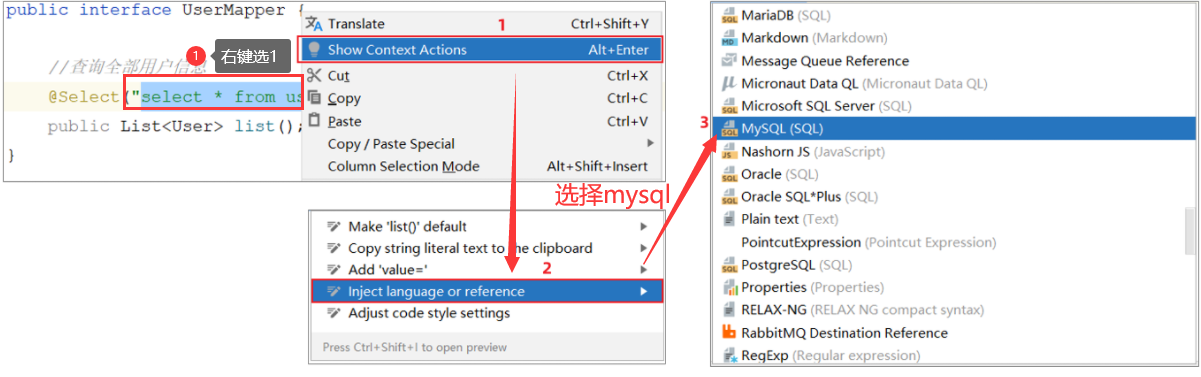
1.3 解决mapper层编写sql语句不提醒
1.4 JDBC
1.4.1 介绍
通过Mybatis可以很方便的进行数据库的访问操作。但是大家要明白,其实java语言操作数据库呢,只能通过一种方式:使用sun公司提供的 JDBC 规范
Mybatis框架,就是对原始的JDBC程序(Java语言操作关系型数据库的一套API)的封装
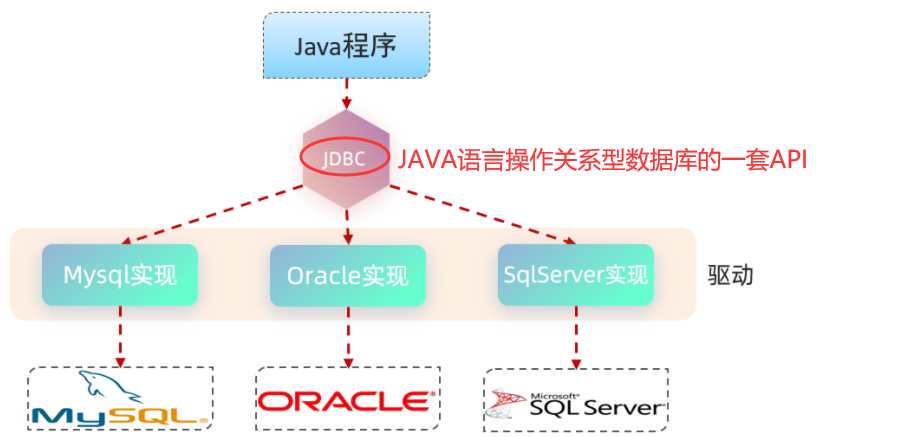
本质:
sun公司官方定义的一套操作所有关系型数据库的规范,即接口。
各个数据库厂商去实现这套接口,提供数据库驱动jar包。
我们可以使用这套接口(JDBC)编程,真正执行的代码是驱动jar包中的实现类。
1.4.2 代码
下面我们看看原始的JDBC程序是如何操作数据库的。操作步骤如下:
- 注册驱动
- 获取连接对象
- 执行SQL语句,返回执行结果
- 处理执行结果
- 释放资源
在pom.xml文件中已引入MySQL驱动依赖,我们直接编写JDBC代码即可
JDBC具体代码实现:
1 | import com.itheima.pojo.User; |
DriverManager(类):数据库驱动管理类。
作用:
注册驱动
创建java代码和数据库之间的连接,即获取Connection对象
Connection(接口):建立数据库连接的对象
- 作用:用于建立java程序和数据库之间的连接
Statement(接口): 数据库操作对象(执行SQL语句的对象)。
- 作用:用于向数据库发送sql语句
ResultSet(接口):结果集对象(一张虚拟表)
- 作用:sql查询语句的执行结果会封装在ResultSet中
通过上述代码,我们看到直接基于JDBC程序来操作数据库,代码实现非常繁琐,所以在项目开发中,我们很少使用。 在项目开发中,通常会使用Mybatis这类的高级技术来操作数据库,从而简化数据库操作、提高开发效率
1.4.3 问题分析
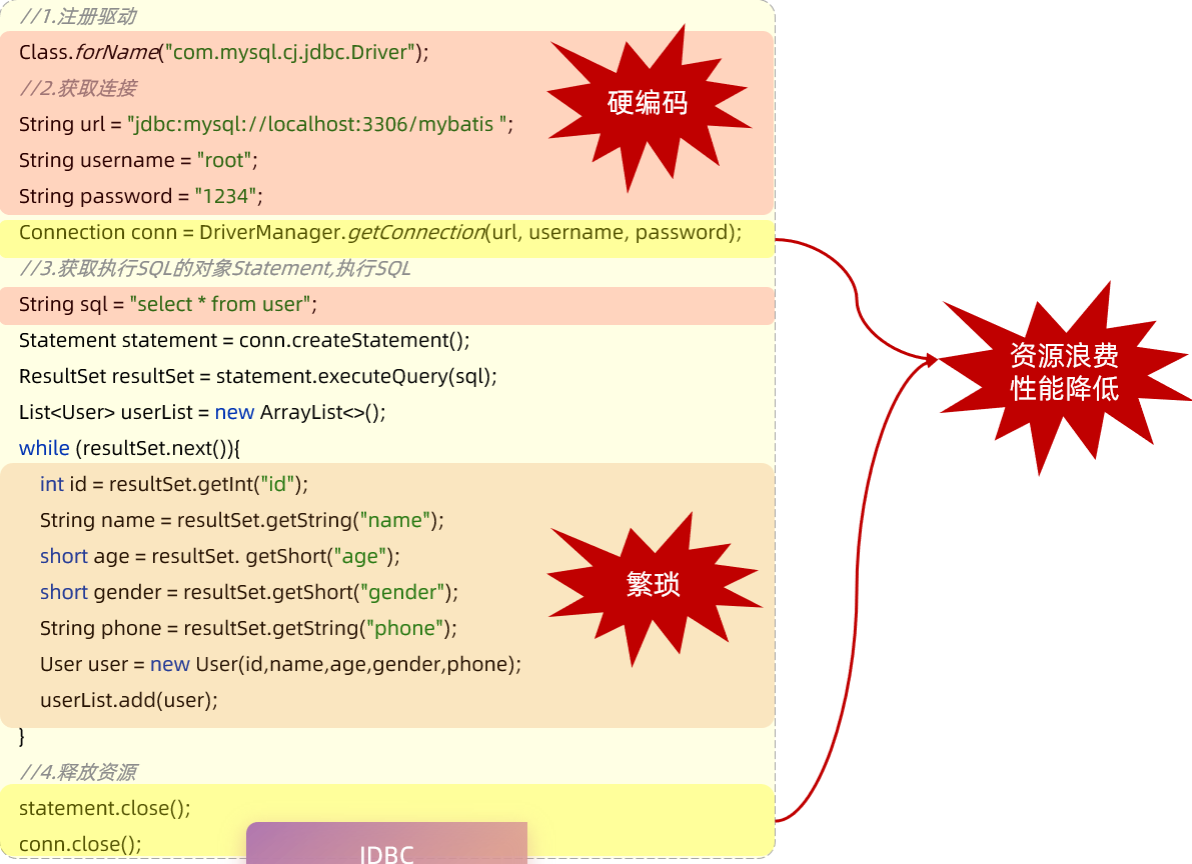
原始的JDBC程序,存在以下几点问题:
- 数据库链接的四要素(驱动、链接、用户名、密码)全部硬编码在java代码中
- 查询结果的解析及封装非常繁琐
- 每一次查询数据库都需要获取连接,操作完毕后释放连接, 资源浪费, 性能降低
1.4.4 mybatis优化点
分析了JDBC的缺点之后,我们再来看一下在mybatis中,是如何解决这些问题的:
数据库连接四要素(驱动、链接、用户名、密码),都配置在springboot默认的配置文件 application.properties中
查询结果的解析及封装,由mybatis自动完成映射封装,我们无需关注
在mybatis中使用了数据库连接池(Springboot默认Hikari追光者)技术,从而避免了频繁的创建连接、销毁连接而带来的资源浪费。

1.5 数据库连接池(四种)
1.5.1 介绍
没有使用数据库连接池:
- 客户端执行SQL语句:要先创建一个新的连接对象,然后执行SQL语句,SQL语句执行后又需要关闭连接对象从而释放资源,每次执行SQL时都需要创建连接、销毁链接,这种频繁的重复创建销毁的过程是比较耗费计算机的性能。
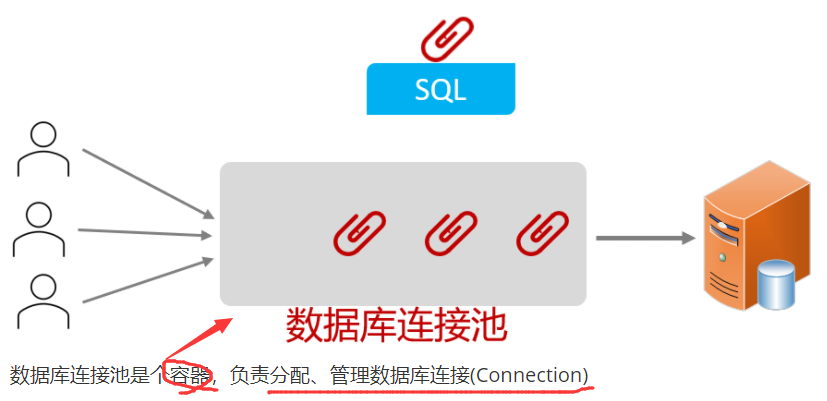
- 程序在启动时,会在数据库连接池(容器)中,创建一定数量的Connection对象
允许应用程序重复使用一个现有的数据库连接,而不是再重新建立一个
- 客户端在执行SQL时,先从连接池中获取一个Connection对象,然后在执行SQL语句,SQL语句执行完之后,释放Connection时就会把Connection对象归还给连接池(Connection对象可以复用)
释放空闲时间超过最大空闲时间的连接,来避免因为没有释放连接而引起的数据库连接遗漏
- 客户端获取到Connection对象了,但是Connection对象并没有去访问数据库(处于空闲),数据库连接池发现Connection对象的空闲时间 > 连接池中预设的最大空闲时间,此时数据库连接池就会自动释放掉这个连接对象
数据库连接池的好处:
- 资源重用
- 提升系统响应速度
- 避免数据库连接遗漏
1.5.2 四种连接池
常见的数据库连接池:
- C3P0
- DBCP
- Druid
- Hikari (springboot默认)
现在使用更多的是:Hikari、Druid (性能更优越)
Hikari(追光者) [默认的连接池]
Druid(德鲁伊)
Druid连接池是阿里巴巴开源的数据库连接池项目
功能强大,性能优秀,是Java语言最好的数据库连接池之一
1.5.3 更换连接池
把默认的数据库连接池切换为Druid数据库连接池,只需要完成以下两步操作即可:
参考官方地址:https://github.com/alibaba/druid/tree/master/druid-spring-boot-starter
1.在pom.xml文件中引入依赖
1 | <dependency> |
2.在配置文件中引入数据库连接配置(2种方式)
1 | 方式1:(datasource后面加druid) |
1.6 lombok(编译阶段)
1.6.1 介绍
Lombok是一个实用的Java类库,可以通过简单的注解来简化和消除一些必须有但显得很臃肿的Java代码

通过注解的形式自动生成构造器、getter/setter、equals、hashcode、toString等方法,并可以自动化生成日志变量,简化java开发、提高效率
| 注解 | 作用 |
|---|---|
| @Getter/@Setter | 为所有的属性提供get/set方法 |
| @ToString | 为类自动生成易阅读的 toString 方法 |
| @EqualsAndHashCode | 为类提供拥有的非静态字段自动重写 equals 方法和 hashCode 方法 |
| @Data | 提供了更综合的生成代码功能(@Getter + @Setter + @ToString + @EqualsAndHashCode) 集成了前四个注解 |
| @NoArgsConstructor | 为实体类生成无参的构造器方法 |
| @AllArgsConstructor | 为实体类生成除了static修饰的字段之外带有各参数的构造器方法。 |
1.6.2 使用步骤
第1步:在pom.xml文件中引入依赖
1 | <!-- 在springboot的父工程中,已经集成了lombok并指定了版本号,故当前引入依赖时不需要指定version --> |
第2步:在实体类上添加注解
1 | import lombok.Data; |
2.Mybatis基础操作
2.1 新增(@Insert)

2.2 删除(@Delete)

2.3 查询(@Selete)

2.4 修改(@Update)

3.Mybatis两种书写sql语句的形式
3.1 第一种–mapper层注解

3.2 第二种–xml映射文件
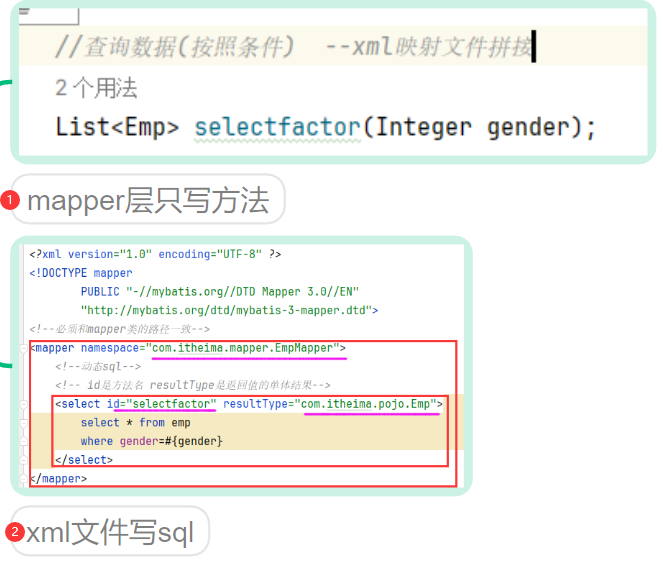
3.2.1 创建xml文件[规范和准则]
- 整体图
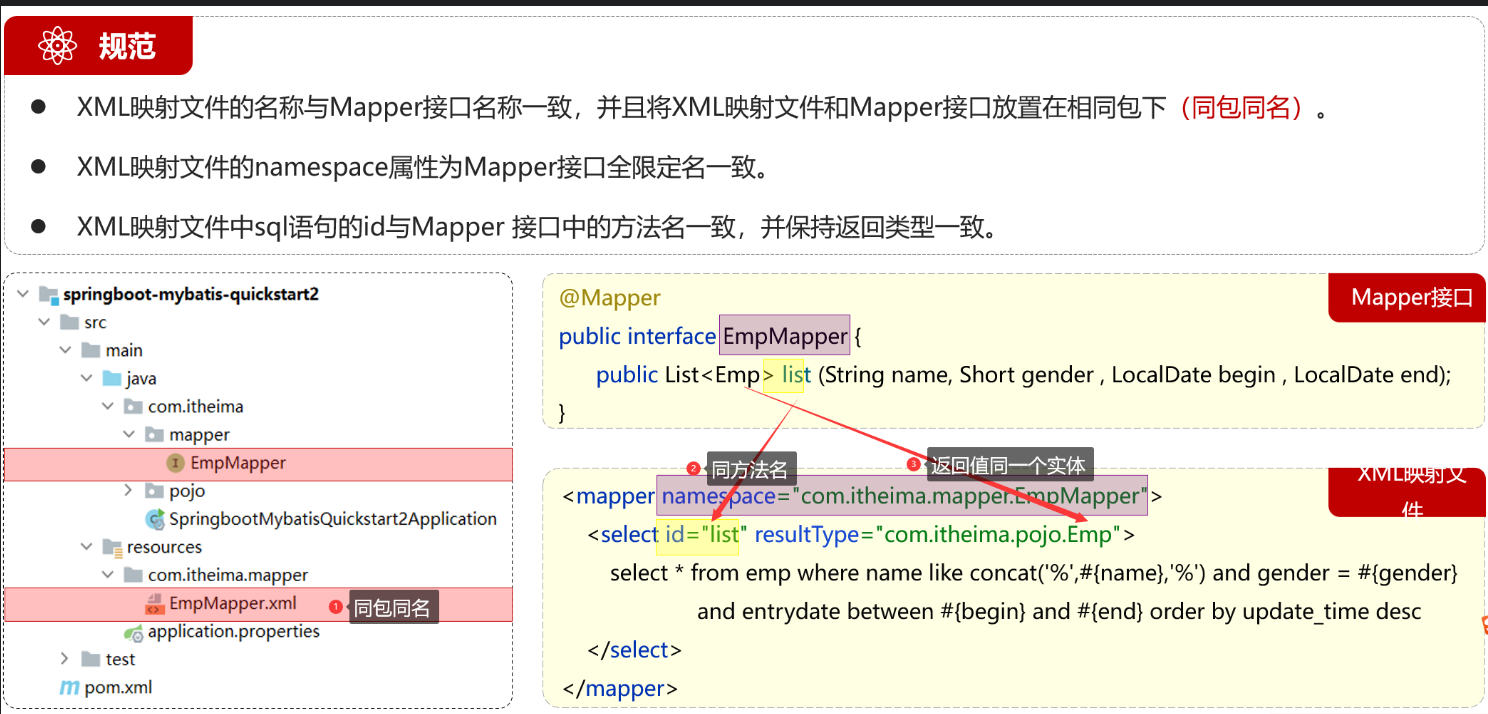
创建位置:必须要和mapper层保持同一个包级别和同名(==同包同名==)
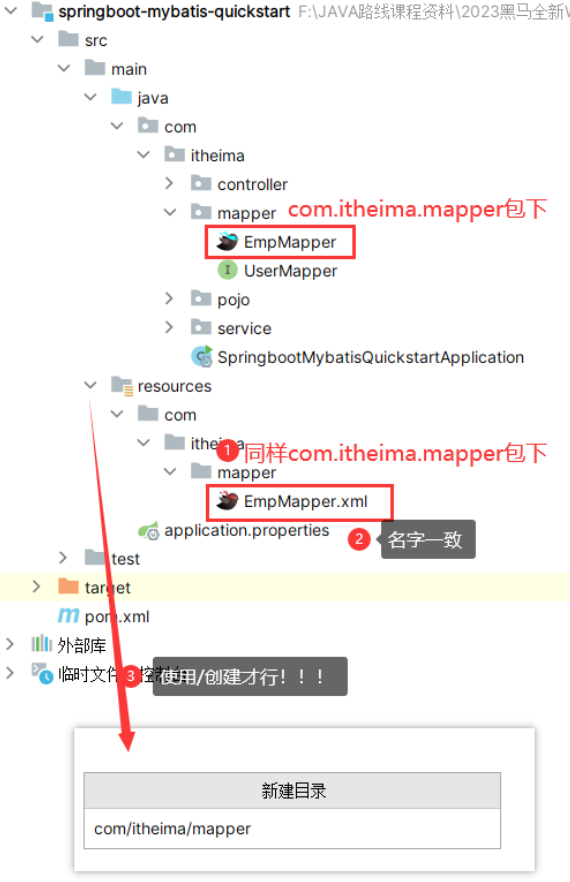
命名规则:要保证mapper的namespacce和mapper同全路径名,四大类语句的id要和方法名一致,resultType要和方法返回值(最里面的)一致
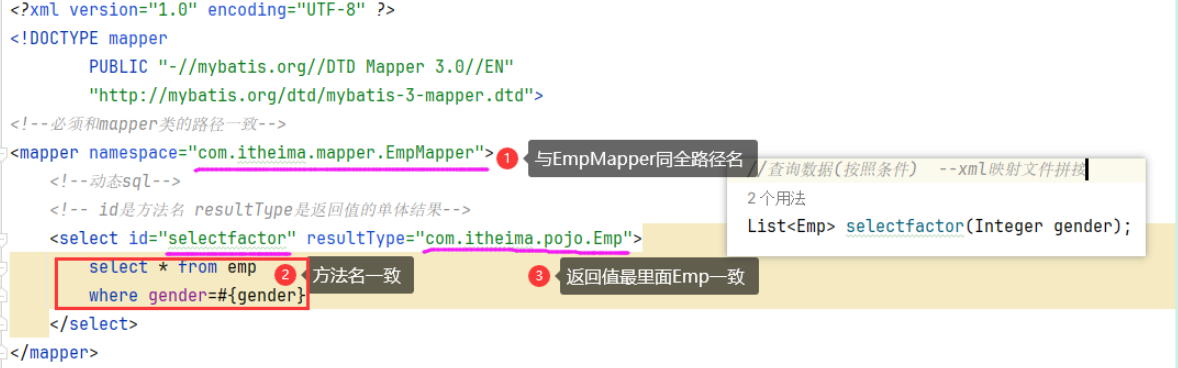
4.动态sql(在xml映射文件)
4.1 if
4.1.1 作用
用于判断条件是否成立 –如果条件为true就拼接sql
4.1.2 使用位置
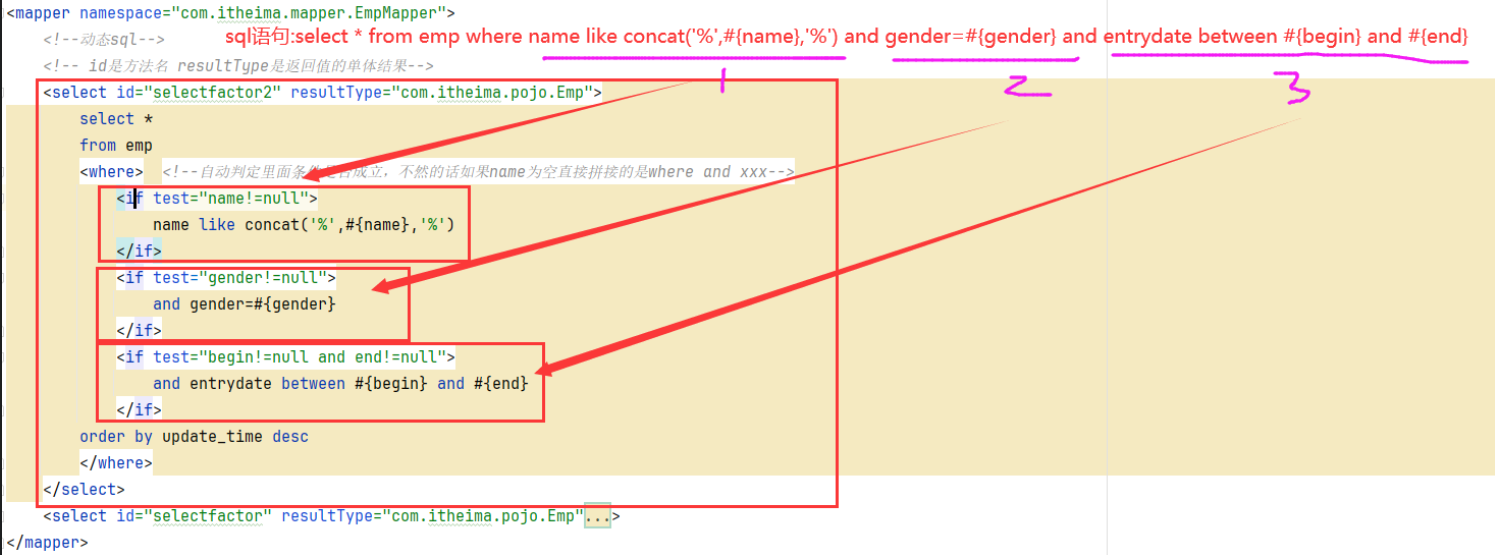
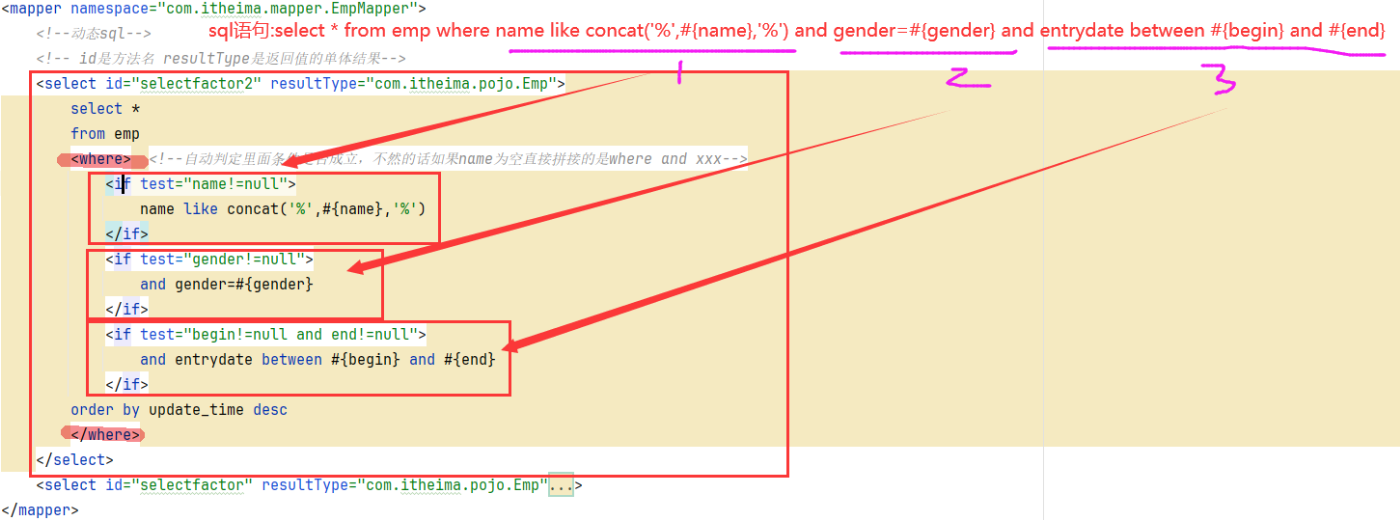
4.2 where
4.2.1 作用
1.在子元素有内容的情况下插入where子句
2.自动去除子句开头的and/or
4.2.2 使用位置
4.3 set
4.3.1 作用
1.动态的在行首插入set关键字
2.自动去除额外的逗号
4.3.2 使用位置

4.4 foreach
4.4.1 作用
循环的时候批量处理一部分数据
4.4.2 使用位置

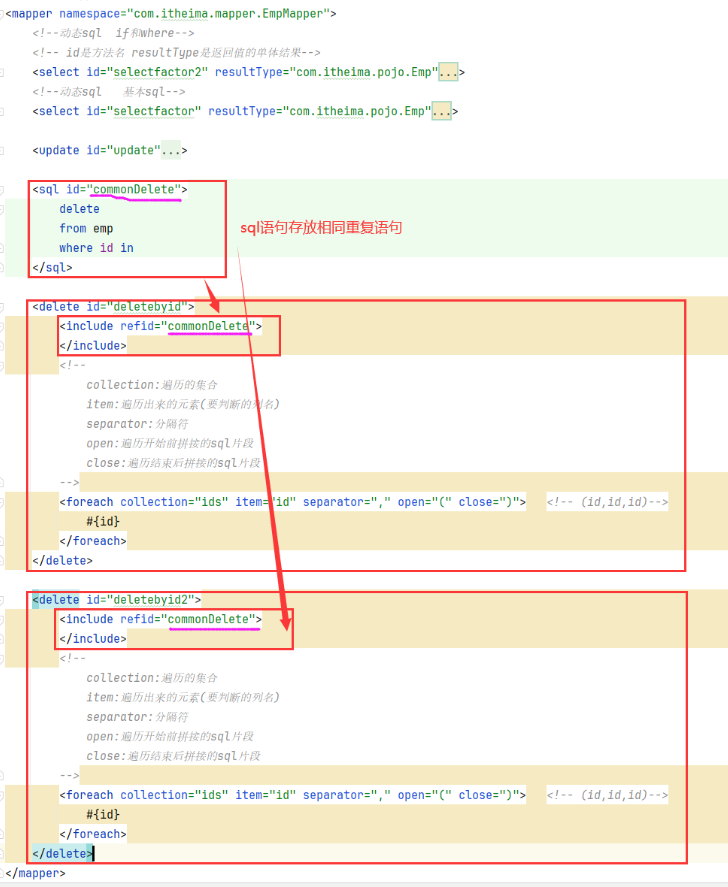
4.5 sql和include
4.5.1 作用
将一些固定的(重复的/相同的)sql提取出来
4.5.2 使用位置
4.6 choose-when-otherwise
4.6.1 作用
类似于Java的Switch语句,可以实现选择
4.6.2 使用位置

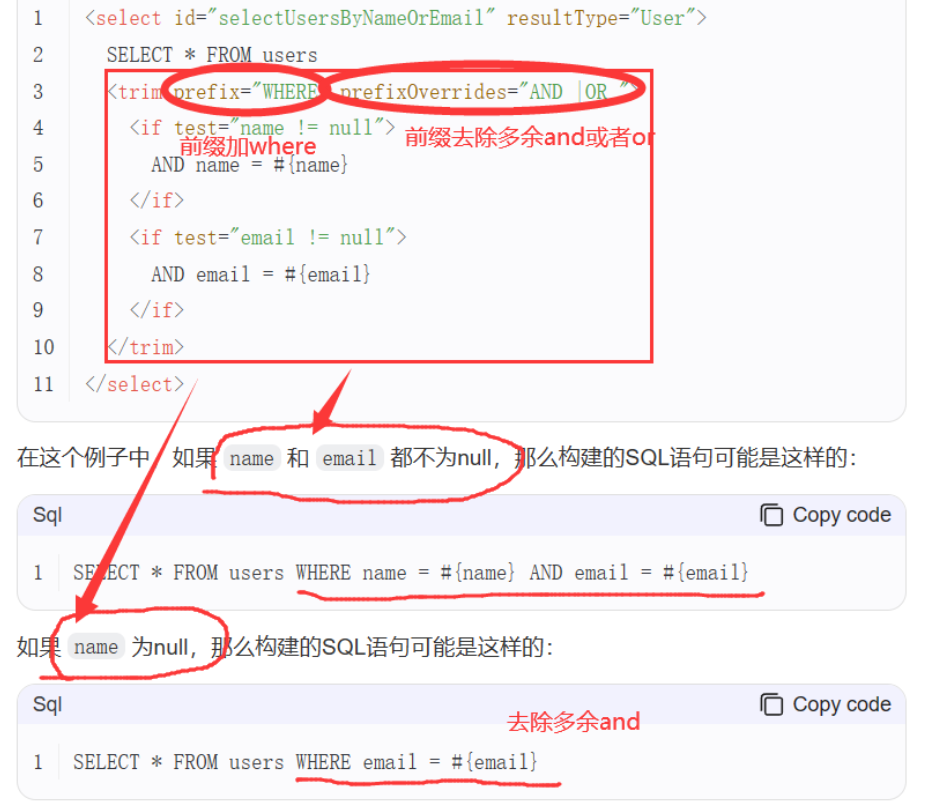
4.7 trim
4.7.1 作用
生成sql语句的时候,在前后添加自定义的字符串
4.7.2 使用位置
prefix:加前缀
prefixOverrides:要覆盖的前缀
suffix:加后缀
suffixOverrides:要覆盖的后缀
4.8 bind
4.8.1 作用
可以将表达式结果/特定内容绑定到一个变量,这个变量可以在sql语句中使用【类似于参数宏定义】
4.8.2 使用位置

5.mybatis日志输出
在Mybatis当中我们可以借助日志,查看到sql语句的执行、执行传递的参数以及执行结果。具体操作如下:
- 打开application.properties文件
- 开启mybatis的日志,并指定输出到控制台
1 | #指定mybatis输出日志的位置, 输出控制台 |
开启日志之后,我们再次运行单元测试,可以看到在控制台中,输出了以下的SQL语句信息:
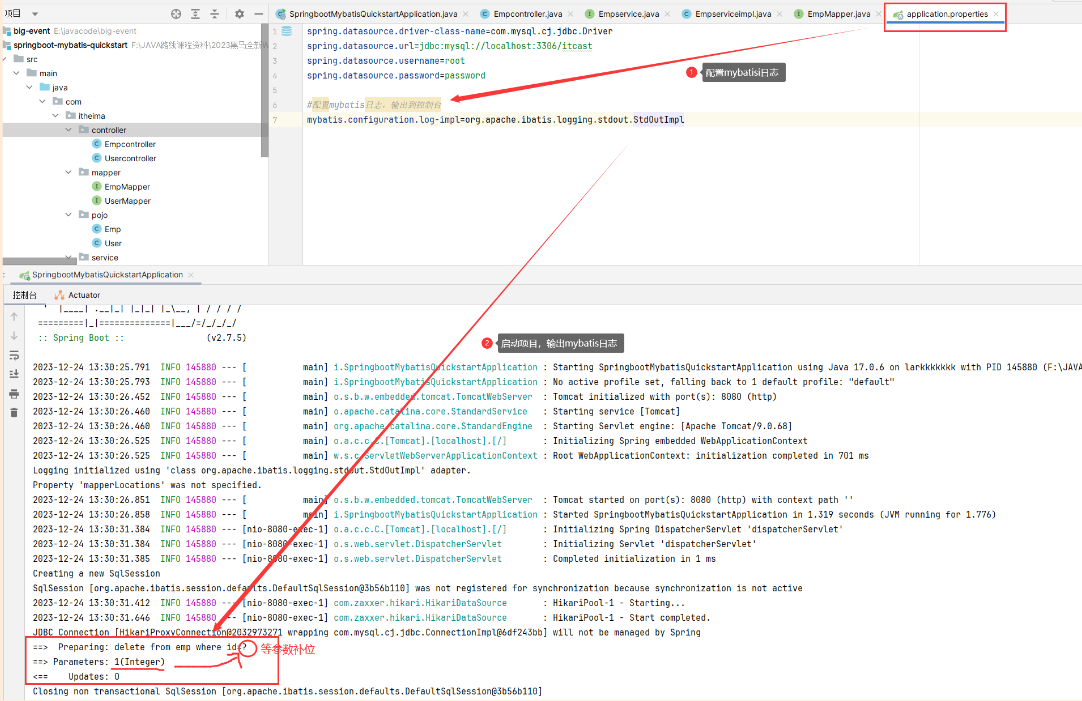
但是我们发现输出的SQL语句:delete from emp where id = ?,我们输入的参数16并没有在后面拼接,id的值是使用?进行占位。那这种SQL语句我们称为预编译SQL
6.预编译SQL
mybatis中mapper层的写法就是预编译sql,传入参数放入的形式
预编译SQL有两个优势:
性能更高
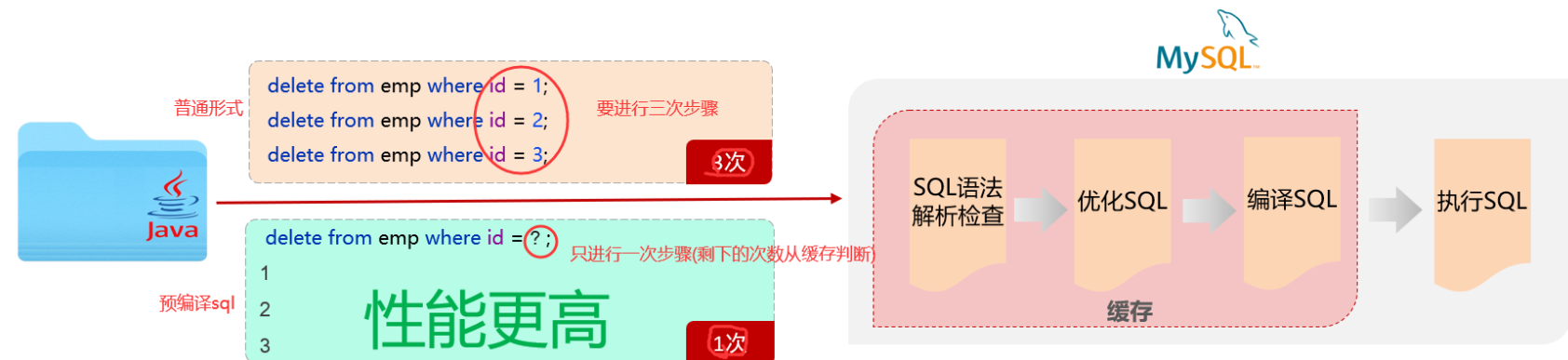
更安全(防止SQL注入)
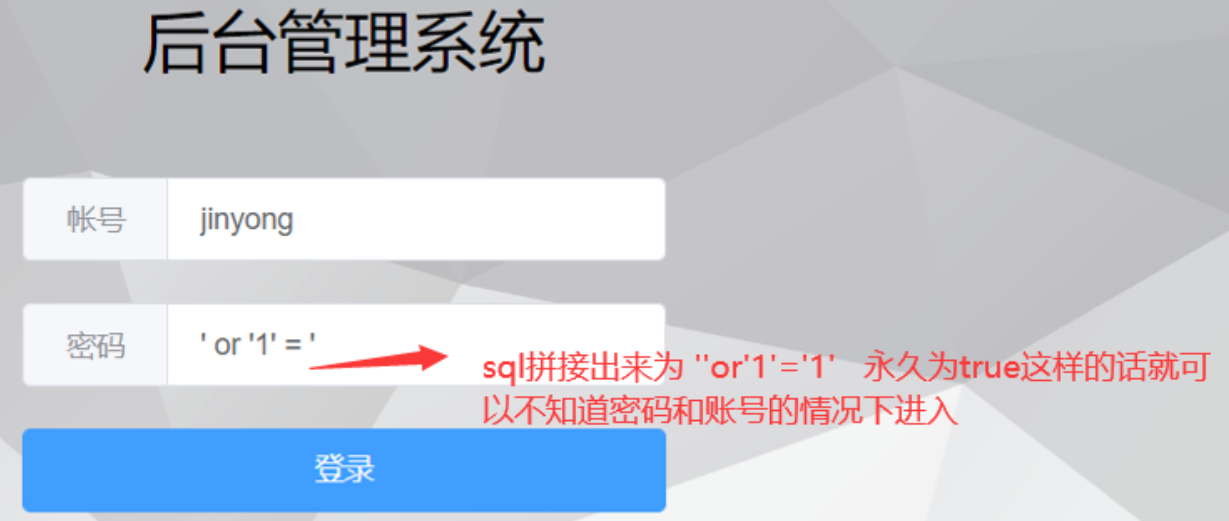
7.参数占位符

如果mapper接口方法形参只有一个普通类型的参数,#{…} 里面的属性名可以随便写
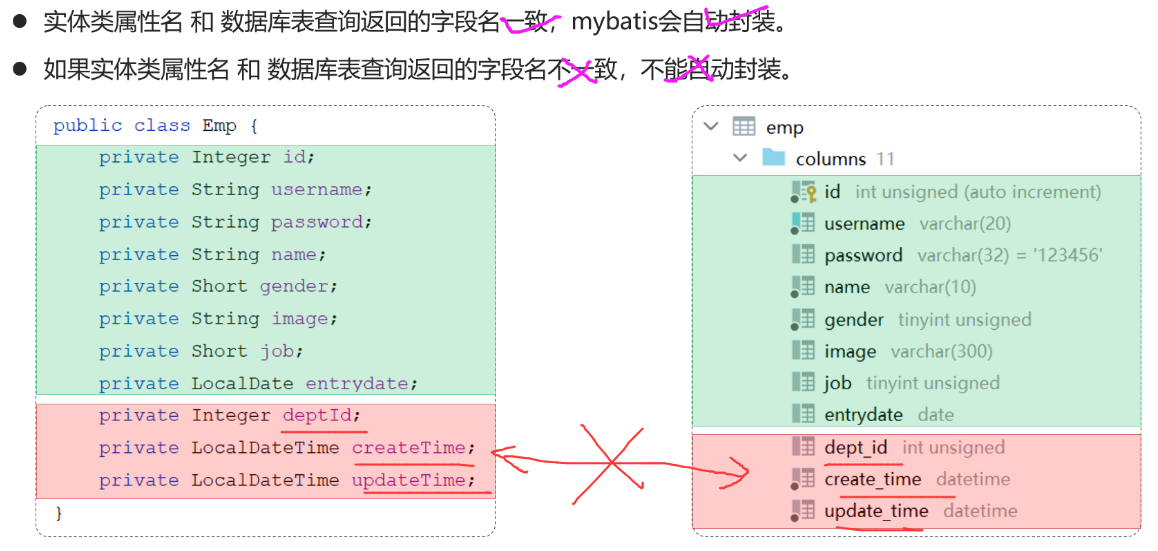
8.数据封装(mysql列名和实体类属性名不一致)
8.1 出现场景

8.2 三种解决方案
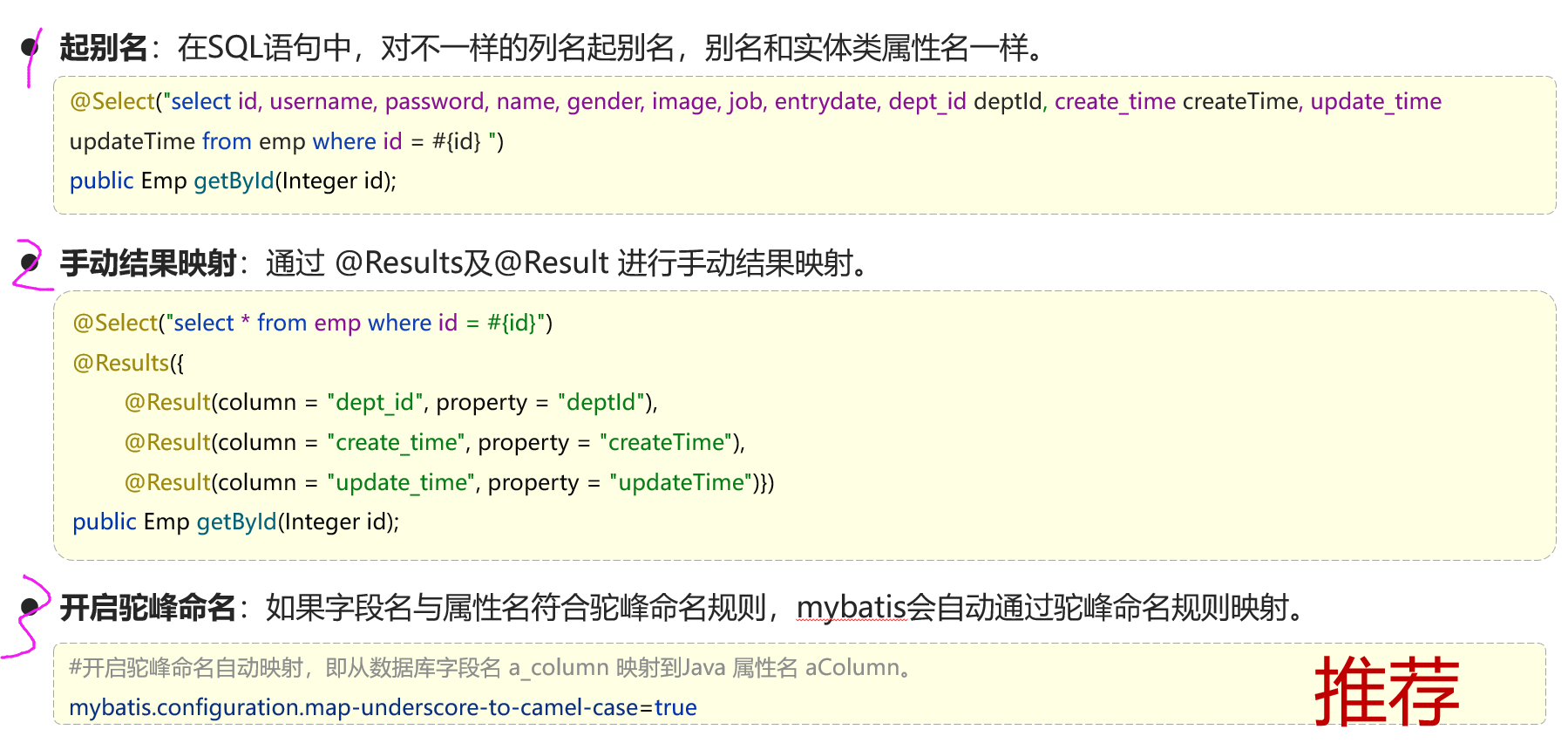
1. mapper层sql语句内起别名

2.mapper层方法上添加@Results和@Result注解手动映射

3.yml配置文件打开驼峰命名(推荐)

9.#{}和${}区别
#{}表达式为OGNL表达式
${}表达式为EL表达式
1)相同:都可以获取对象的信息。
(2)#{ }
执行SQL时,会将#{ }替换为?,生成预编译SQL,会自动设置参数值,防止SQL注入
使用时机:参数传递,都使用#{ }
(3)${ }
拼接SQL。直接将参数拼接在SQL语句中,存在SQL注入问题
使用时机:如果对表名、列表进行动态设置时使用【东林微课堂创建每个月赛季表】
(4)#{ } 只能操作跟数据字表字段相关的列值,跟列值无关的只能用${ }
(5)#{ } 底层使用的是PreparedStatement,${ } 底层使用的是 Statement
SpringBootWeb请求
0.SpringBootWeb请求响应
0.1 如何请求和响应
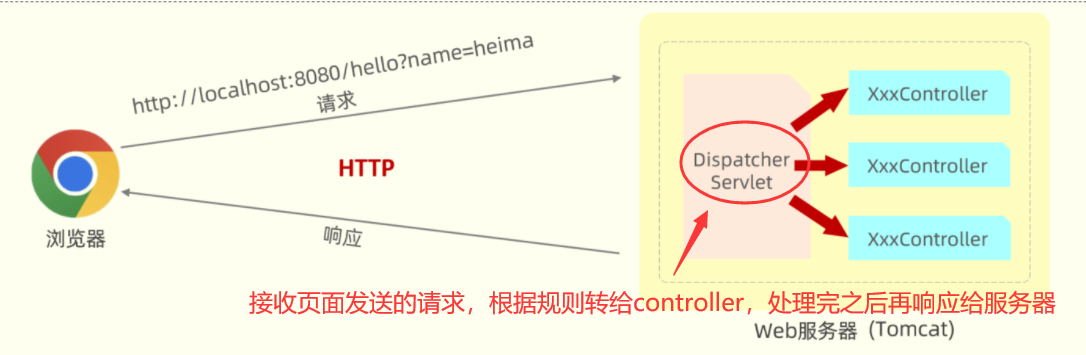
在SpringBoot进行web程序开发时,它内置了一个核心的Servlet程序 DispatcherServlet,称之为 核心控制器。
DispatcherServlet 负责接收页面发送的请求,然后根据执行的规则,将请求再转发给后面的请求处理器Controller,请求处理器处理完请求之后,最终再由DispatcherServlet给浏览器响应数据。
那将来浏览器发送请求,会携带请求数据,包括:请求行、请求头;请求到达tomcat之后,tomcat会负责解析这些请求数据,然后呢将解析后的请求数据会传递给Servlet程序的HttpServletRequest对象,那也就意味着 HttpServletRequest 对象就可以获取到请求数据。 而Tomcat,还给Servlet程序传递了一个参数 HttpServletResponse,通过这个对象,我们就可以给浏览器设置响应数据 。
那上述所描述的这种浏览器/服务器的架构模式呢,我们称之为:BS架构。

• BS架构:Browser/Server,浏览器/服务器架构模式。客户端只需要浏览器,应用程序的逻辑和数据都存储在服务端。
那今天呢,我们的课程内容主要就围绕着:请求、响应进行。 今天课程内容,主要包含三个部分:
- 请求
- 响应
- 分层解耦
0.2 自我理解
其实之前就是servlet去写响应和请求的信息,但是后来有了tomcat就可以省略了对于请求三部分和响应三部分的解析,然后对于后端可以使用HttpServletRequest和Response去接受请求和设置响应,但是也很麻烦,最后就是框架的注解解决了。请求就通过判断@RequestBody等注解获取前端信息,然后响应就是@ResponseBody注解返回(Springboot类的RestController是一个组合注解里面就是controller和responsebody解决了这个顾虑)。
0.3 前后端分离
之前我们课程中有提到当前最为主流的开发模式:前后端分离
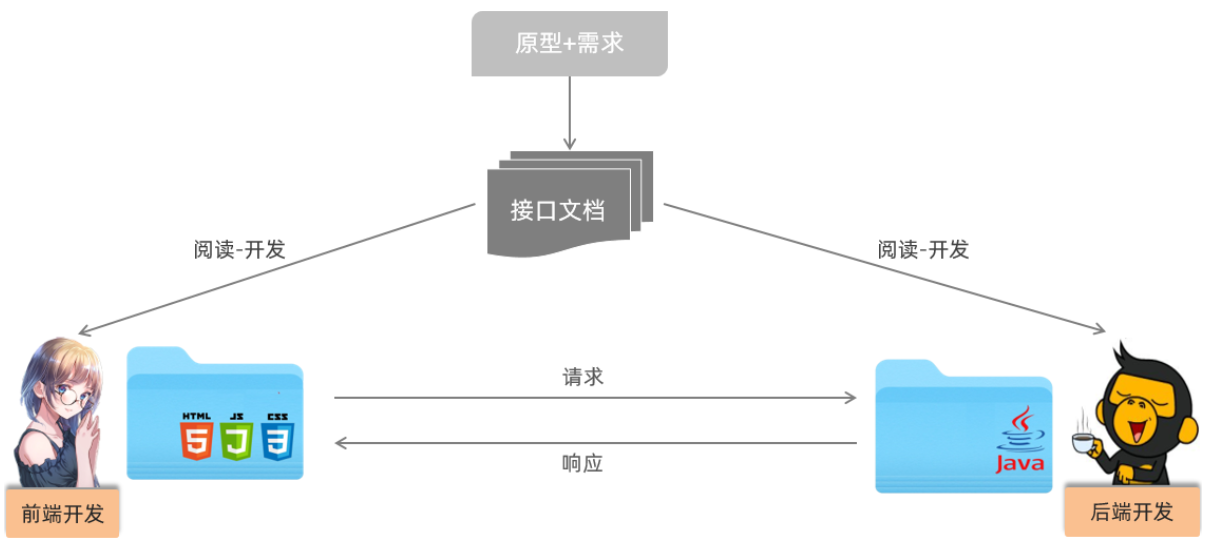
在这种模式下,前端技术人员基于”接口文档”,开发前端程序;后端技术人员也基于”接口文档”,开发后端程序。
由于前后端分离,对我们后端技术人员来讲,在开发过程中,是没有前端页面的,那我们怎么测试自己所开发的程序呢?
方式1:在浏览器中输入地址(只能测试get请求)
方式2:使用专业的接口测试工具(课程中我们使用Postman工具)
1. 请求
1.1 简单参数
简单参数:在向服务器发起请求时,向服务器传递的是一些普通的请求数据。

那么在后端程序中,如何接收传递过来的普通参数数据呢?
我们在这里讲解两种方式:
- 原始方式
- SpringBoot方式
1.2.1 原始方式
在原始的Web程序当中,需要通过Servlet中提供的API:HttpServletRequest(请求对象),获取请求的相关信息。比如获取请求参数:
Tomcat接收到http请求时:把请求的相关信息封装到HttpServletRequest对象中
在Controller中,我们要想获取Request对象,可以直接在方法的形参中声明 HttpServletRequest 对象。然后就可以通过该对象来获取请求信息:
1 | //根据指定的参数名获取请求参数的数据值 |
1 |
|
以上这种方式,我们仅做了解。(在以后的开发中不会使用到)
1.2.2 SpringBoot方式
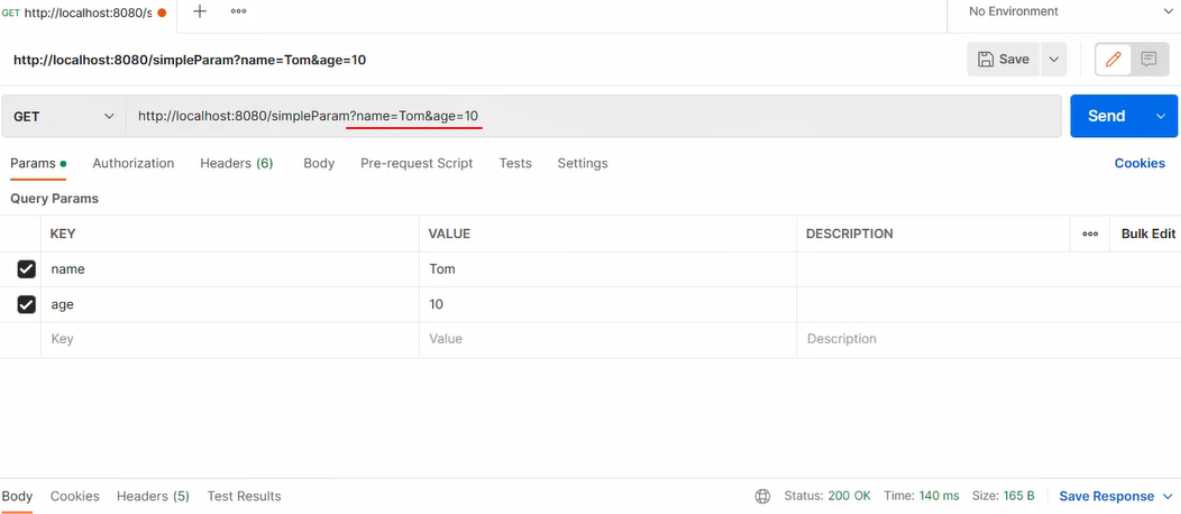
在Springboot的环境中,对原始的API进行了封装,接收参数的形式更加简单。 如果是简单参数,参数名与形参变量名相同,定义同名的形参即可接收参数。
1 |
|
postman测试( GET 请求):
postman测试( POST请求 ):
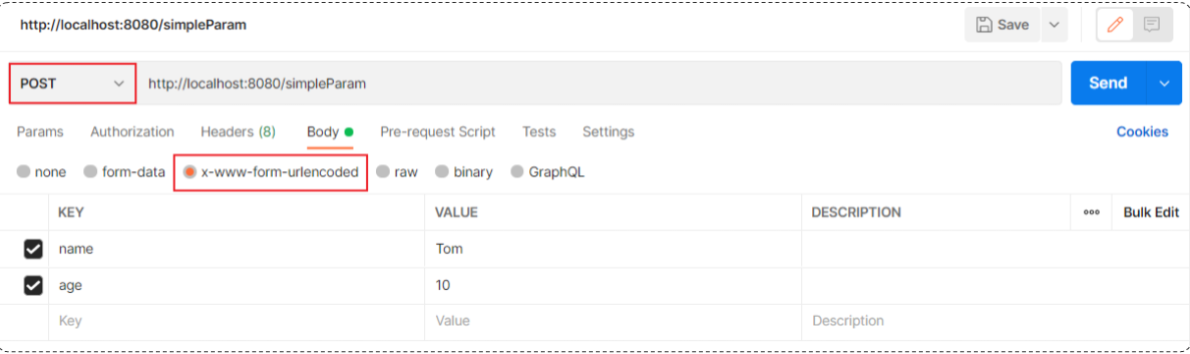
结论:不论是GET请求还是POST请求,对于简单参数来讲,只要保证==请求参数名和Controller方法中的形参名保持一致==,就可以获取到请求参数中的数据值。
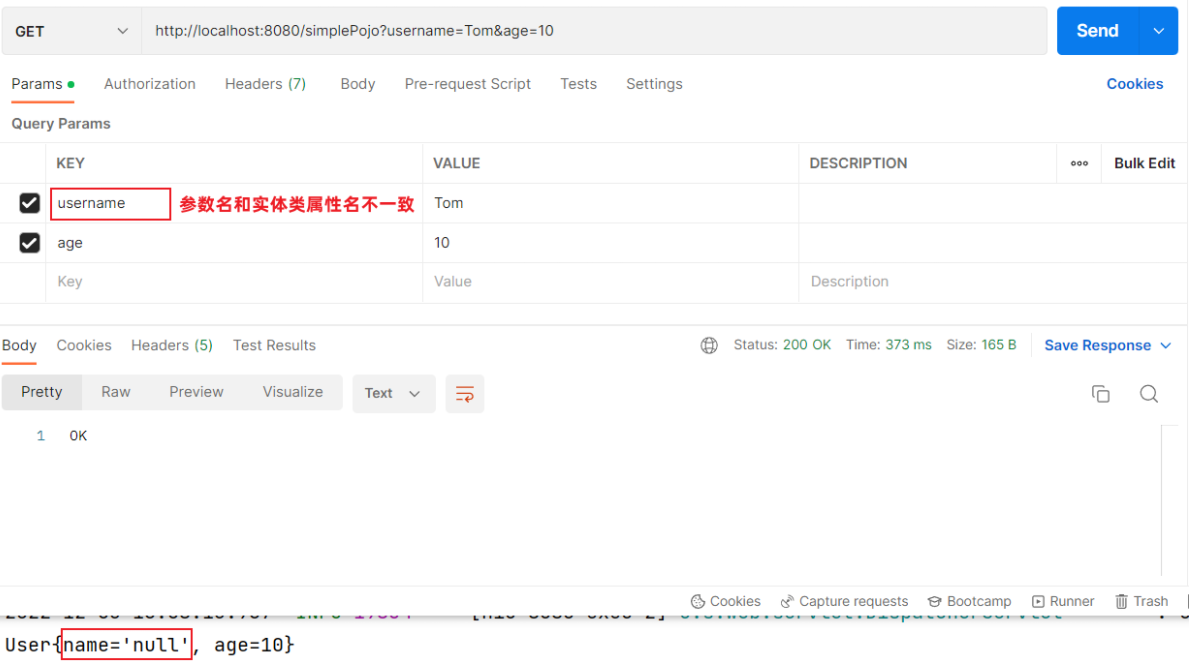
1.2.3 参数名不一致
如果方法形参名称与请求参数名称不一致,controller方法中的形参还能接收到请求参数值吗?
1 |
|
答案:运行没有报错。 controller方法中的username值为:null,age值为20
- 结论:对于简单参数来讲,请求参数名和controller方法中的形参名不一致时,无法接收到请求数据
那么如果我们开发中,遇到了这种请求参数名和controller方法中的形参名不相同,怎么办?
解决方案:可以使用Spring提供的@RequestParam注解完成映射
在方法形参前面加上 @RequestParam 然后通过value属性执行请求参数名,从而完成映射。代码如下:
1 |
|
注意事项:
@RequestParam中的required属性默认为true(默认值也是true),代表该请求参数必须传递,如果不传递将报错
如果该参数是可选的,可以将required属性设置为false
2
3
4
5
public String simpleParam(@RequestParam(name = "name", required = false) String username, Integer age){
System.out.println(username+ ":" + age);
return "OK";
}
1.3 实体参数
在使用简单参数做为数据传递方式时,前端传递了多少个请求参数,后端controller方法中的形参就要书写多少个。如果请求参数比较多,通过上述的方式一个参数一个参数的接收,会比较繁琐。
此时,我们可以考虑将请求参数封装到一个实体类对象中。 要想完成数据封装,需要遵守如下规则:请求参数名与实体类的属性名相同
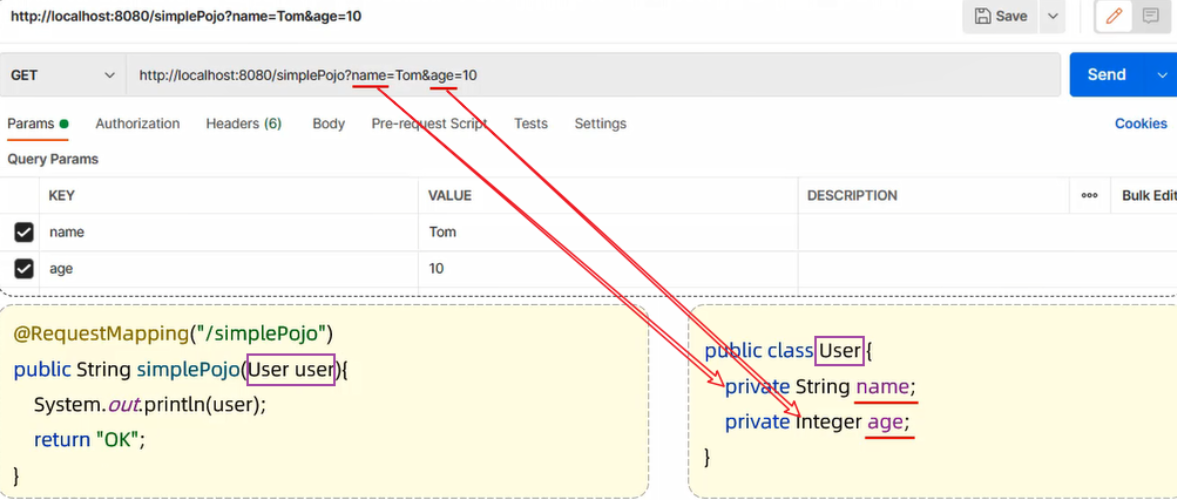
1.3.1 简单实体对象
定义POJO实体类:
1 | public class User { |
Controller方法:
1 |
|
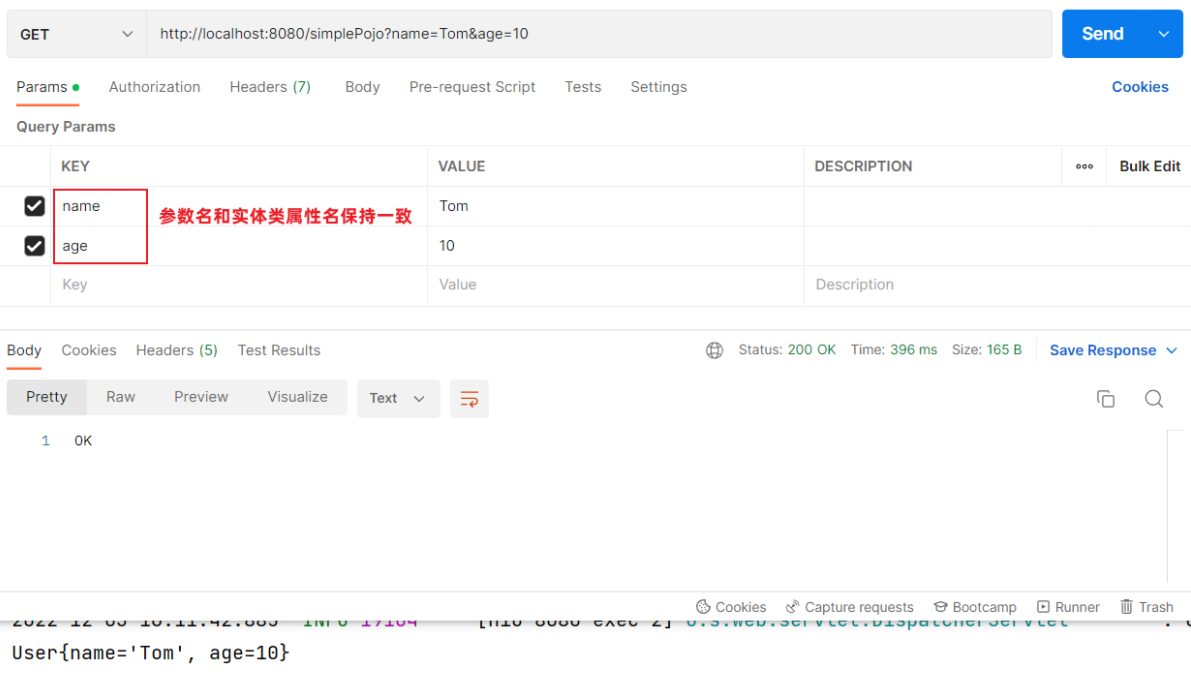
Postman测试:
- 参数名和实体类属性名一致时
- 参数名和实体类属性名不一致时
1.3.2 复杂实体对象
上面我们讲的呢是简单的实体对象,下面我们在来学习下复杂的实体对象。
复杂实体对象指的是,在实体类中有一个或多个属性,也是实体对象类型的。如下:
- User类中有一个Address类型的属性(Address是一个实体类)
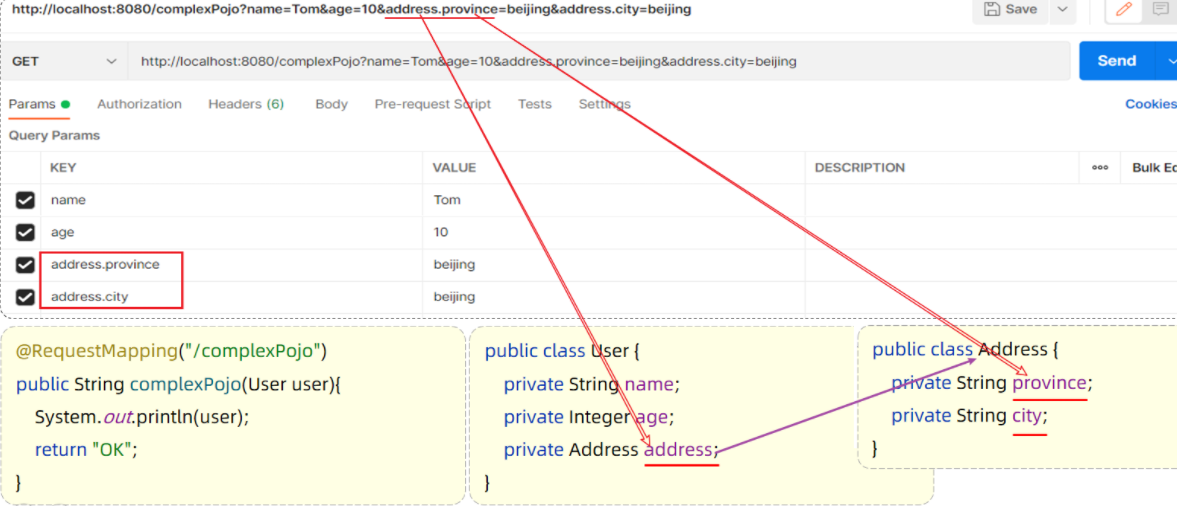
复杂实体对象的封装,需要遵守如下规则:
- 请求参数名与形参对象属性名相同,按照对象层次结构关系即可接收嵌套实体类属性参数。
定义POJO实体类:
- Address实体类
1 | public class Address { |
- User实体类
1 | public class User { |
Controller方法:
1 |
|
Postman测试:
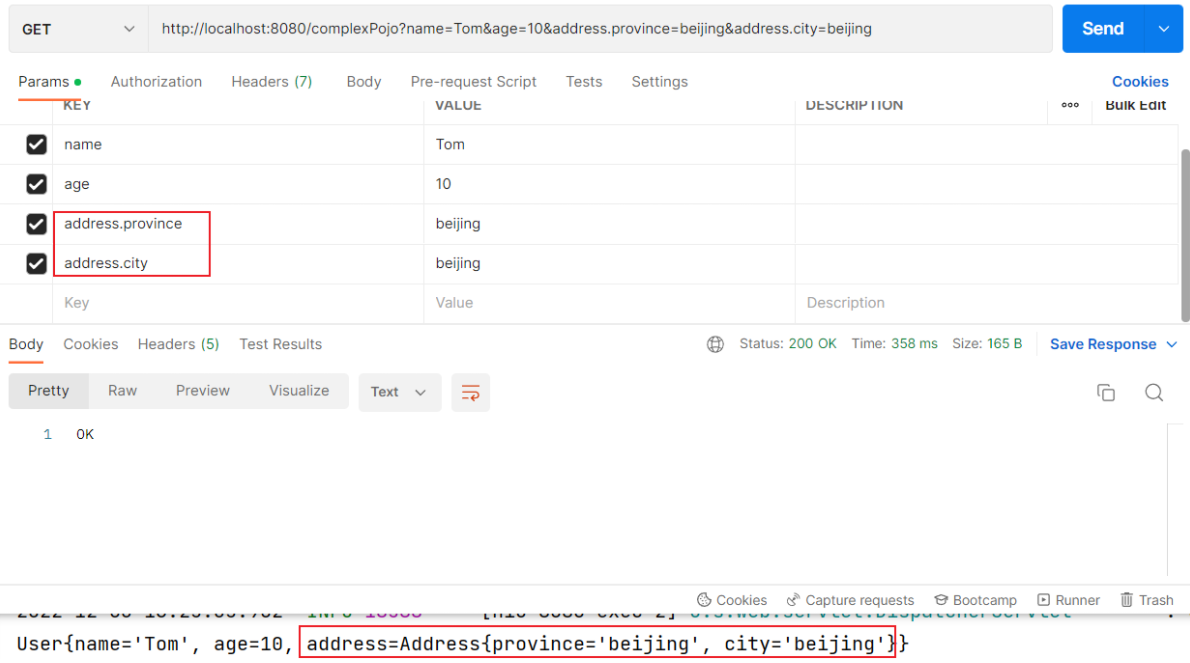
1.4 数组集合参数
数组集合参数的使用场景:在HTML的表单中,有一个表单项是支持多选的(复选框),可以提交选择的多个值。
多个值是怎么提交的呢?其实多个值也是一个一个的提交。

后端程序接收上述多个值的方式有两种:
- 数组
- 集合
1.4.1 数组
数组参数:请求参数名与形参数组名称相同且请求参数为多个,定义数组类型形参即可接收参数
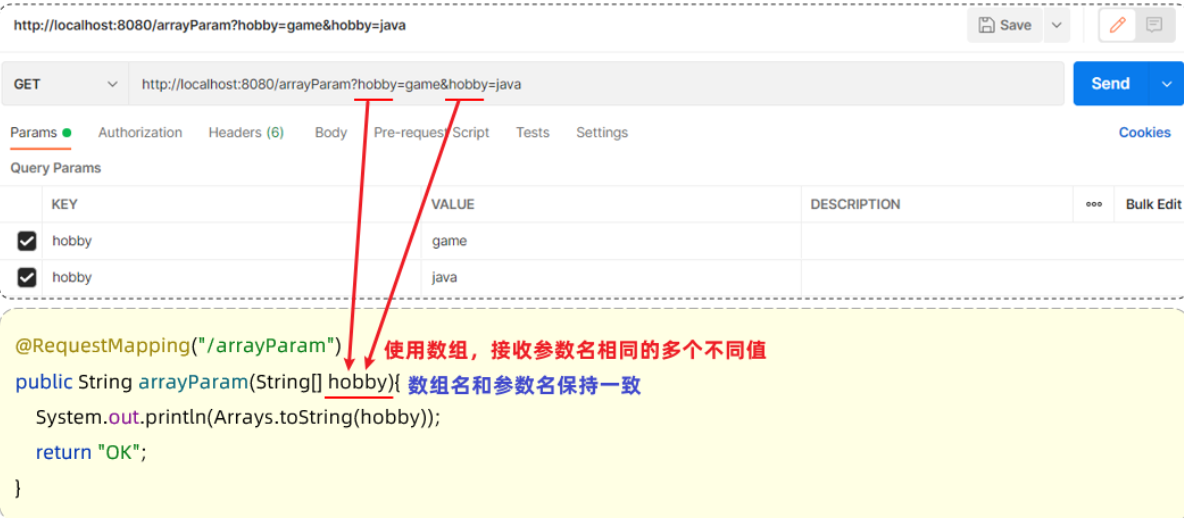
Controller方法:
1 |
|
Postman测试:
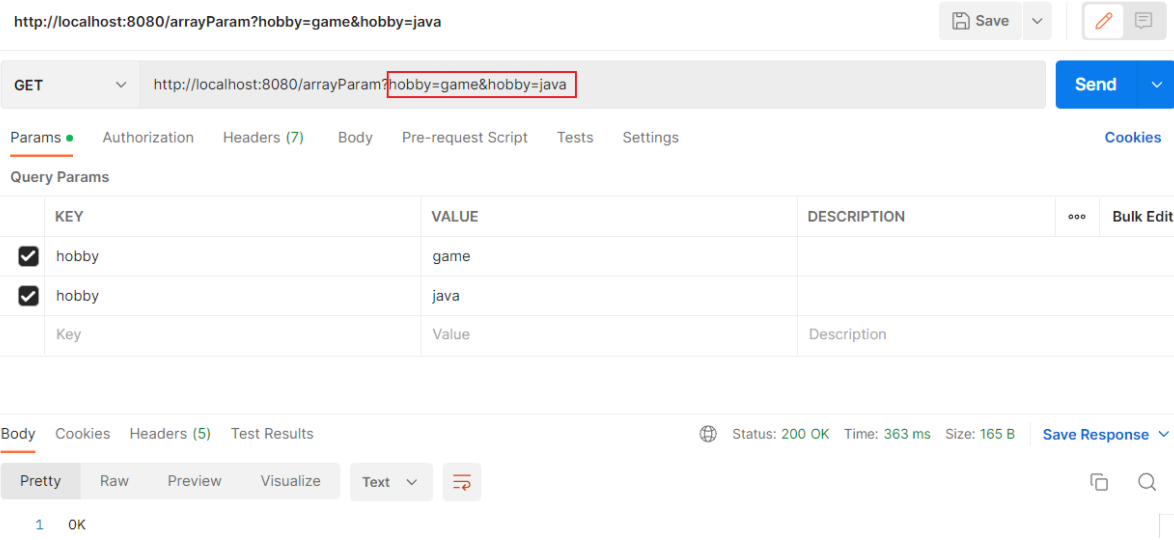
在前端请求时,有两种传递形式:
方式一: xxxxxxxxxx?hobby=game&hobby=java
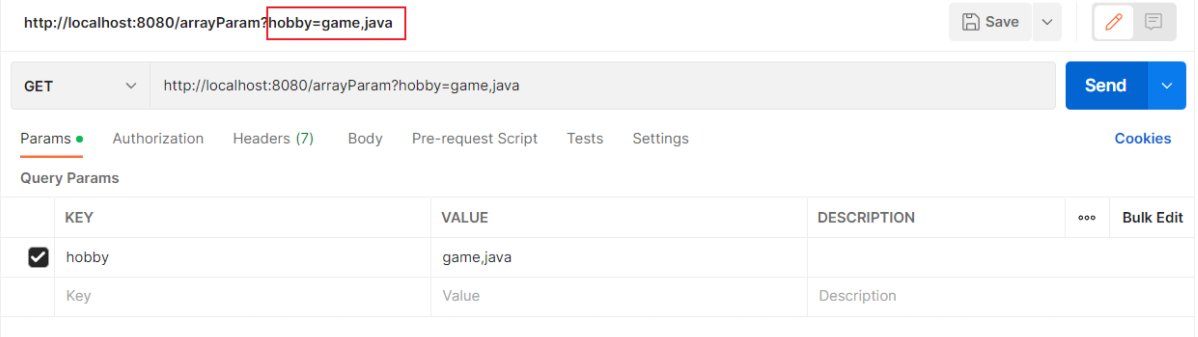
方式二:xxxxxxxxxxxxx?hobby=game,java
1.4.2 集合
集合参数:请求参数名与形参集合对象名相同且请求参数为多个,@RequestParam 绑定参数关系
默认情况下,请求中参数名相同的多个值,是封装到数组。如果要封装到集合,要使用@RequestParam绑定参数关系
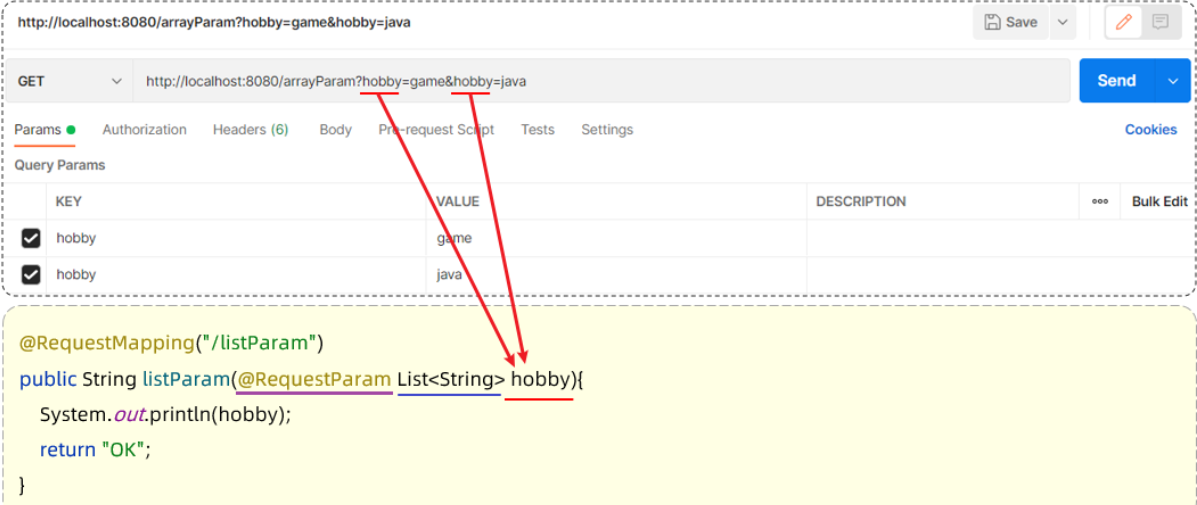
Controller方法:
1 |
|
Postman测试:
方式一: xxxxxxxxxx?hobby=game&hobby=java

方式二:xxxxxxxxxxxxx?hobby=game,java
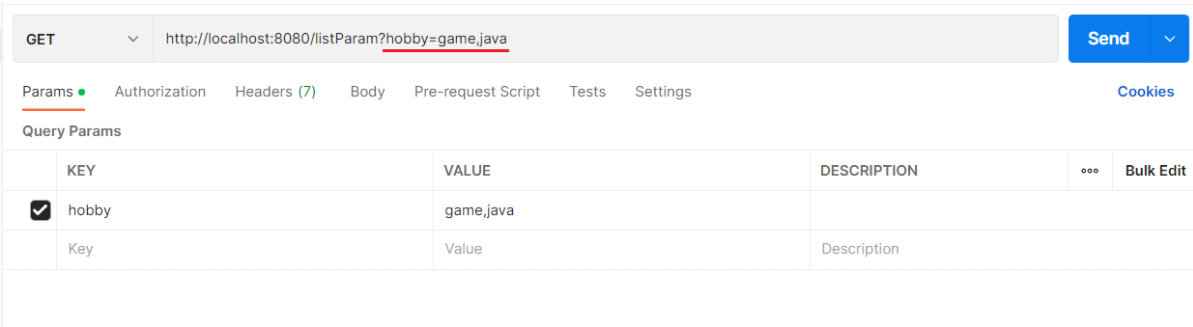
1.5 日期参数
上述演示的都是一些普通的参数,在一些特殊的需求中,可能会涉及到日期类型数据的封装。比如,如下需求:

因为日期的格式多种多样(如:2022-12-12 10:05:45 、2022/12/12 10:05:45),那么对于日期类型的参数在进行封装的时候,需要通过@DateTimeFormat注解,以及其pattern属性来设置日期的格式。
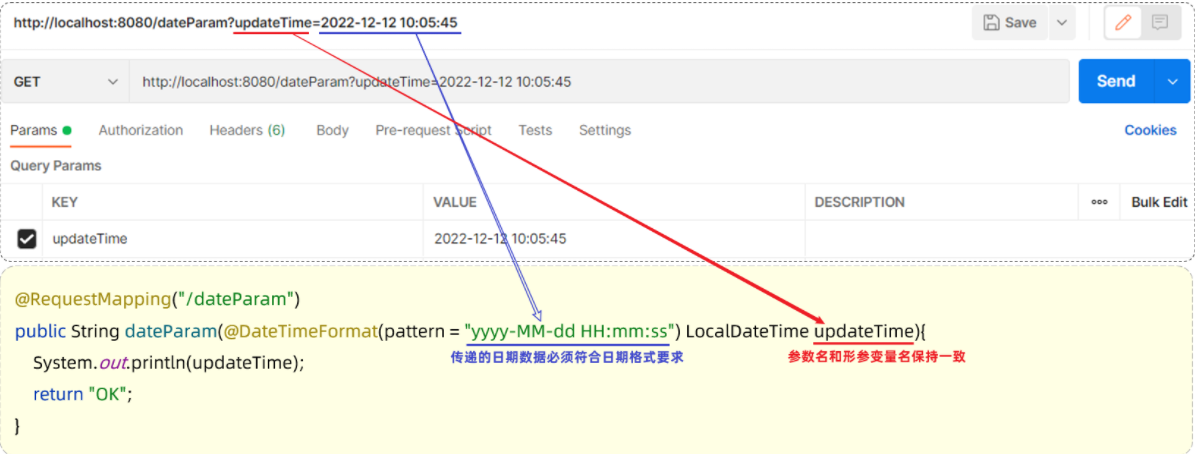
- @DateTimeFormat注解的pattern属性中指定了哪种日期格式,前端的日期参数就必须按照指定的格式传递。
- 后端controller方法中,需要使用Date类型或LocalDateTime类型,来封装传递的参数。
Controller方法:
1 |
|
Postman测试:

1.6 JSON参数
在学习前端技术时,我们有讲到过JSON,而在前后端进行交互时,如果是比较复杂的参数,前后端通过会使用JSON格式的数据进行传输。 (JSON是开发中最常用的前后端数据交互方式)
我们学习JSON格式参数,主要从以下两个方面着手:
- Postman在发送请求时,如何传递json格式的请求参数
- 在服务端的controller方法中,如何接收json格式的请求参数
Postman发送JSON格式数据:
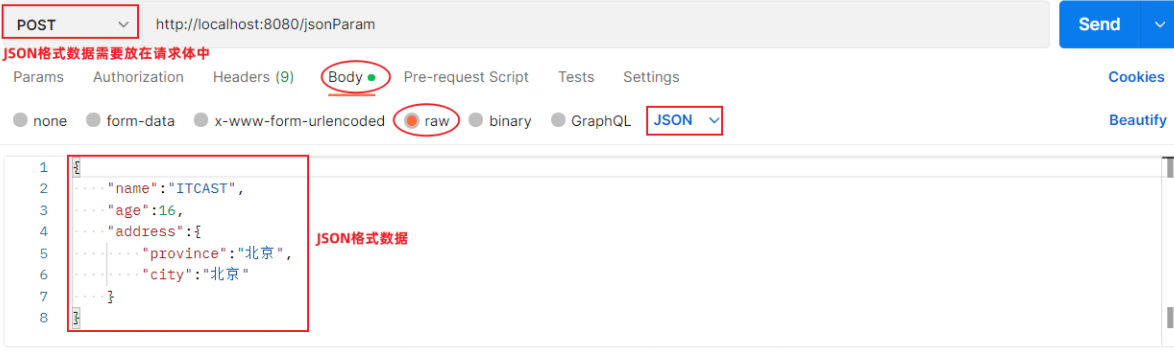
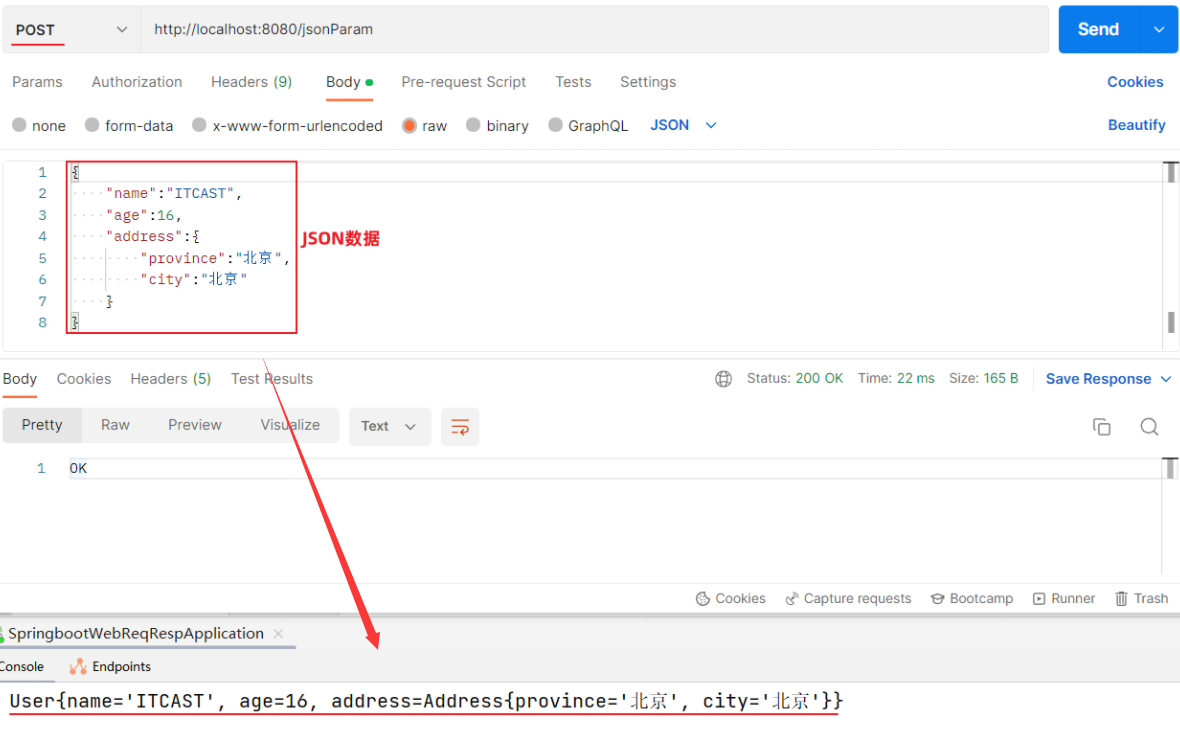
服务端Controller方法接收JSON格式数据:
传递json格式的参数,在Controller中会使用实体类进行封装。
封装规则:JSON数据键名与形参对象属性名相同,定义POJO类型形参即可接收参数。需要使用 @RequestBody标识。
 @RequestBody注解:将JSON数据映射到形参的实体类对象中(JSON中的key和实体类中的属性名保持一致)
@RequestBody注解:将JSON数据映射到形参的实体类对象中(JSON中的key和实体类中的属性名保持一致)
实体类:Address
1 | public class Address { |
实体类:User
1 | public class User { |
Controller方法:
1 |
|
Postman测试:
1.7 路径参数
传统的开发中请求参数是放在请求体(POST请求)传递或跟在URL后面通过?key=value的形式传递(GET请求)。
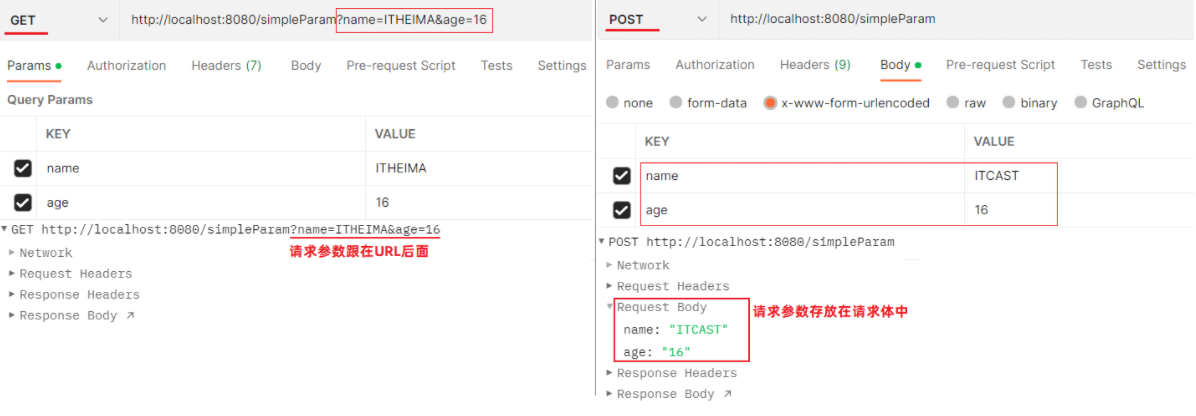
在现在的开发中,经常还会直接在请求的URL中传递参数。例如:
1 | http://localhost:8080/user/1 |
上述的这种传递请求参数的形式呢,我们称之为:路径参数。
学习路径参数呢,主要掌握在后端的controller方法中,如何接收路径参数。
路径参数:
- 前端:通过请求URL直接传递参数
- 后端:使用{…}来标识该路径参数,需要使用@PathVariable获取路径参数
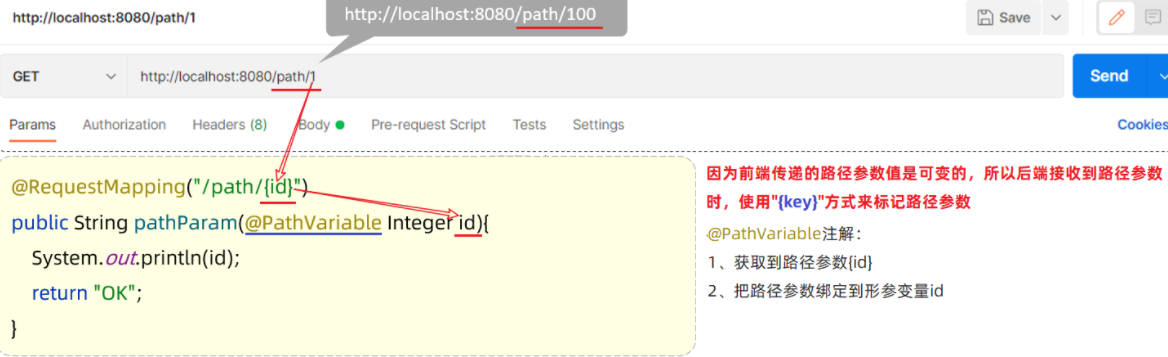
Controller方法:
1 |
|
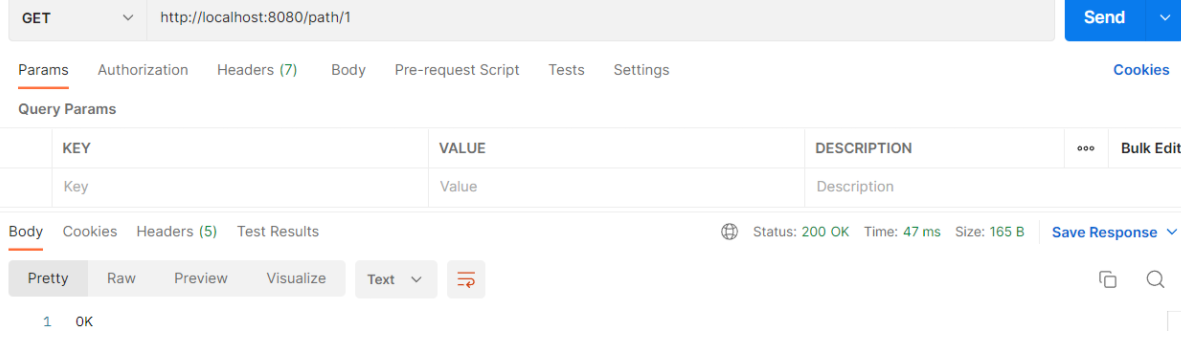
Postman测试:
传递多个路径参数:
Postman:
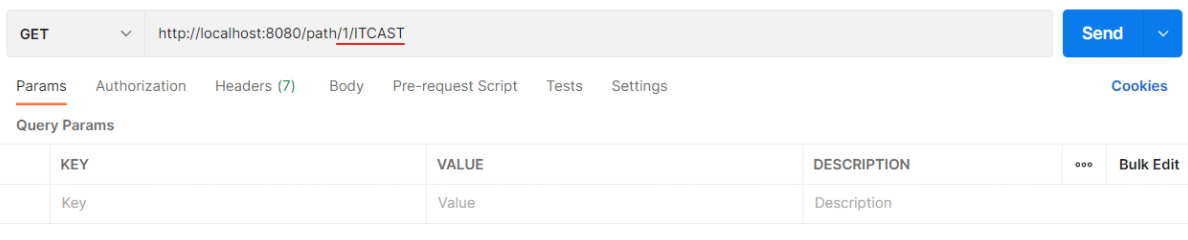
Controller方法:
1 |
|
2. 响应
前面我们学习过HTTL协议的交互方式:请求响应模式(有请求就有响应)
那么Controller程序呢,除了接收请求外,还可以进行响应。
2.1 @ResponseBody
在我们前面所编写的controller方法中,都已经设置了响应数据。

controller方法中的return的结果,怎么就可以响应给浏览器呢?
答案:使用@ResponseBody注解
@ResponseBody注解:
- 类型:方法注解、类注解
- 位置:书写在Controller方法上或类上
- 作用:将方法返回值直接响应给浏览器
- 如果返回值类型是实体对象/集合,将会转换为JSON格式后在响应给浏览器
但是在我们所书写的Controller中,只在类上添加了@RestController注解、方法添加了@RequestMapping注解,并没有使用@ResponseBody注解,怎么给浏览器响应呢?
1 |
|
原因:在类上添加的@RestController注解,是一个组合注解。
- @RestController = @Controller + @ResponseBody
@RestController源码:
1 | ({ElementType.TYPE}) //元注解(修饰注解的注解) |
结论:在类上添加@RestController就相当于添加了@ResponseBody注解。
- 类上有@RestController注解或@ResponseBody注解时:表示当前类下所有的方法返回值做为响应数据
- 方法的返回值,如果是一个POJO对象或集合时,会先转换为JSON格式,在响应给浏览器
下面我们来测试下响应数据:
1 |
|
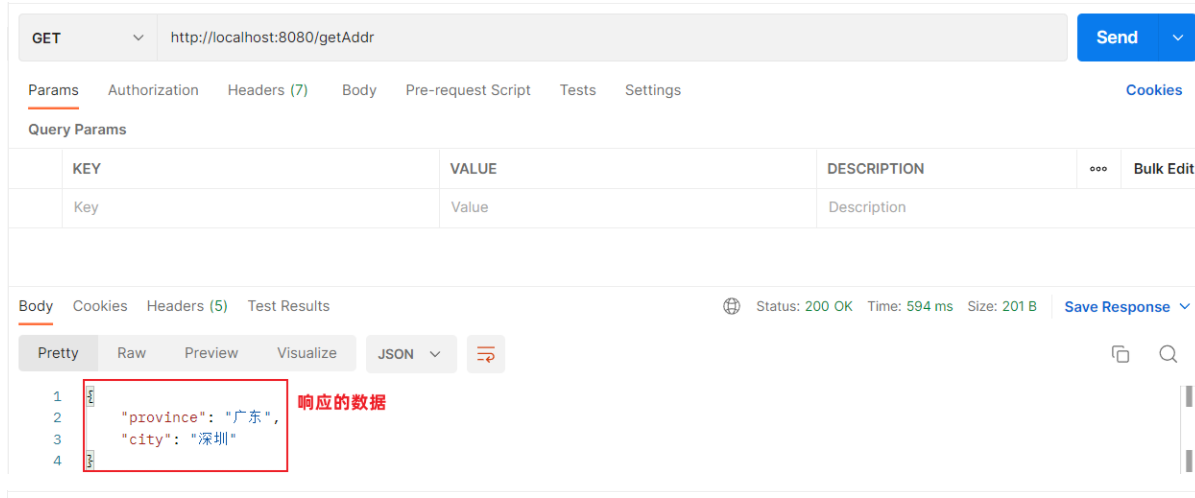
在服务端响应了一个对象或者集合,那私前端获取到的数据是什么样子的呢?我们使用postman发送请求来测试下。测试效果如下:

2.2 统一响应结果
大家有没有发现一个问题,我们在前面所编写的这些Controller方法中,返回值各种各样,没有任何的规范。

如果我们开发一个大型项目,项目中controller方法将成千上万,使用上述方式将造成整个项目难以维护。那在真实的项目开发中是什么样子的呢?
在真实的项目开发中,无论是哪种方法,我们都会定义一个统一的返回结果。方案如下:
前端:只需要按照统一格式的返回结果进行解析(仅一种解析方案),就可以拿到数据。
统一的返回结果使用类来描述,在这个结果中包含:
响应状态码:当前请求是成功,还是失败
状态码信息:给页面的提示信息
返回的数据:给前端响应的数据(字符串、对象、集合)
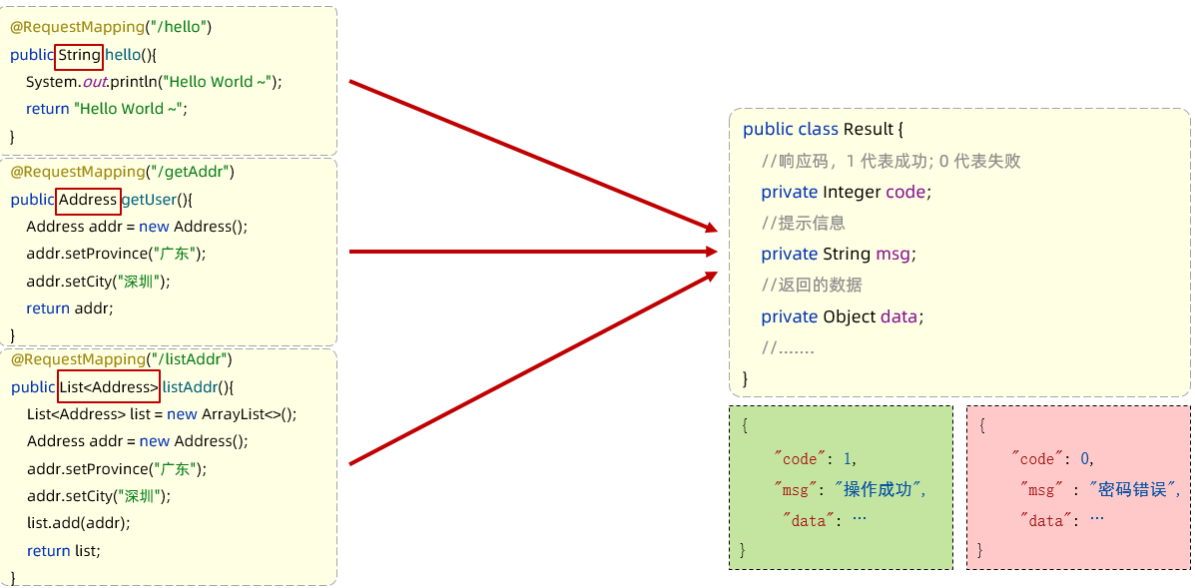
定义在一个实体类Result来包含以上信息。代码如下:
1 | public class Result { |
改造Controller:
1 |
|
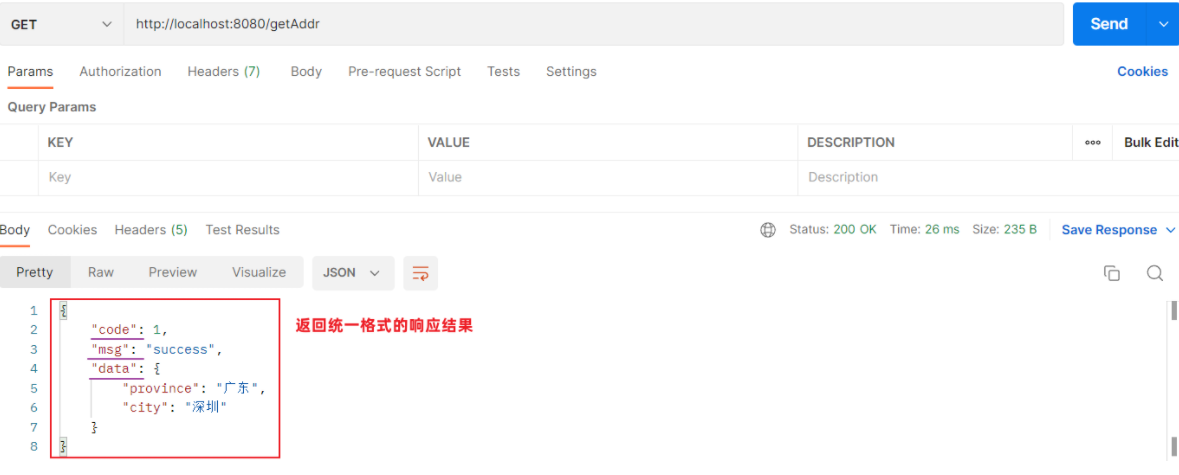
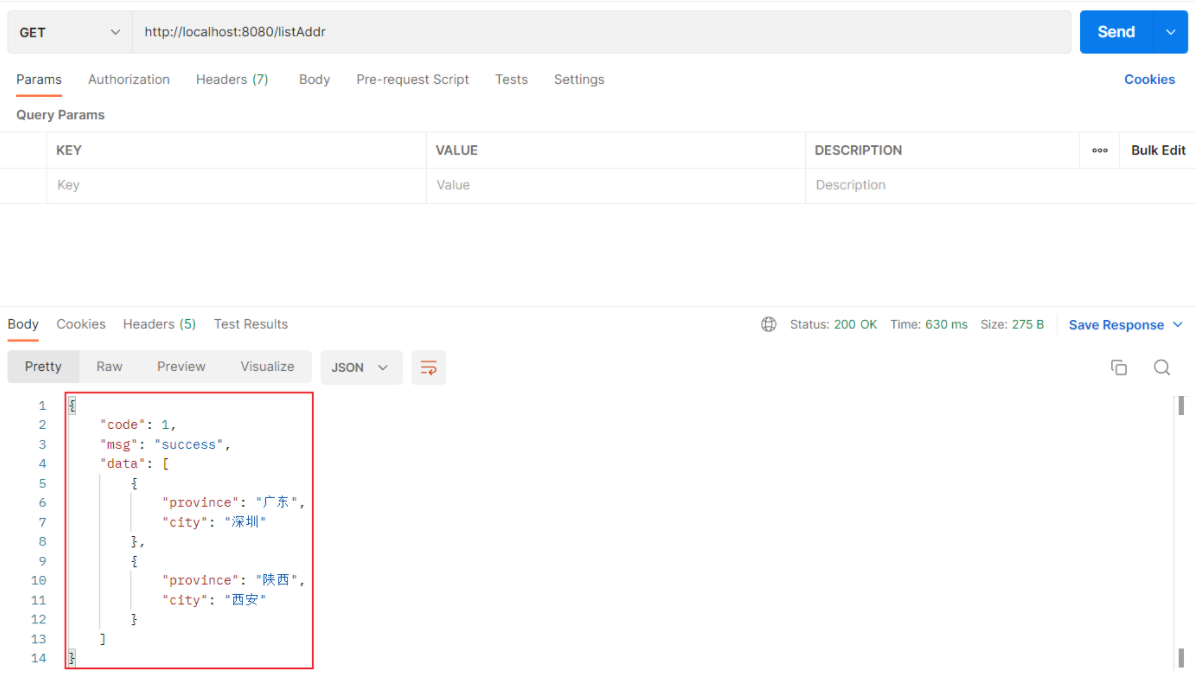
使用Postman测试:
3. 分层解耦
3.1 三层架构
3.1.1 介绍
在我们进行程序设计以及程序开发时,尽可能让每一个接口、类、方法的职责更单一些(单一职责原则)。
单一职责原则:一个类或一个方法,就只做一件事情,只管一块功能。
这样就可以让类、接口、方法的复杂度更低,可读性更强,扩展性更好,也更利用后期的维护。
我们之前开发的程序呢,并不满足单一职责原则。下面我们来分析下之前的程序:

那其实我们上述案例的处理逻辑呢,从组成上看可以分为三个部分:
- 数据访问:负责业务数据的维护操作,包括增、删、改、查等操作。
- 逻辑处理:负责业务逻辑处理的代码。
- 请求处理、响应数据:负责,接收页面的请求,给页面响应数据。
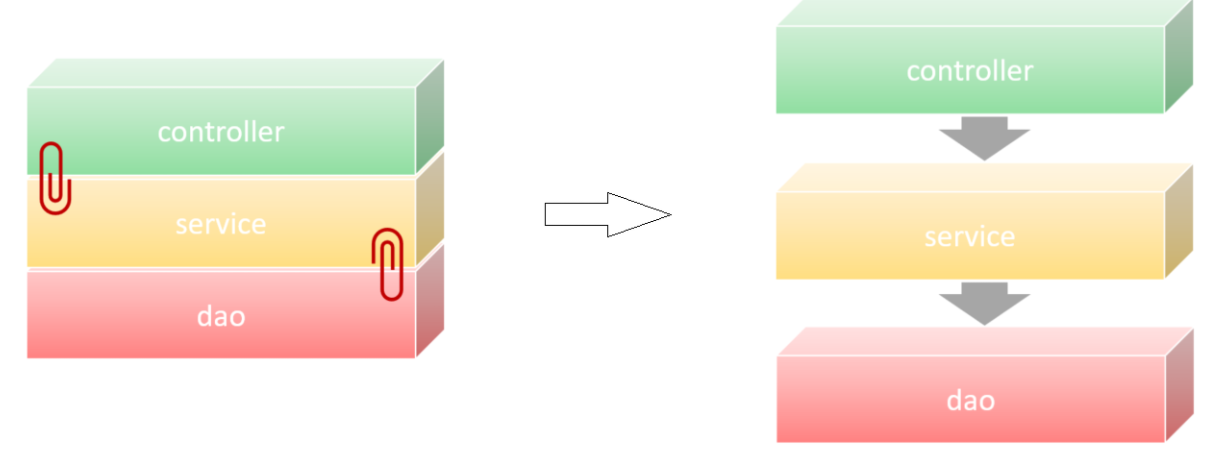
按照上述的三个组成部分,在我们项目开发中呢,可以将代码分为三层:

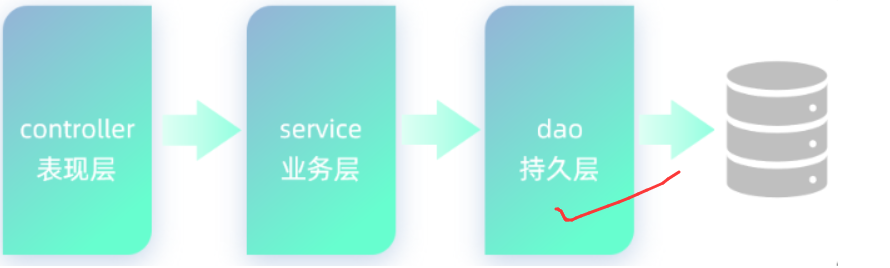
- Controller:控制层。接收前端发送的请求,对请求进行处理,并响应数据。
- Service:业务逻辑层。处理具体的业务逻辑。
- Dao:数据访问层(Data Access Object),也称为持久层。负责数据访问操作,包括数据的增、删、改、查。
基于三层架构的程序执行流程:
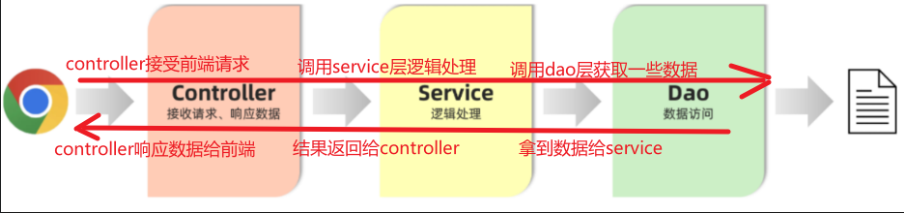
- 前端发起的请求,由Controller层接收(Controller响应数据给前端)
- Controller层调用Service层来进行逻辑处理(Service层处理完后,把处理结果返回给Controller层)
- Serivce层调用Dao层(逻辑处理过程中需要用到的一些数据要从Dao层获取)
- Dao层操作文件中的数据(Dao拿到的数据会返回给Service层)
思考:按照三层架构的思想,如何要对业务逻辑(Service层)进行变更,会影响到Controller层和Dao层吗?
答案:不会影响。 (程序的扩展性、维护性变得更好了)
3.1.2 代码拆分
我们使用三层架构思想,来改造下之前的程序:
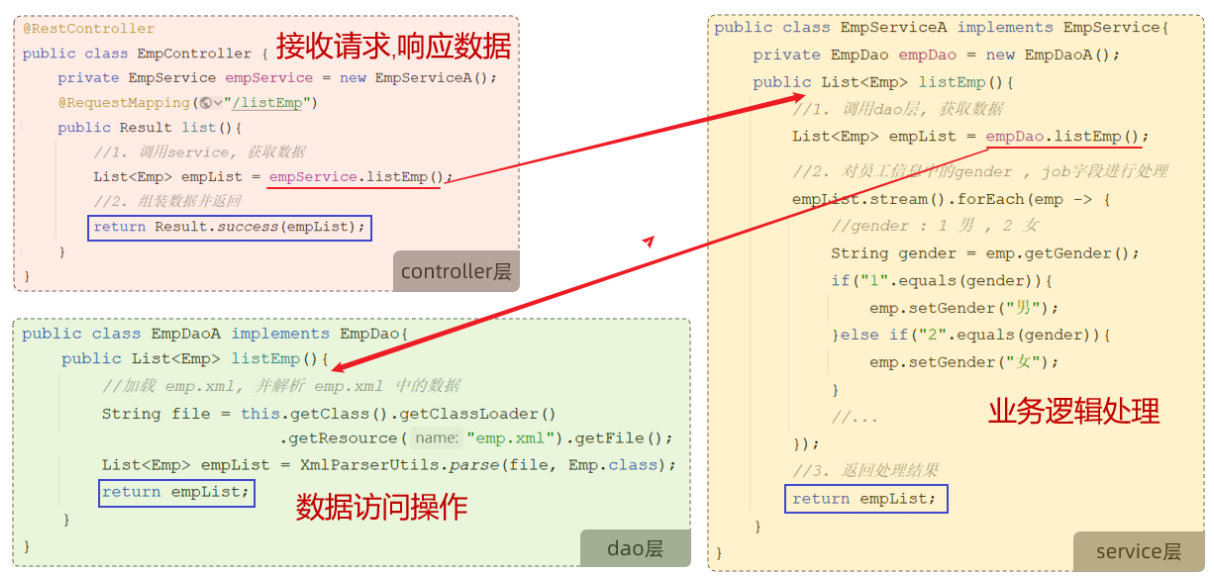
三层架构的好处:
- 复用性强
- 便于维护
- 利用扩展
3.2 分层解耦
刚才我们学习过程序分层思想了,接下来呢,我们来学习下程序的解耦思想。
解耦:解除耦合。
3.2.1 耦合问题
首先需要了解软件开发涉及到的两个概念:内聚和耦合。
内聚:软件中各个功能模块内部的功能联系。
耦合:衡量软件中各个层/模块之间的依赖、关联的程度。
软件设计原则:高内聚低耦合。
高内聚指的是:一个模块中各个元素之间的联系的紧密程度,如果各个元素(语句、程序段)之间的联系程度越高,则内聚性越高,即 “高内聚”。
低耦合指的是:软件中各个层、模块之间的依赖关联程序越低越好。
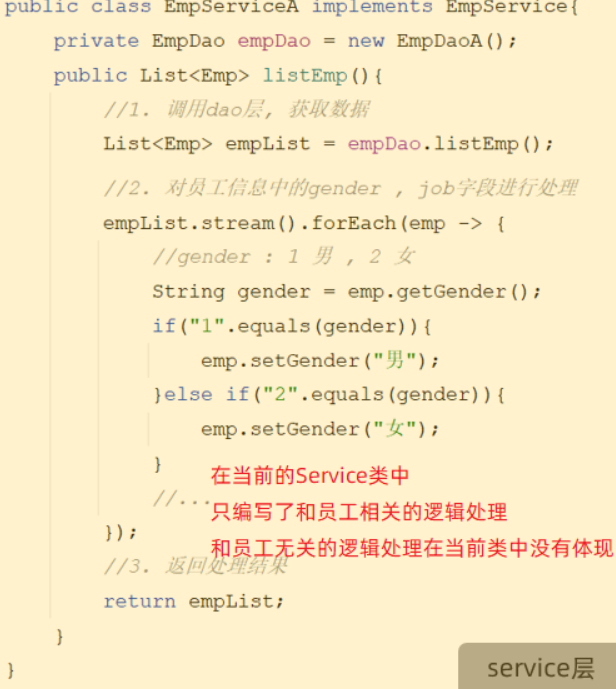
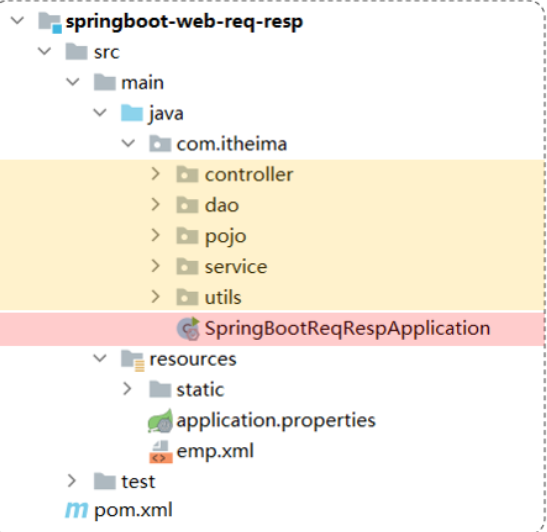
程序中高内聚的体现:
- EmpServiceA类中只编写了和员工相关的逻辑处理代码
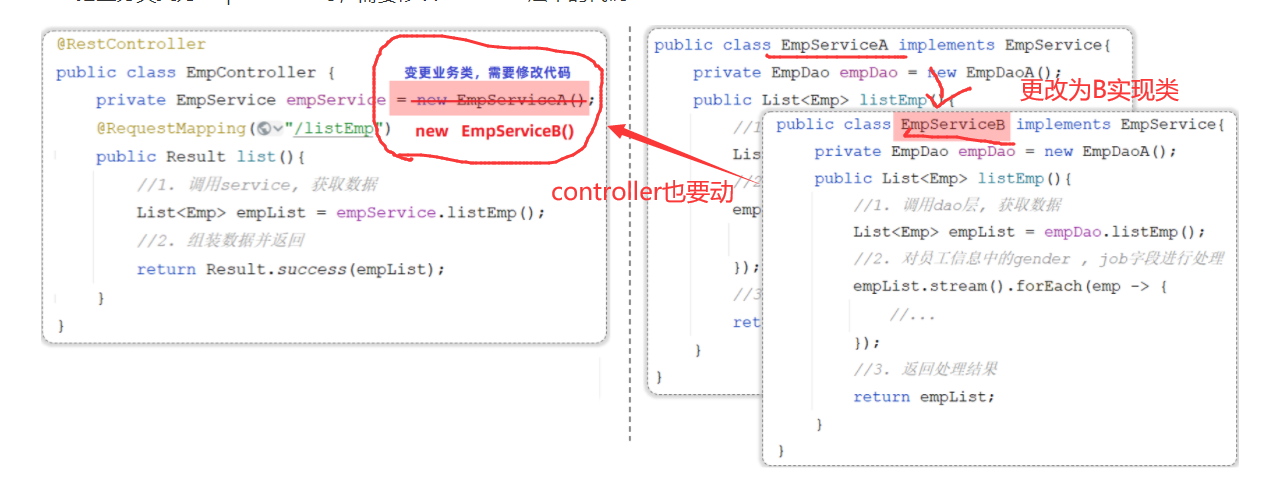
程序中耦合代码的体现:
- 把业务类变为EmpServiceB时,需要修改controller层中的代码
高内聚、低耦合的目的是使程序模块的可重用性、移植性大大增强。
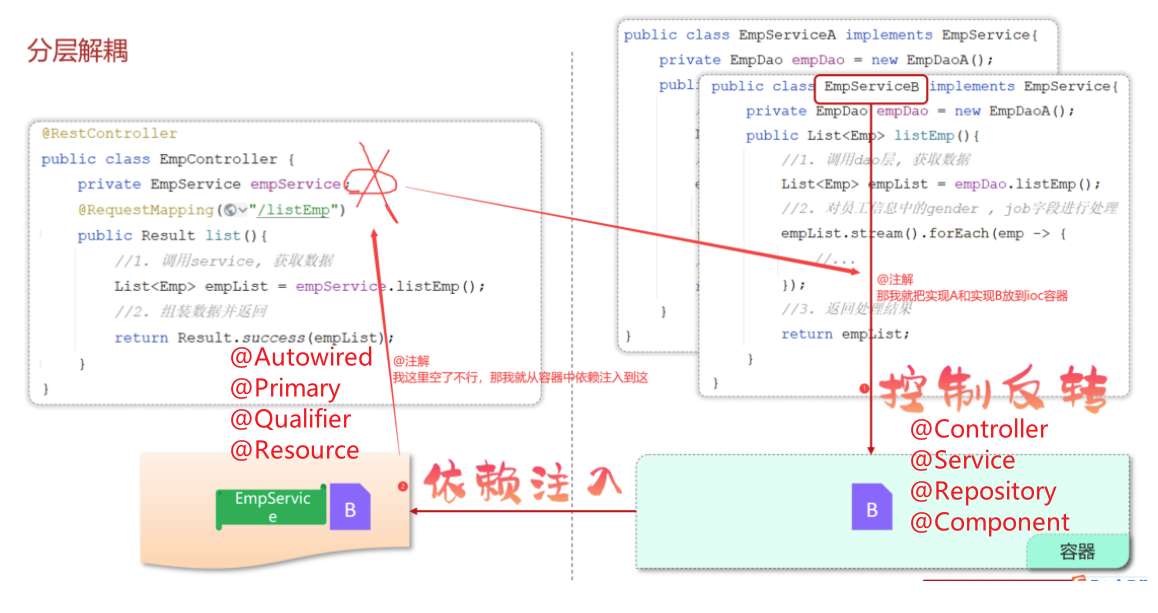
3.2.2 解耦思路(控制反转和依赖注入的原因)
之前我们在编写代码时,需要什么对象,就直接new一个就可以了。 这种做法呢,层与层之间代码就耦合了,当service层的实现变了之后, 我们还需要修改controller层的代码。

那应该怎么解耦呢?
- 不能new,就意味着没有业务层对象(程序运行就报错),怎么办呢?
- 我们的解决思路是:
- 提供一个容器,容器中存储一些对象(例:EmpService对象)
- controller程序从容器中获取EmpService类型的对象
- 我们的解决思路是:
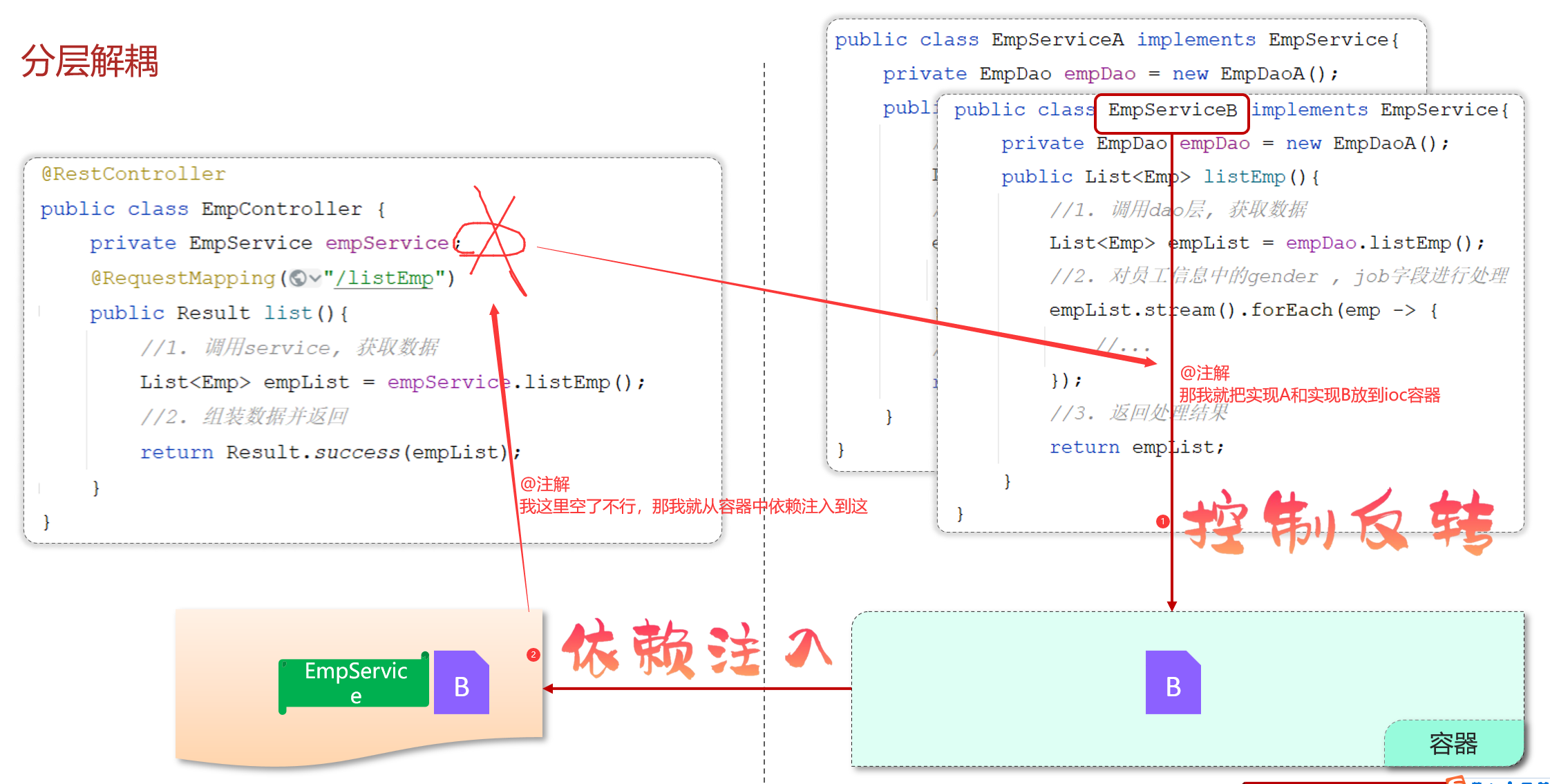
我们想要实现上述解耦操作,就涉及到Spring中的两个核心概念:
控制反转: Inversion Of Control,简称IOC。对象的创建控制权由程序自身转移到外部(容器),这种思想称为控制反转。
对象的创建权由程序员主动创建转移到容器(由容器创建、管理对象)。这个容器称为:IOC容器或Spring容器
依赖注入: Dependency Injection,简称DI。容器为应用程序提供运行时,所依赖的资源,称之为依赖注入。
程序运行时需要某个资源,此时容器就为其提供这个资源。
例:EmpController程序运行时需要EmpService对象,Spring容器就为其提供并注入EmpService对象
IOC容器中创建、管理的对象,称之为:bean对象
4. IOC控制依赖和DI依赖注入
上面我们引出了Spring中IOC和DI的基本概念,下面我们就来具体学习下IOC和DI的代码实现。
4.1 IOC&DI基本步骤
任务:完成Controller层、Service层、Dao层的代码解耦
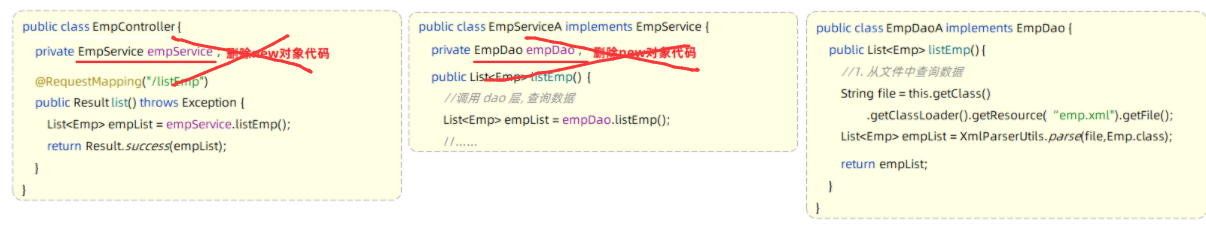
- 思路:
- 删除Controller层、Service层中new对象的代码
- Service层及Dao层的实现类,交给IOC容器管理
- 为Controller及Service注入运行时依赖的对象
- Controller程序中注入依赖的Service层对象
- Service程序中注入依赖的Dao层对象
第1步:删除Controller层、Service层中new对象的代码
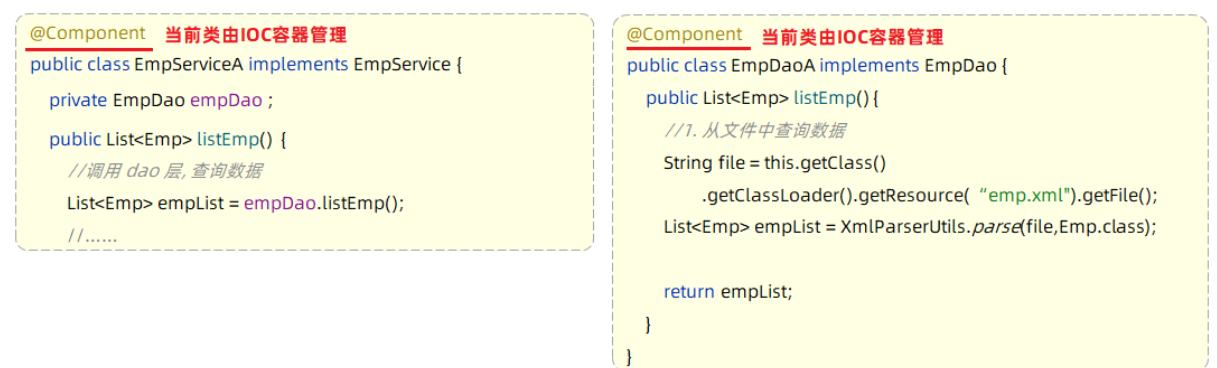
第2步:Service层及Dao层的实现类,交给IOC容器管理
- 使用Spring提供的注解:@Component,就可以实现类交给IOC容器管理
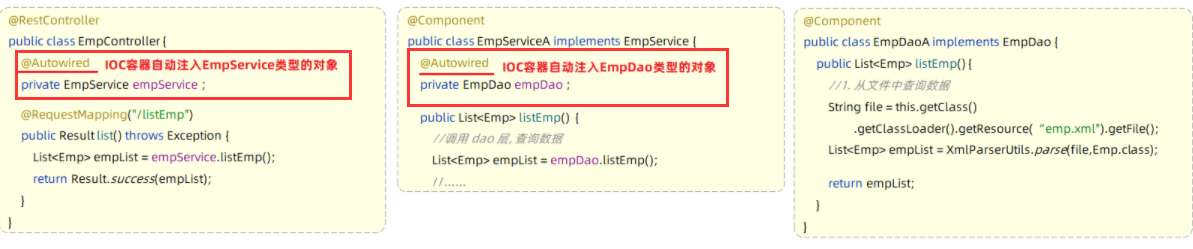
第3步:为Controller及Service注入运行时依赖的对象
- 使用Spring提供的注解:@Autowired ,就可以实现程序运行时IOC容器自动注入需要的依赖对象
4.2 IOC详解
4.2.1 bean的声明(每个层一个注解)
前面我们提到IOC控制反转,就是将对象的控制权交给Spring的IOC容器,由IOC容器创建及管理对象。IOC容器创建的对象称为bean对象。
在之前的入门案例中,要把某个对象交给IOC容器管理,需要在类上添加一个注解:@Component
而Spring框架为了更好的标识web应用程序开发当中,bean对象到底归属于哪一层,又提供了@Component的衍生注解:
@Controller (标注在控制层类上)
@Service (标注在业务层类上)
@Repository (标注在数据访问层类上)
要把某个对象交给IOC容器管理,需要在对应的类上加上如下注解之一:
| 注解 | 说明 | 位置 |
|---|---|---|
| @Controller | @Component的衍生注解 | 标注在控制器类上 |
| @Service | @Component的衍生注解 | 标注在业务类上 |
| @Repository | @Component的衍生注解 | 标注在数据访问类上(由于与mybatis整合 –mybatis用的@Mapper) |
| @Component | 声明bean的基础注解 | 不清楚属于哪一个层上就用这个 |

在IOC容器中,每一个Bean都有一个属于自己的名字,可以通过注解的value属性指定bean的名字。如果没有指定,默认为类名首字母小写。
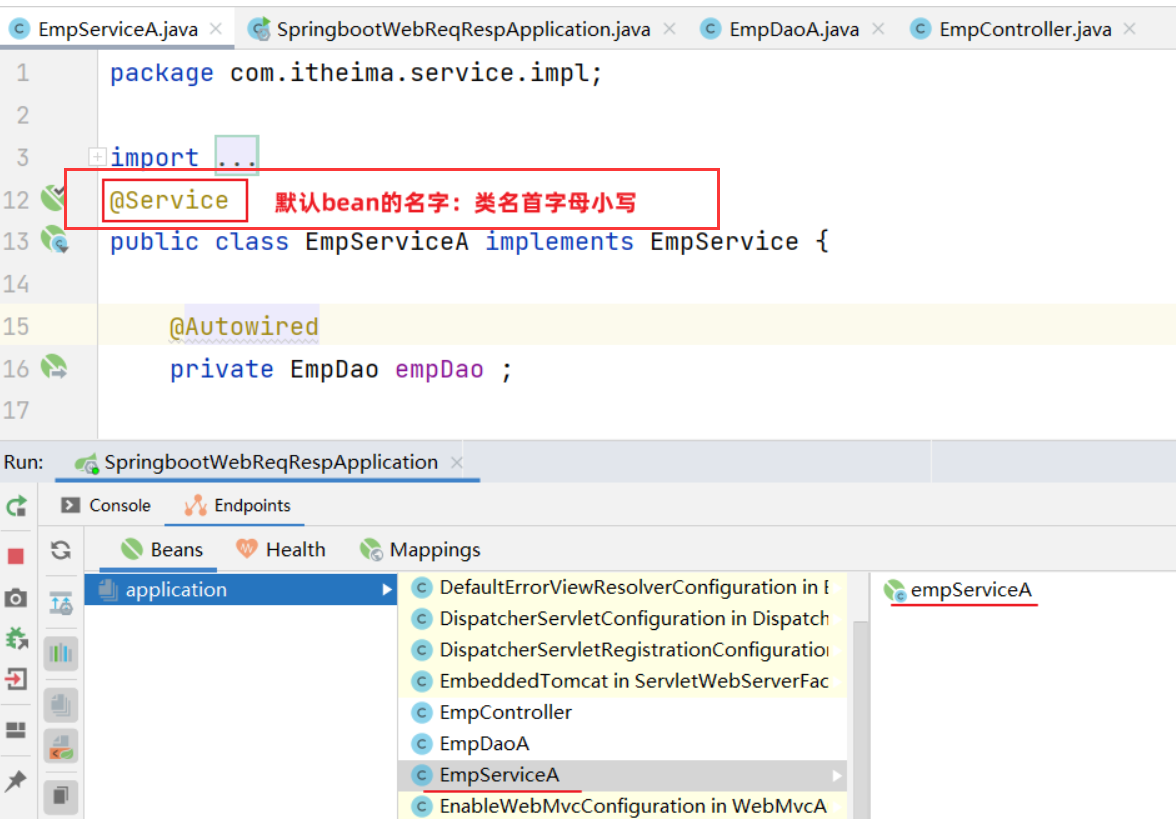
注意事项:
- 声明bean的时候,可以通过value属性指定bean的名字,如果没有指定,默认为类名首字母小写。
- 使用以上四个注解都可以声明bean,但是在springboot集成web开发中,声明控制器bean只能用@Controller。
4.2.2 组件扫描
问题:使用前面学习的四个注解声明的bean,一定会生效吗?
答案:不一定。(原因:bean想要生效,还需要被组件扫描)
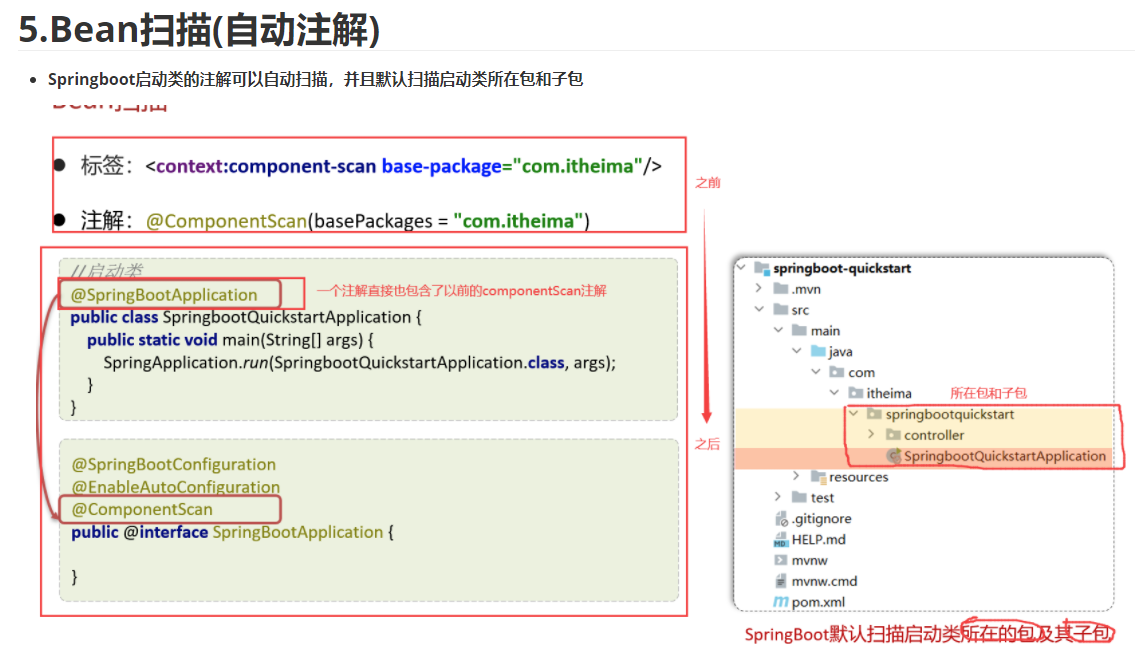
推荐做法(如下图):
- 将我们定义的controller,service,dao这些包呢,都放在引导类所在包com.itheima的子包下,这样我们定义的bean就会被自动的扫描到
4.3 DI详解(4种依赖注入)
依赖注入,是指IOC容器要为应用程序去提供运行时所依赖的资源,而资源指的就是对象。
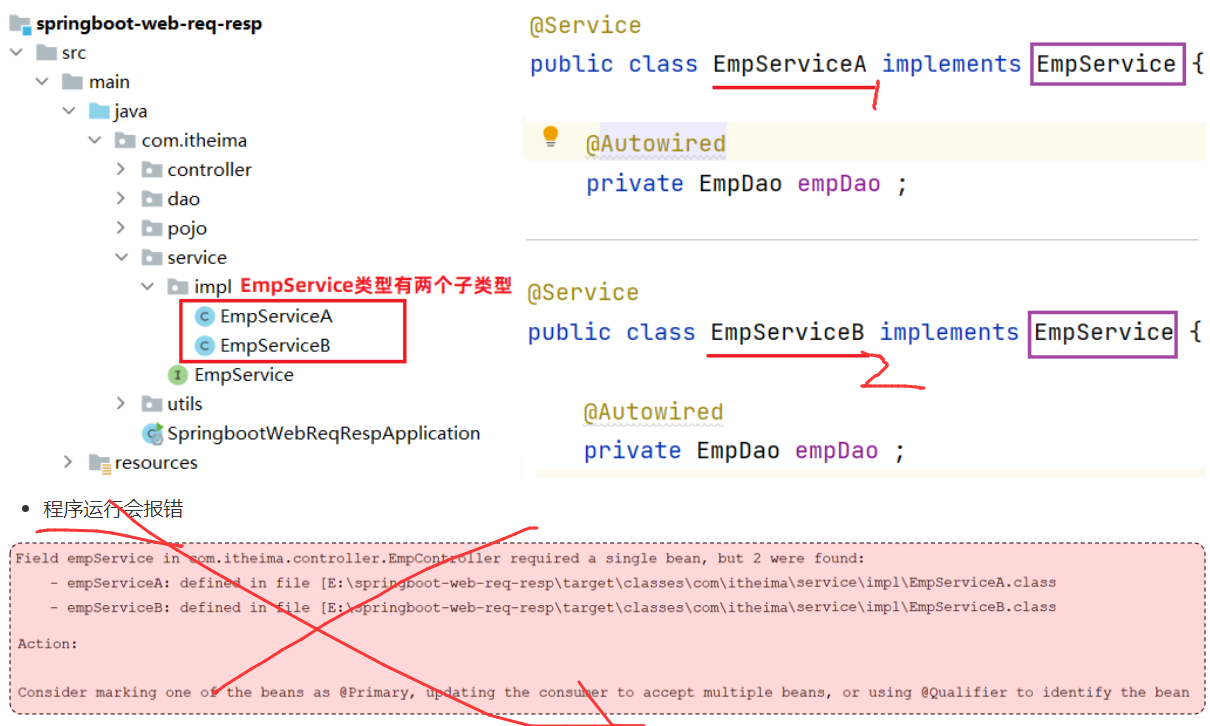
4.3.1 @Autowired注解
默认是按照类型进行自动装配的(去IOC容器中找某个类型的对象,然后完成注入操作) –如果有多个相同类型的就会报错,就要用其他三种注解解决
4.3.2 @Primary注解(在相同类型的类上单独加优先级)
使用@Primary注解:当存在多个相同类型的Bean注入时,加上@Primary注解,来确定默认的实现。

4.3.3 @Qualifier注解 (在出错位置配合Autowired注解看用哪个)
使用@Qualifier注解:指定当前要注入的bean对象。 在@Qualifier的value属性中,指定注入的bean的名称。
- @Qualifier注解不能单独使用,必须配合@Autowired使用
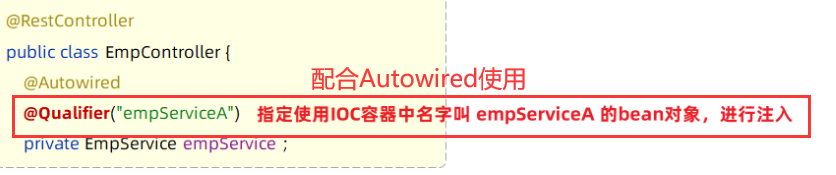
4.3.4 @Resource注解(和Autowired同一位置,但是是按照名称注入)
使用@Resource注解:是按照bean的名称进行注入。通过name属性指定要注入的bean的名称。

4.3.4 面试题和总结
面试题 : @Autowird 与 @Resource的区别
- @Autowired 是spring框架提供的注解,而@Resource是JDK提供的注解
- @Autowired 默认是按照类型注入,而@Resource是按照名称注入
- @Autowired 如果出现多个类型相同的话会出现异常(所以用其他三种注解解决)
- 总结

4.4 控制依赖和依赖注入总体图
图解HTTP
1.基础概念
1.1 客户端和服务端
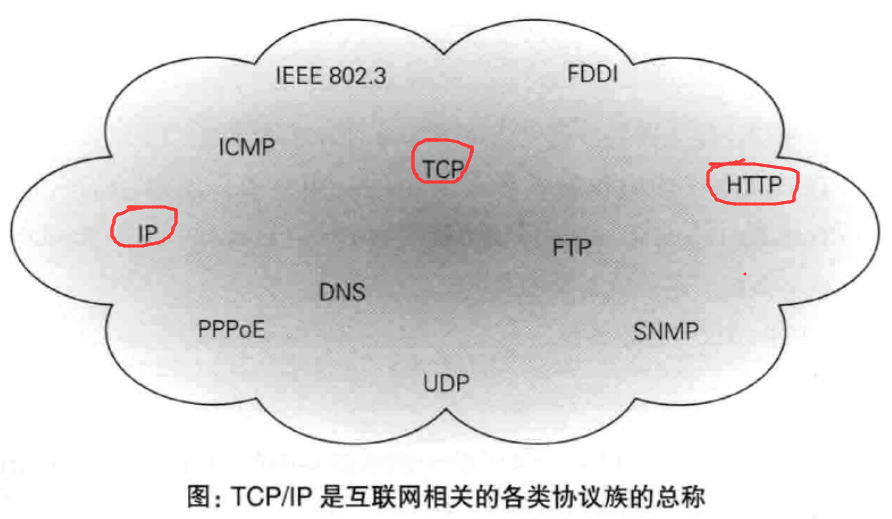
1.2 TCP/IP协议族
1.2.1 定义
- 定义
1 | 第一种:TCP和IP协议 |
1.2.2 网络协议
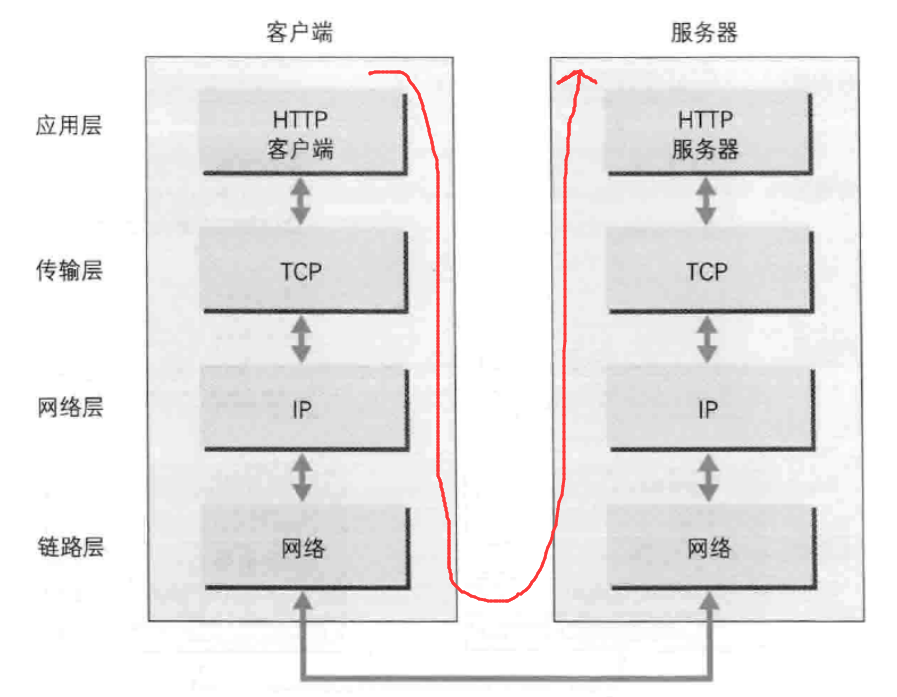
| 层名 | 传输的数据 | 作用 | 协议 |
|---|---|---|---|
| 应用层 | 报文 | 为特定应用程序提供数据传输服务 | FTP(文件传输协议) DNS(域名系统) HTTP(超文本传输协议) DHCP(动态主机配置协议) TELNET(远程登录协议) SMTP() POP3() IMAP() |
| 传输层 | TCP报文段 UDP用户数据包 |
为进程提供通用数据传输服务 | TCP(传输控制协议) UDP(用户数据报协议) |
| 网络层 | IP数据包 | 为主机提供数据传输服务 | IP(网络互连协议) ARP(地址解析协议) ICMP(网际控制报文协议) IGMP(网际组管理协议) |
| 数据链路层 | 数据帧 | 为同一链路的主机提供数据传输服务 | PPP协议 |
1.2.3 网络层-IP协议
1.作用:将各种数据包传送给对方
2.两个重要条件:①IP地址:指明了节点被分配到的地址(与MAC地址进行配对,可变) ②MAC地址:指网卡所属的固定地址(基本不变)
1.2.4 传输层-TCP协议
1.2.4.1 三次握手
1.2.5 应用层-DNS域名解析
1.2.6 各层协议之间关系
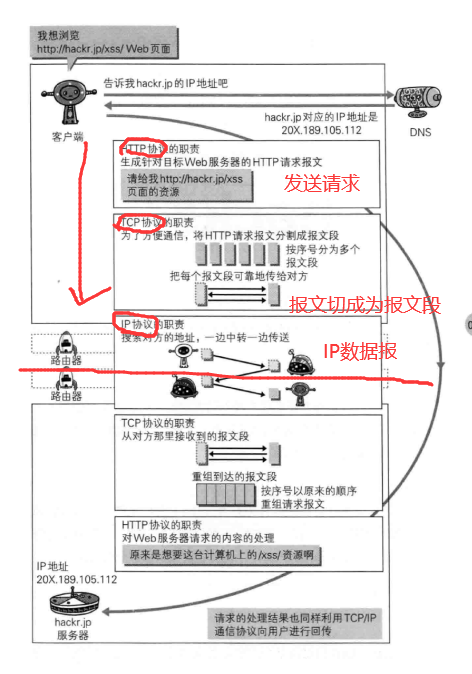
1.2.7 URL和URI
1.2.7.1 URL(统一资源定位符) —表示资源的地点
- RFC3986:
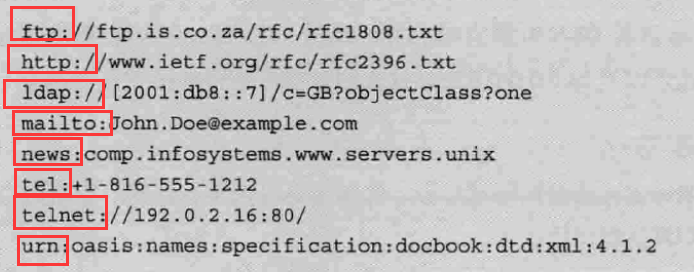
1.2.7.2 URI(统一资源标识符) —标识某一互联网资源

1.3 HTTP请求报文和响应报文
1.3.1 HTTP请求报文
1.3.2 HTTP响应报文
JAVA-数据结构与算法
1.数据结构与算法
1.1 数据结构的定义
1 | 数据结构=数据+算法 |
1.1.1 数据与信息
数据:指的是一种未处理的原始文字,数字,符号、图形
信息:当数据 –处理【算法+数据结构】–> (特定的方式系统地处理、归纳甚至进行分析)
1.1.2 数据的分类
- 1.按照计算机中所存储和使用的对象:
1.1 数值数据: 如0,1,2…,9所组成,可用运算符来进行运算的数据
1.2 字符数据: 如A,B,C,…,+,*等非数值型数据
- 2.按照数据在计算机程序设计语言中的存在层次:
2.1 **基本数据类型/标量数据类型**: 不能以其他类型来定义的数据类型。【Java中所有基本数据类型】
2.2 **结构数据类型/虚拟数据类型**: 【字符串,数组,指针,列表,文件等】
2.3 **抽象数据类型**: 可以将一种数据类型看成是一种值的集合,以及在这些值上所进行的运算和其所代表的属性所成的集合【堆栈等】1.2 算法
1 | 可执行程序=数据结构+算法【最关键的因素】 |
1.2.1 算法的定义
1 | 为了解决某项工作/某个问题,所需要有限数量的机械性/重复性指令与计算步骤 |
算法的五个条件:
算法的特性 内容与说明 输入 0-n个输入,这些输入必须有清楚的描述或定义 输出 1-n个输出【至少有一个输出结果】 明确性 每个指令/步骤必须是简洁明确的 有限性 在有限步骤后一定会结束【不存在无限循环】 有效性 步骤清楚+可行【能让用户】 算法的分类:
描述工具 具体描述 举例 伪语言 不能直接放入计算机执行的语言,一般需要一种特定的预处理器/人工编写转换成真正的计算机语言 sparks,pascal-like 表格/图形 清晰明了的描述过程 数组,树形图,矩阵图 流程图 图形符号表示法 流程图 程序设计语言 可读性高的高级语言 Java,python,c#
1.3 算法性能分析
1.3.1 时间复杂度
1 | 1.一种以概量方式来衡量运行时间 |
1.3.2 空间复杂度
1 | 1.一种以概量方式来衡量所需的内存空间 |
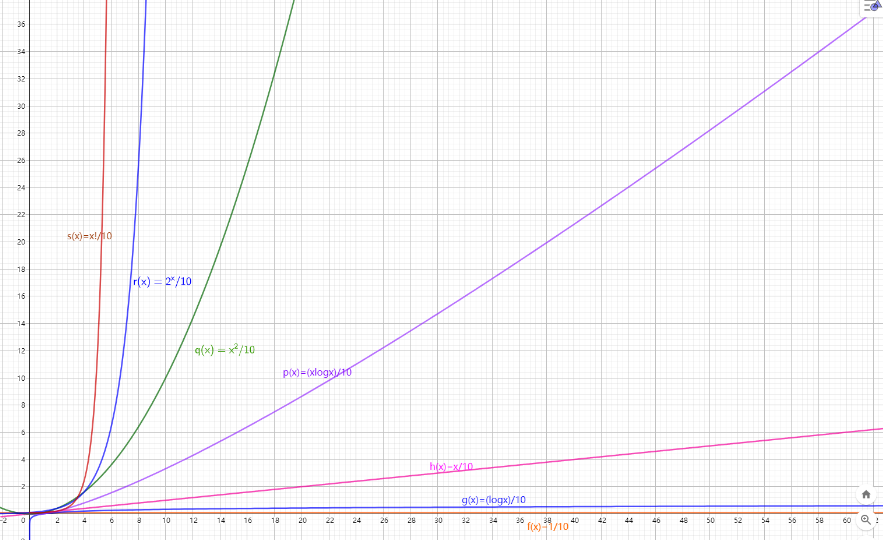
1.3.3 Big-oh(衡量时间复杂度)
1 | 常见的算法时间复杂度: |
1.4 常见算法
1.4.1 分治法
1.4.2 递归法
1.4.3 贪心法
1.4.4 动态规划法
1.4.5 迭代法
1.4.6 枚举法
1.5程序设计简介
1.5.1 程序开发流程
四项原则
1
2
3
41.可读性高:阅读和理解都相当容易
2.平均成本低:成本考虑不局限于编码的成本,还包括执行,编译,维护,学习,调试和日后更新等成本
3.可靠性高:所编写出来的程序代码稳定性高,不容易出现边际错误
4.可编写性高:对于针对需求所编写的程序相对于容易
2.数组结构
2.1 线性表
- 线性表的定义:
有序表可以是空集合/(a1,a2,a3,….an-1,an),存在唯一的第一个元素a1和存在唯一的最后一个元素an。除了最后一个元素都有后继者,除了第一个元素都有先行者。
- 线性表的运算:
1.计算线性表的长度n
2.取出线性表中的第i项元素来修改 3.插入一个新元素到第i项,并将原来位置和后面元素都后移
4.删除第i项元素
5.遍历读取线性表元素
6.替换第i项元素 7.复制线性表
8.合并线性表
- 线性表的存储方式:
| 静态数据结构 | 动态数据结构 | |
|---|---|---|
| 形式 | 密集表 | 链表 |
| 优点 | 使用连续分配的内存空间来存储有序表元素 设计简单,读取和修改表中任意元素时间固定O(1) |
使用不连续的内存空间来存储 数据插入和删除都方便O(1) O(n)内存分配是在程序执行时才分配,不需要事先声明,充分节省内存 |
| 缺点 | 删除和加入数据,需要挪动大量数据O(n) | 不能随机读取,必须按顺序遍历找到数据O(n) |
2.2 数组
2.2.1 一维数组

2.2.2 二维数组

2.3 矩阵
3.链表
- 许多相同数据类型的数据项,按照特定顺序排列而成的线性表(2.1定义的)
3.1 动态分配内存
| 对比项目 | 动态配置 | 静态分配 |
|---|---|---|
| 内存分配 | 运行阶段 | 编译阶段 |
| 内存释放 | 程序结束前必须释放分配的内存空间,否则会内存”泄露” | 不需要释放,程序结束时自动归还给系统 |
| 程序运行性能 | 比较低(因为所需内存要执行程序时候才分配) | 比较高(程序编译阶段就分配好需要的内存容量) |
| 指针遗失 | 可能会存在内存泄露(程序结束前不释放内存就指向新的内存空间,则原本指向的内存空间就无法被释放) | 没有此问题 |
3.2 单向链表
3.2.1 单链表定义
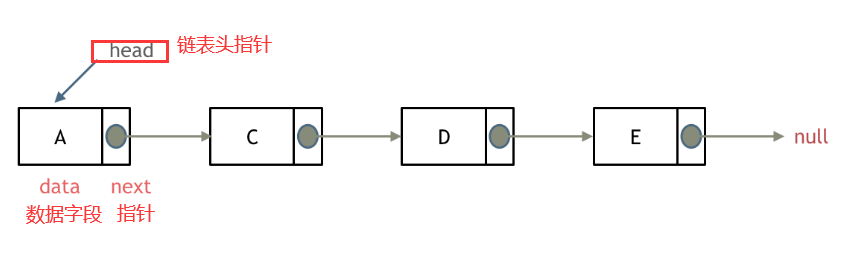
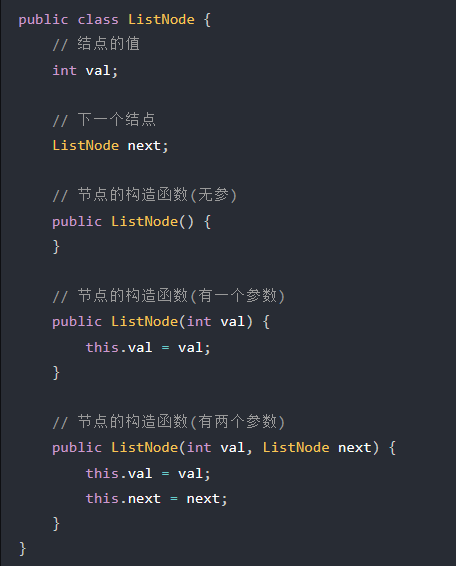
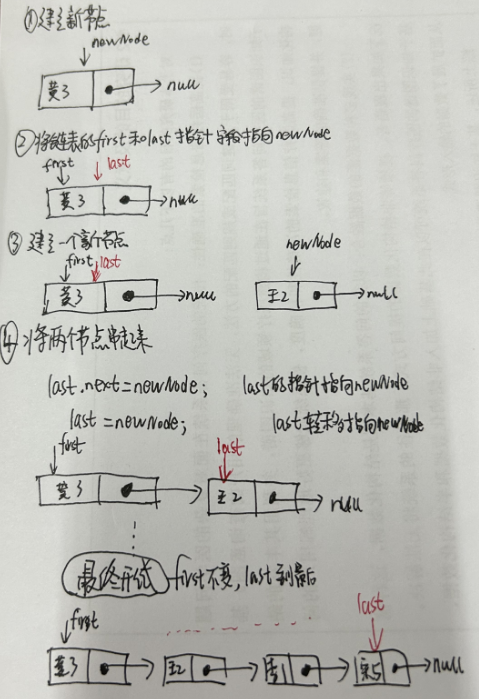
3.2.2 建立单链表
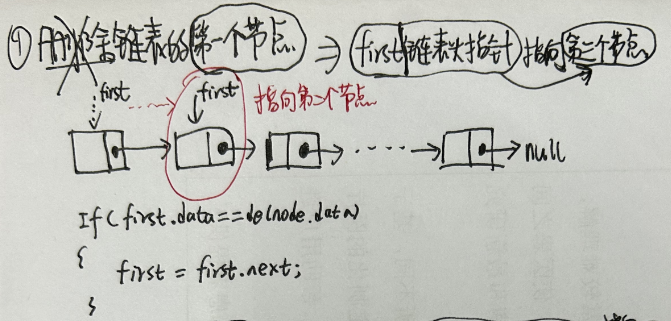
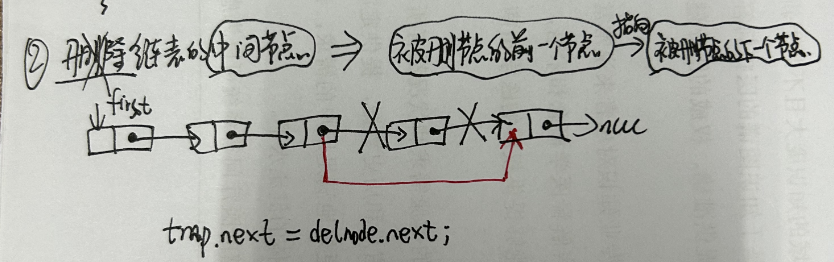
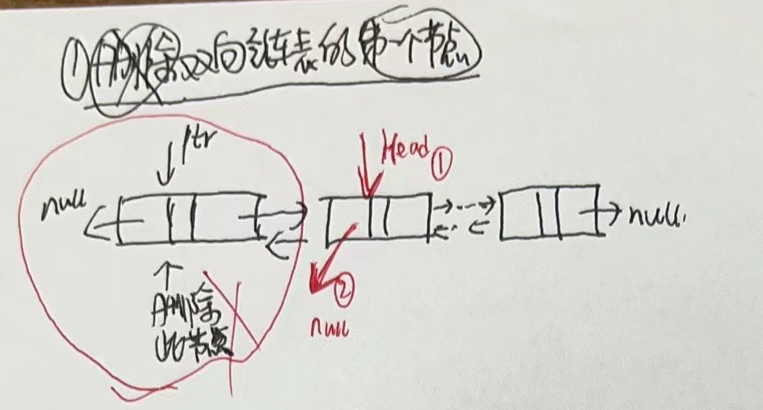
3.2.3 单链表删除节点
- 1.删除链表的第一个节点
- 2.删除链表的中间节点
- 3.删除链表的最后一个节点
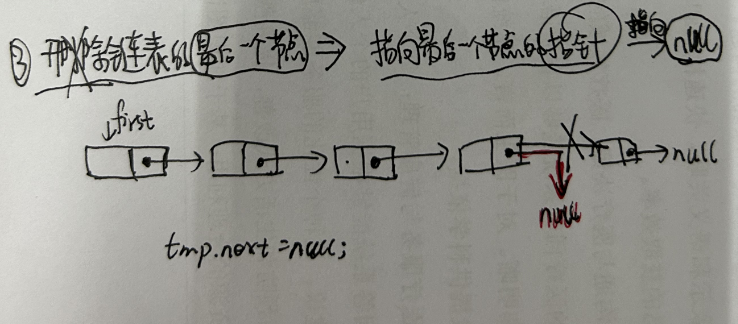
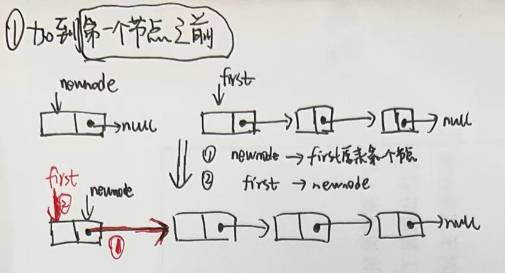
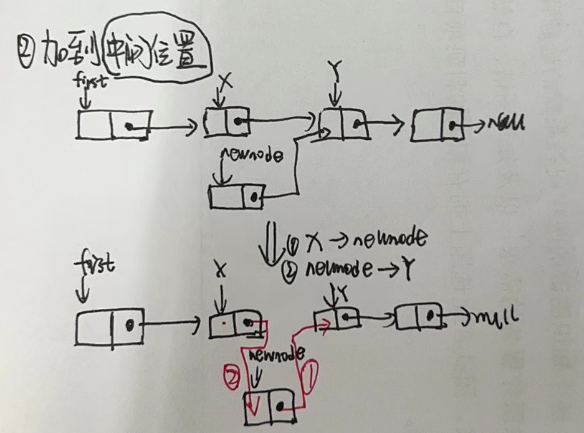
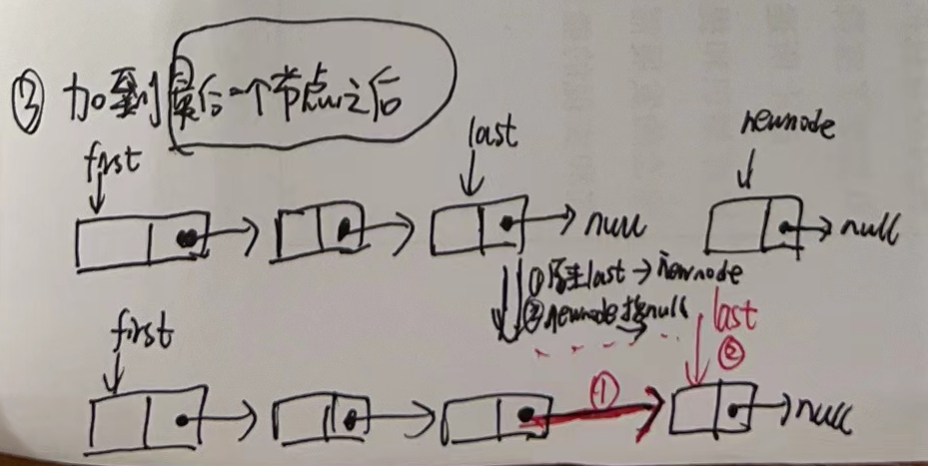
3.2.4 单链表插入节点
- 1.插入到第一个节点前面
- 2.插入到中间位置
- 3.插入到最后一个节点后面
3.2.5 单链表反转
3.3 环形链表
3.3.1 环形链表定义
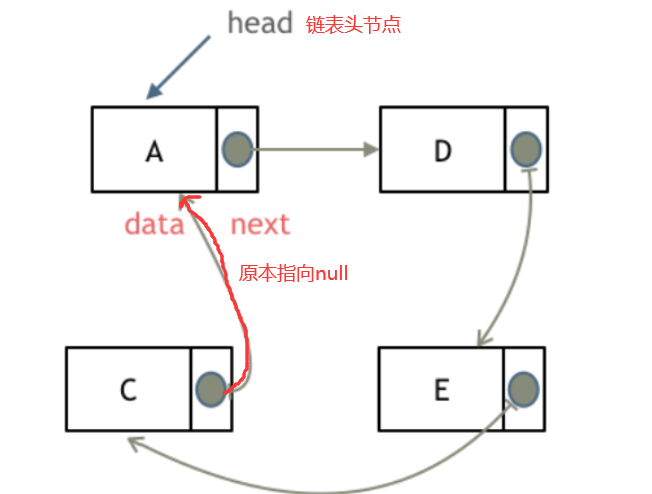
3.3.2 环形链表插入新节点
1.插入到第一节点前,成为新的链接头部
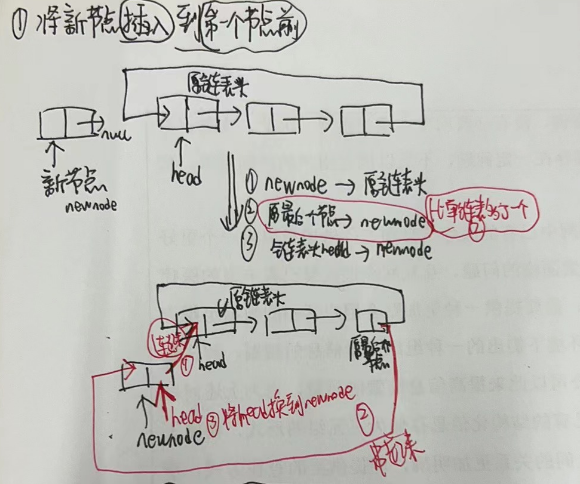
2.插入到中间节点部分
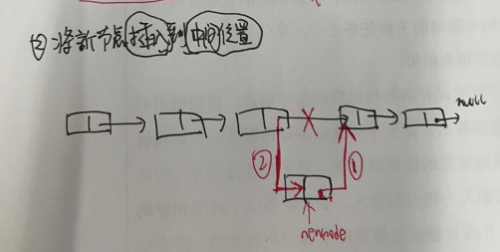
3.3.3 环形链表删除节点
- 1.删除第一个节点
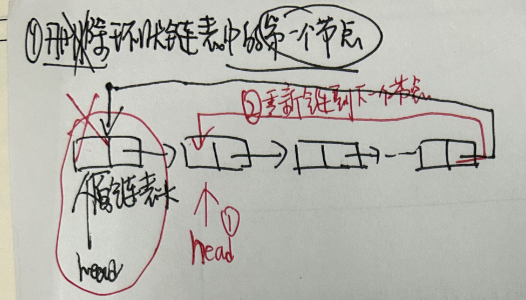
- 2.删除中间节点部分
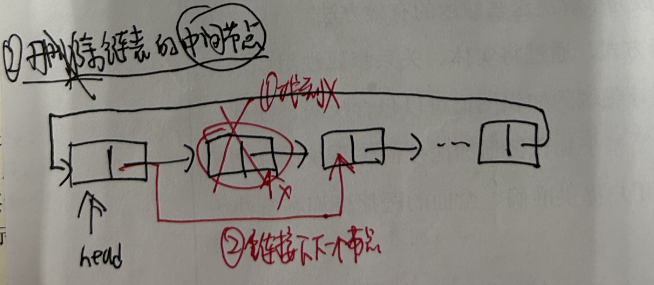
3.3.4 环形链表串联
3.4 双向链表
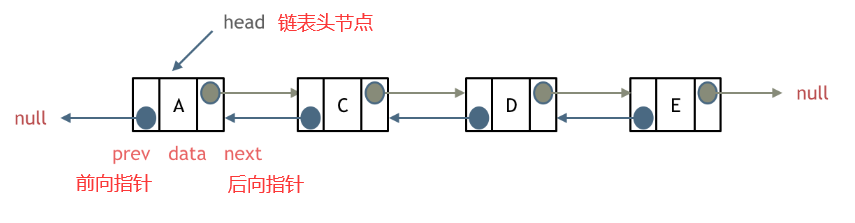
3.4.1 双向链表定义
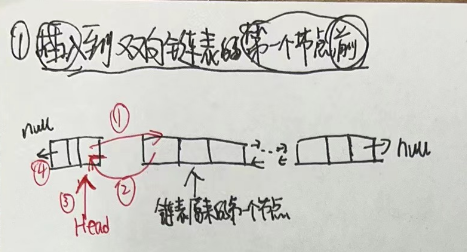
3.4.2 双向链表插入节点
- 1.插入到双向链表的第一个节点前
- 2.插入到双向链表的末尾

- 3.插入到双向链表的中间位置
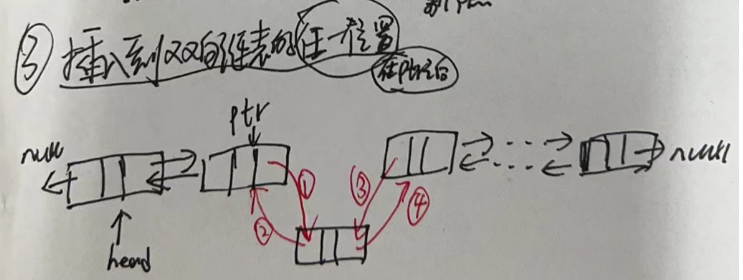
3.4.3 双向链表删除节点
- 1.删除双向链表的第一个节点
- 2.删除双向链表的最后一个节点

- 3.删除双向链表的中间位置

4.堆栈
4.1 堆栈
JAVA-反射
第17章_反射机制
本章专题与脉络
1. 反射(Reflection)的概念
1.1 反射出现的背景
Java程序中,所有的对象都有两种类型:编译时类型和运行时类型,而很多时候对象的编译时类型和运行时类型不一致。
1 | Object obj = new String("hello"); |
例如:某些变量或形参的声明类型是Object类型,但是程序却需要调用该对象运行时类型的方法,该方法不是Object中的方法,那么如何解决呢?
解决这个问题,有两种方案:
1.方案1(向下转型):在编译和运行时都完全知道类型的具体信息,在这种情况下,我们可以直接先使用instanceof运算符进行判断,再利用强制类型转换符将其转换成运行时类型的变量即可。
2.方案2(反射):编译时根本无法预知该对象和类的真实信息,程序只能依靠运行时信息来发现该对象和类的真实信息,这就必须使用反射。
1.2 反射概述
Reflection(反射)是被视为动态语言的关键,反射机制允许程序在运行期间借助Reflection API取得任何类的内部信息,能直接操作任意对象的内部属性及方法。
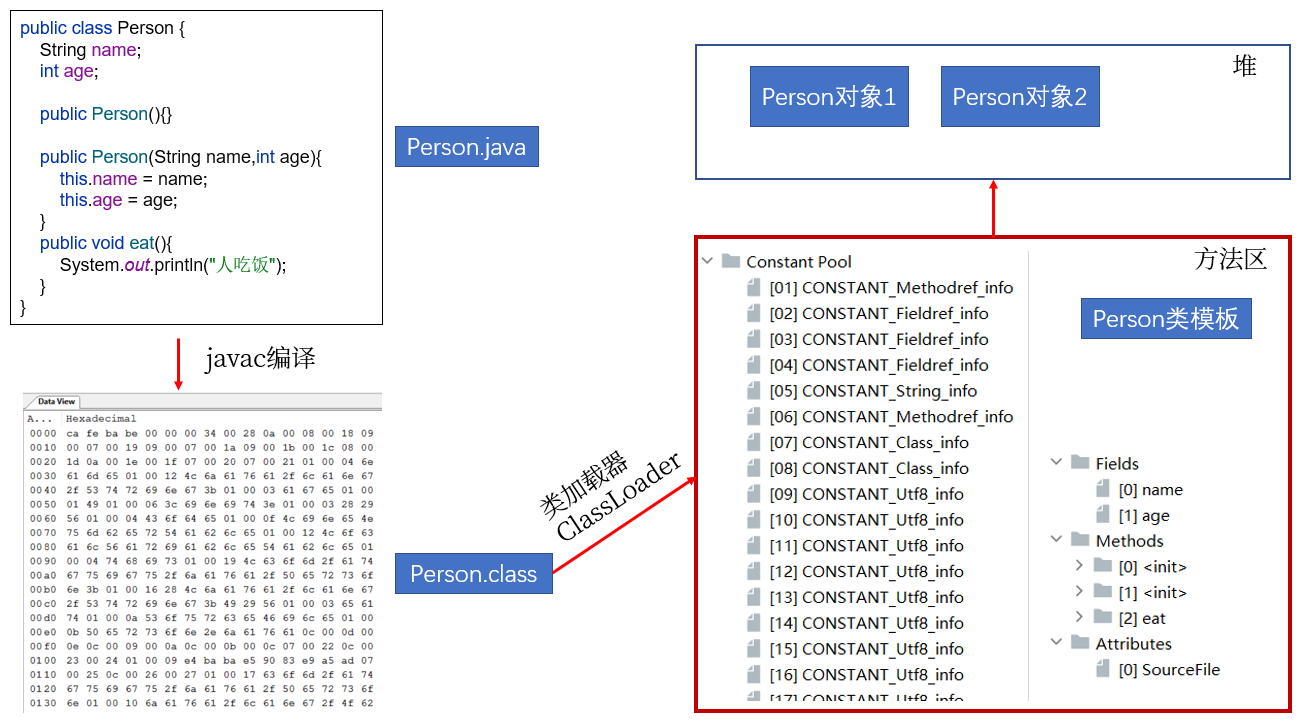
加载完类之后,在堆内存的方法区中就产生了一个Class类型的对象(一个类只有一个Class对象),这个对象就包含了完整的类的结构信息。我们可以通过这个对象看到类的结构。这个对象就像一面镜子,透过这个镜子看到类的结构,所以,我们形象的称之为:反射。
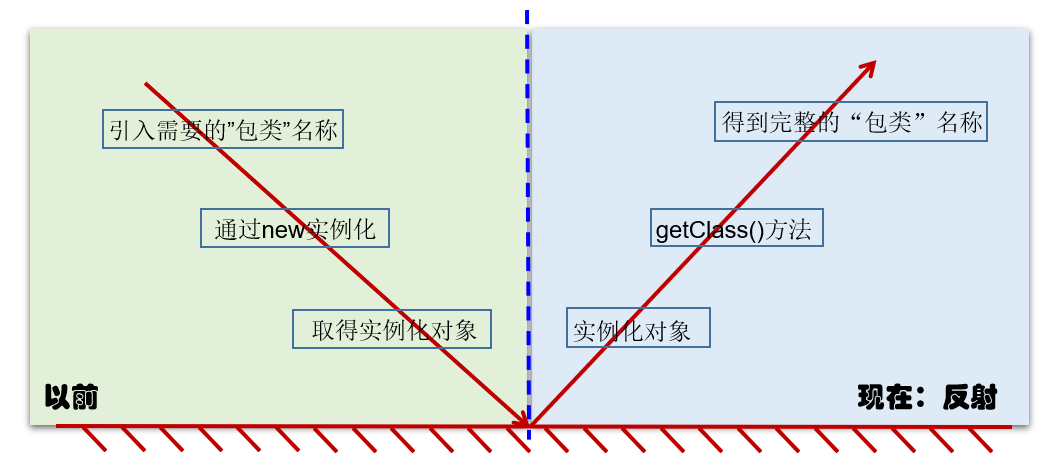
从内存加载上看反射:
1.3 Java反射机制研究及应用
Java反射机制提供的功能:
- 在运行时判断任意一个对象所属的类
- 在运行时构造任意一个类的对象
- 在运行时判断任意一个类所具有的成员变量和方法
- 在运行时获取泛型信息
- 在运行时调用任意一个对象的成员变量和方法
- 在运行时处理注解
- 生成动态代理
1.4 反射相关的主要API
1 | java.lang.Class:代表一个类 |
1.5 反射的优缺点
优点:
提高了Java程序的灵活性和扩展性,
降低了耦合性,提高自适应能力允许程序创建和控制任何类的对象,无需提前
硬编码目标类
缺点:
反射的
性能较低。- 反射机制主要应用在对灵活性和扩展性要求很高的系统框架上
反射会
模糊程序内部逻辑,可读性较差。
2. 理解Class类并获取Class实例
要想解剖一个类,必须先要获取到该类的Class对象。而剖析一个类/用反射解决具体的问题就是使用相关API:
- java.lang.Class
- java.lang.reflect.*
所以,Class对象是反射的根源。
2.1 理解Class
2.1.1 理论上
在Object类中定义了以下的方法,此方法将被所有子类继承:
1 | public final Class getClass() |
以上的方法返回值的类型是一个Class类,此类是Java反射的源头,实际上所谓反射从程序的运行结果来看也很好理解,即:可以通过对象反射求出类的名称。
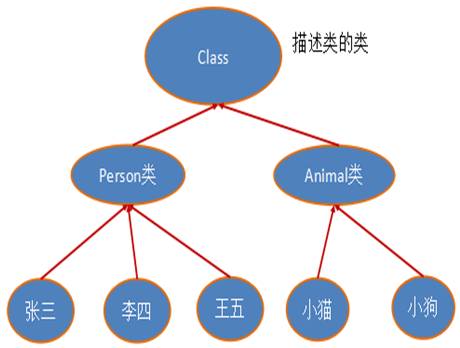
对象照镜子后可以得到的信息:某个类的属性、方法和构造器、某个类到底实现了哪些接口。
对于每个类而言,JRE 都为其保留一个不变的 Class 类型的对象。一个 Class 对象包含了特定某个结构(class/interface/enum/annotation/primitive type/void/[])的有关信息。
- Class本身也是一个类
- Class 对象只能由系统建立对象
- 一个加载的类在 JVM 中只会有一个Class实例
- 一个Class对象对应的是一个加载到JVM中的一个.class文件
- 每个类的实例都会记得自己是由哪个 Class 实例所生成
- 通过Class可以完整地得到一个类中的所有被加载的结构
- Class类是Reflection的根源,针对任何你想动态加载、运行的类,唯有先获得相应的Class对象
2.1.2 内存结构上
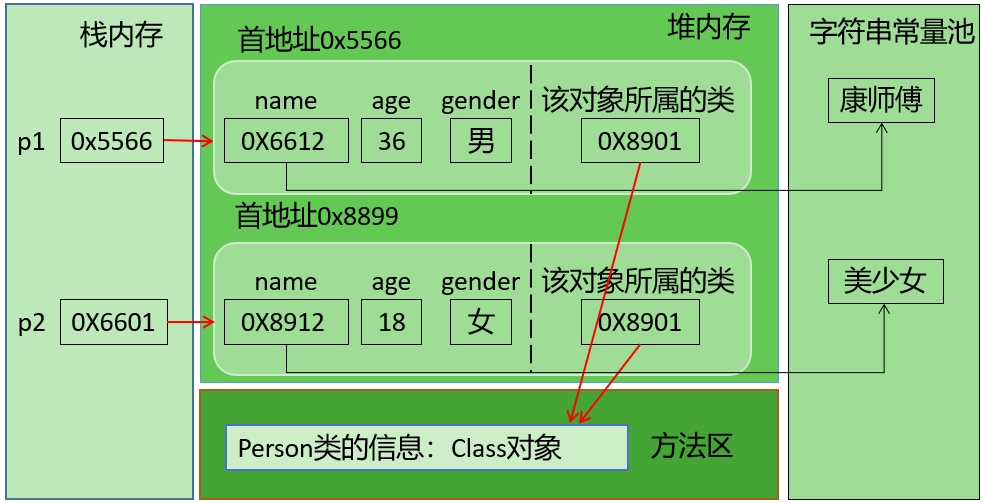
说明:字符串常量池在JDK6中,存储在方法区;
字符串常量池在JDK7及以后,存储在堆空间。
2.2 获取Class类的实例(四种方法)
2.2.1:要求编译期间已知类型
前提:若已知具体的类,通过类的class属性获取,该方法最为安全可靠,程序性能最高
实例:
1 | Class clazz = String.class; |
2.2.2:获取对象的运行时类型
前提:已知某个类的实例,调用该实例的getClass()方法获取Class对象
实例:
1 | Class clazz = "www.atguigu.com".getClass(); |
2.2.3:可以获取编译期间未知的类型
前提:已知一个类的全类名,且该类在类路径下,可通过Class类的静态方法forName()获取,可能抛出ClassNotFoundException
实例:
1 | Class clazz = Class.forName("java.lang.String"); |
2.2.4:其他方式(不做要求)
前提:可以用系统类加载对象或自定义加载器对象加载指定路径下的类型
实例:
1 | ClassLoader cl = this.getClass().getClassLoader(); |
再举例:
1 | public class GetClassObject { |
2.3 哪些类型可以有Class对象
简言之,所有Java类型!
(1)class:外部类,成员(成员内部类,静态内部类),局部内部类,匿名内部类
(2)interface:接口
(3)[]:数组
(4)enum:枚举
(5)annotation:注解@interface
(6)primitive type:基本数据类型
(7)void
举例:
1 | Class c1 = Object.class; |
2.4 Class类的常用方法
| 方法名 | 功能说明 |
|---|---|
| static Class forName(String name) | 返回指定类名name的Class 对象 |
| Object newInstance() | 调用缺省构造函数,返回该Class对象的一个实例 |
| getName() | 返回此Class对象表示的实体(类/接口/数组类/基本类型/void)名称 |
| Class getSuperClass() | 返回当前Class对象的父类的Class对象 |
| Class [] getInterfaces() | 获取当前Class对象的接口 |
| ClassLoader getClassLoader() | 返回该类的类加载器 |
| Class getSuperclass() | 返回表示此Class所表示的实体的超类的Class |
| Constructor[] getConstructors() | 返回一个包含某些Constructor对象的数组 |
| Field[] getDeclaredFields() | 返回Field对象的一个数组 |
| Method getMethod(String name,Class … paramTypes) | 返回一个Method对象,此对象的形参类型为paramType |
举例:
1 | String str = "test4.Person"; |
3. 类的加载与ClassLoader的理解
3.1 类的生命周期
类在内存中完整的生命周期:加载–>使用–>卸载。其中加载过程又分为:装载、链接、初始化三个阶段。
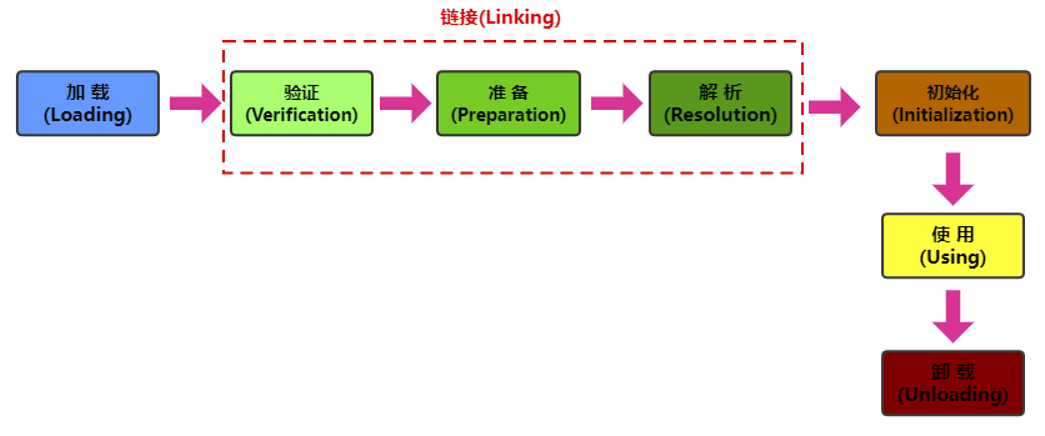
3.2 类的加载过程
当程序主动使用某个类时,如果该类还未被加载到内存中,系统会通过加载、链接、初始化三个步骤来对该类进行初始化。
如果没有意外,JVM将会连续完成这三个步骤,所以有时也把这三个步骤统称为类加载。
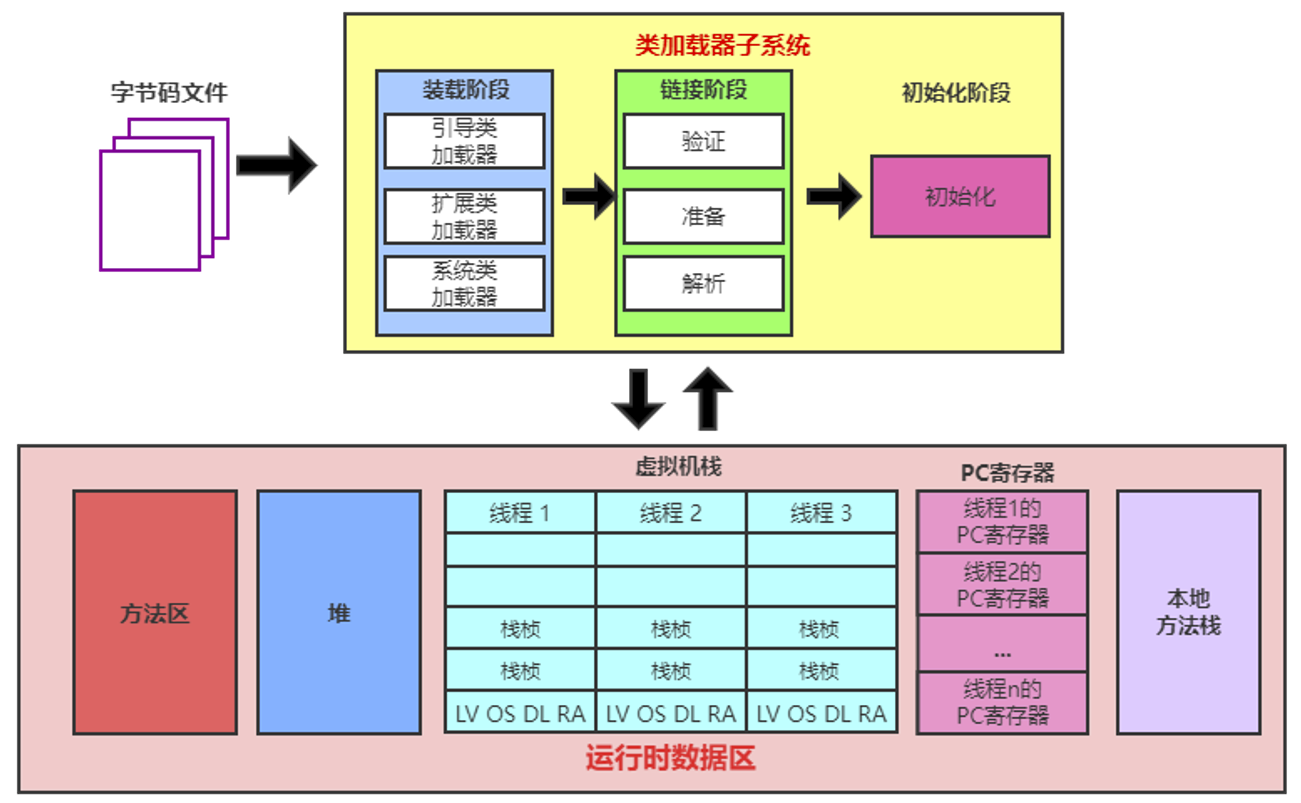
类的加载又分为三个阶段:
(1)装载(Loading)
将类的class文件读入内存,并为之创建一个java.lang.Class对象。此过程由类加载器完成
(2)链接(Linking)
验证Verify:确保加载的类信息符合JVM规范,例如:以cafebabe开头,没有安全方面的问题。
准备Prepare:正式为类变量(static)分配内存并
设置类变量默认初始值的阶段,这些内存都将在方法区中进行分配。解析Resolve:虚拟机常量池内的符号引用(常量名)替换为直接引用(地址)的过程。
(3)初始化(Initialization)
执行
类构造器<clinit>()方法的过程。类构造器<clinit>()方法是由编译期自动收集类中所有类变量的赋值动作和静态代码块中的语句合并产生的。(类构造器是构造类信息的,不是构造该类对象的构造器)。当初始化一个类的时候,如果发现其父类还没有进行初始化,则需要先触发其父类的初始化。
虚拟机会保证一个
类的<clinit>()方法在多线程环境中被正确加锁和同步。
3.3 类加载器(classloader)
3.3.1 类加载器的作用
将class文件字节码内容加载到内存中,并将这些静态数据转换成方法区的运行时数据结构,然后在堆中生成一个代表这个类的java.lang.Class对象,作为方法区中类数据的访问入口。
类缓存:标准的JavaSE类加载器可以按要求查找类,但一旦某个类被加载到类加载器中,它将维持加载(缓存)一段时间。不过JVM垃圾回收机制可以回收这些Class对象。
3.3.2 类加载器的分类(JDK8为例)
JVM支持两种类型的类加载器,分别为引导类加载器(Bootstrap ClassLoader)和自定义类加载器(User-Defined ClassLoader)。
从概念上来讲,自定义类加载器一般指的是程序中由开发人员自定义的一类类加载器,但是Java虚拟机规范却没有这么定义,而是将所有派生于抽象类ClassLoader的类加载器都划分为自定义类加载器。无论类加载器的类型如何划分,在程序中我们最常见的类加载器结构主要是如下情况:
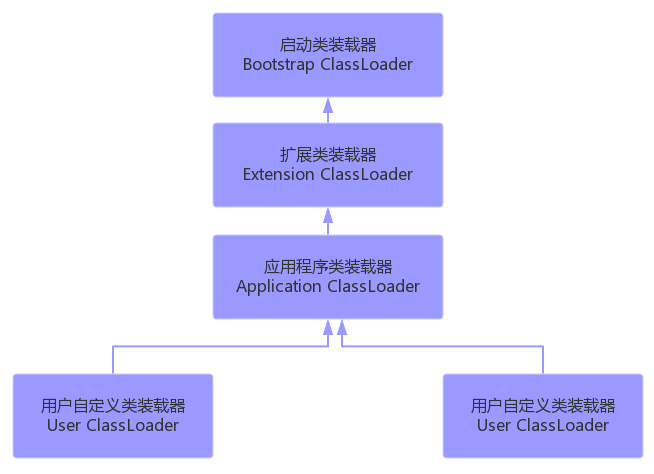
(1)启动类加载器(引导类加载器,Bootstrap ClassLoader)
- 这个类加载使用
C/C++语言实现的,嵌套在JVM内部。获取它的对象时往往返回null - 它用来加载Java的核心库(JAVA_HOME/jre/lib/rt.jar或sun.boot.class.path路径下的内容)。用于提供JVM自身需要的类。
- 并不继承自java.lang.ClassLoader,没有父加载器。
- 出于安全考虑,Bootstrap启动类加载器只加载包名为java、javax、sun等开头的类
- 加载扩展类和应用程序类加载器,并指定为他们的父类加载器。
(2)扩展类加载器(Extension ClassLoader)
- Java语言编写,由sun.misc.Launcher$ExtClassLoader实现。
- 继承于ClassLoader类
- 父类加载器为启动类加载器
- 从java.ext.dirs系统属性所指定的目录中加载类库,或从JDK的安装目录的jre/lib/ext子目录下加载类库。如果用户创建的JAR放在此目录下,也会自动由扩展类加载器加载。
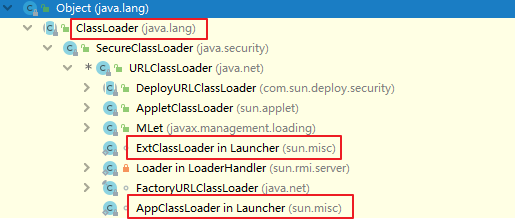
(3)应用程序类加载器(系统类加载器,AppClassLoader)
- java语言编写,由sun.misc.Launcher$AppClassLoader实现
- 继承于ClassLoader类
- 父类加载器为扩展类加载器
- 它负责加载环境变量classpath或系统属性 java.class.path 指定路径下的类库
- 应用程序中的类加载器默认是系统类加载器。
- 它是用户自定义类加载器的默认父加载器
- 通过ClassLoader的getSystemClassLoader()方法可以获取到该类加载器
(4)用户自定义类加载器(了解)
- 在Java的日常应用程序开发中,类的加载几乎是由上述3种类加载器相互配合执行的。在必要时,我们还可以自定义类加载器,来定制类的加载方式。
- 体现Java语言强大生命力和巨大魅力的关键因素之一便是,Java开发者可以自定义类加载器来实现类库的动态加载,加载源可以是本地的JAR包,也可以是网络上的远程资源。
- 同时,自定义加载器能够实现
应用隔离,例如 Tomcat,Spring等中间件和组件框架都在内部实现了自定义的加载器,并通过自定义加载器隔离不同的组件模块。这种机制比C/C++程序要好太多,想不修改C/C++程序就能为其新增功能,几乎是不可能的,仅仅一个兼容性便能阻挡住所有美好的设想。 - 自定义类加载器通常需要继承于ClassLoader。
3.3.3 查看某个类的类加载器对象
(1)获取默认的系统类加载器
1 | ClassLoader classloader = ClassLoader.getSystemClassLoader(); |
(2)查看某个类是哪个类加载器加载的
1 | ClassLoader classloader = Class.forName("exer2.ClassloaderDemo").getClassLoader(); |
(3)获取某个类加载器的父加载器
1 | ClassLoader parentClassloader = classloader.getParent(); |
示例代码:
1 | package com.atguigu.loader; |
3.3.4 使用ClassLoader获取流
关于类加载器的一个主要方法:getResourceAsStream(String str):获取类路径下的指定文件的输入流
1 | InputStream in = null; |
举例:
1 | //需要掌握如下的代码 |
4. 反射的基本应用
有了Class对象,能做什么?
4.1 应用1:创建运行时类的对象
这是反射机制应用最多的地方。创建运行时类的对象有两种方式:
方式1:直接调用Class对象的newInstance()方法
要 求: 1)类必须有一个无参数的构造器。2)类的构造器的访问权限需要足够。
方式2:通过获取构造器对象来进行实例化
方式一的步骤:
1)获取该类型的Class对象 2)调用Class对象的newInstance()方法创建对象
方式二的步骤:
1)通过Class类的getDeclaredConstructor(Class … parameterTypes)取得本类的指定形参类型的构造器
2)向构造器的形参中传递一个对象数组进去,里面包含了构造器中所需的各个参数。
3)通过Constructor实例化对象。
如果构造器的权限修饰符修饰的范围不可见,也可以调用setAccessible(true)
示例代码:
1 | package com.atguigu.reflect; |
4.2 应用2:获取运行时类的完整结构
可以获取:包、修饰符、类型名、父类(包括泛型父类)、父接口(包括泛型父接口)、成员(属性、构造器、方法)、注解(类上的、方法上的、属性上的)。
4.2.1 相关API
1 | //1.实现的全部接口 |
4.2.2 获取所有的属性及相关细节
1 | package com.atguigu.java2; |
4.2.3 获取所有的方法及相关细节
1 | package com.atguigu.java2; |
4.2.4 获取其他结构(构造器、父类、接口、包、注解等)
1 | package com.atguigu.java2; |
4.2.5 获取泛型父类信息(选讲)
示例代码获取泛型父类信息:
1 | /* Type: |
4.2.6 获取内部类或外部类信息(选讲)
public Class<?>[] getClasses():返回所有公共内部类和内部接口。包括从超类继承的公共类和接口成员以及该类声明的公共类和接口成员。
public Class<?>[] getDeclaredClasses():返回 Class 对象的一个数组,这些对象反映声明为此 Class 对象所表示的类的成员的所有类和接口。包括该类所声明的公共、保护、默认(包)访问及私有类和接口,但不包括继承的类和接口。
public Class<?> getDeclaringClass():如果此 Class 对象所表示的类或接口是一个内部类或内部接口,则返回它的外部类或外部接口,否则返回null。
Class<?> getEnclosingClass() :返回某个内部类的外部类
1 |
|
4.2.7 小 结
在实际的操作中,取得类的信息的操作代码,并不会经常开发。
一定要熟悉java.lang.reflect包的作用,反射机制。
4.3 应用3:调用运行时类的指定结构
4.3.1 调用指定的属性
在反射机制中,可以直接通过Field类操作类中的属性,通过Field类提供的set()和get()方法就可以完成设置和取得属性内容的操作。
(1)获取该类型的Class对象
Class clazz = Class.forName(“包.类名”);
(2)获取属性对象
Field field = clazz.getDeclaredField(“属性名”);
(3)如果属性的权限修饰符不是public,那么需要设置属性可访问
field.setAccessible(true);
(4)创建实例对象:如果操作的是非静态属性,需要创建实例对象
Object obj = clazz.newInstance(); //有公共的无参构造
Object obj = 构造器对象.newInstance(实参…);//通过特定构造器对象创建实例对象
(4)设置指定对象obj上此Field的属性内容
field.set(obj,”属性值”);
如果操作静态变量,那么实例对象可以省略,用null表示
(5)取得指定对象obj上此Field的属性内容
Object value = field.get(obj);
如果操作静态变量,那么实例对象可以省略,用null表示
示例代码:
1 | public class Student { |
1 | package com.atguigu.reflect; |
关于setAccessible方法的使用:
- Method和Field、Constructor对象都有setAccessible()方法。
- setAccessible启动和禁用访问安全检查的开关。
- 参数值为true则指示反射的对象在使用时应该取消Java语言访问检查。
- 提高反射的效率。如果代码中必须用反射,而该句代码需要频繁的被调用,那么请设置为true。
- 使得原本无法访问的私有成员也可以访问
- 参数值为false则指示反射的对象应该实施Java语言访问检查。
4.3.2 调用指定的方法

(1)获取该类型的Class对象
Class clazz = Class.forName(“包.类名”);
(2)获取方法对象
Method method = clazz.getDeclaredMethod(“方法名”,方法的形参类型列表);
(3)创建实例对象
Object obj = clazz.newInstance();
(4)调用方法
Object result = method.invoke(obj, 方法的实参值列表);
如果方法的权限修饰符修饰的范围不可见,也可以调用setAccessible(true)
如果方法是静态方法,实例对象也可以省略,用null代替
示例代码:
1 | import org.junit.Test; |
4.3.3 练习
读取user.properties文件中的数据,通过反射完成User类对象的创建及对应方法的调用。
配置文件:user.properties
1 | className:com.atguigu.bean.User |
User.java文件:
1 | package com.atguigu.bean; |
ReflectTest.java文件:
1 | package com.atguigu.java4; |
5. 应用4:读取注解信息
一个完整的注解应该包含三个部分:
(1)声明
(2)使用
(3)读取
5.1 声明自定义注解
1 | import java.lang.annotation.*; |
1 | import java.lang.annotation.*; |
- 自定义注解可以通过四个元注解@Retention,@Target,@Inherited,@Documented,分别说明它的声明周期,使用位置,是否被继承,是否被生成到API文档中。
- Annotation 的成员在 Annotation 定义中以无参数有返回值的抽象方法的形式来声明,我们又称为配置参数。返回值类型只能是八种基本数据类型、String类型、Class类型、enum类型、Annotation类型、以上所有类型的数组
- 可以使用 default 关键字为抽象方法指定默认返回值
- 如果定义的注解含有抽象方法,那么使用时必须指定返回值,除非它有默认值。格式是“方法名 = 返回值”,如果只有一个抽象方法需要赋值,且方法名为value,可以省略“value=”,所以如果注解只有一个抽象方法成员,建议使用方法名value。
5.2 使用自定义注解
1 | ("t_stu") |
5.3 读取和处理自定义注解
自定义注解必须配上注解的信息处理流程才有意义。
我们自己定义的注解,只能使用反射的代码读取。所以自定义注解的声明周期必须是RetentionPolicy.RUNTIME。
1 | import java.lang.reflect.Field; |
6. 体会反射的动态性
体会1:
1 | public class ReflectionTest { |
体会2:
1 | public class ReflectionTest { |
体会3:
1 | public class ReflectionTest { |
其中,配置文件【config.properties】存放在当前Module的src下
1 | com.atguigu.java1.Orange |
计算机网络
1.计算机网络概述
1.1 网络的网络
网络把主机连接起来,而互连网(internet)是把多种不同的网络连接起来,因此互连网是网络的网络。而互联网(Internet)是全球范围的互连网
1.2 主机之间的通信方式
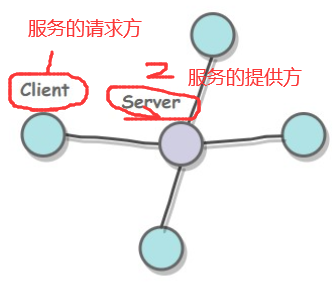
1.2.1 客户-服务器(C/S)
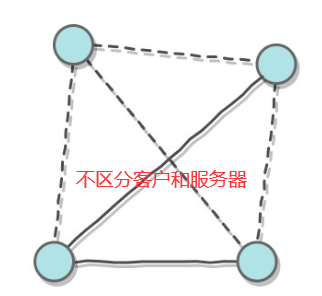
1.2.2 对等(P2P)
1.3 电路交换和分组交换
电路交换
电路交换用于电话通信系统,两个用户要通信之前需要建立一条专用的物理链路,并且在整个通信过程中始终占用该链路。由于通信的过程中不可能一直在使用传输线路,因此电路交换对线路的利用率很低,往往不到 10%分组交换
每个分组都有首部和尾部,包含了源地址和目的地址等控制信息,在同一个传输线路上同时传输多个分组互相不会影响,因此在同一条传输线路上允许同时传输多个分组,也就是说分组交换不需要占用传输线路。
在一个邮局通信系统中,邮局收到一份邮件之后,先存储下来,然后把相同目的地的邮件一起转发到下一个目的地,这个过程就是存储转发过程,分组交换也使用了存储转发过程。
1.4 四种时延
| 四种时延 | 定义 | 进一步解释 |
|---|---|---|
| 排队时延 | 分组在路由器的输入队列和输出队列中排队等待的时间 | 取决于网络当前的通信量 |
| 处理时延 | 主机/路由器收到分组时进行处理需要的时间 | 分析首部、从分组中提取数据、差错检验、查找适合的路由 |
| 传输时延 | 主机/路由器传输数据帧所需要的时间 | 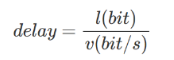 ,其中l代表数据帧长度,v代表传输速率 ,其中l代表数据帧长度,v代表传输速率 |
| 传播时延 | 电磁波在信道中传播所需要的时间 | 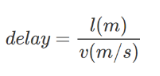 ,其中l代表信道长度,v代表电磁波在信道上传播速度 ,其中l代表信道长度,v代表电磁波在信道上传播速度 |
1.5 计算机网络体系结构
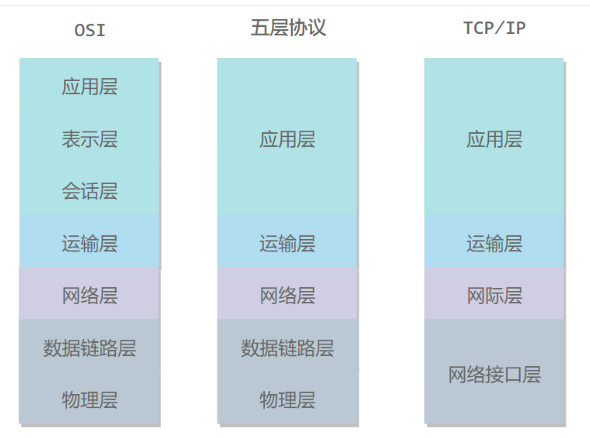
1.5.1 五层协议
应用层 :为特定应用程序提供数据传输服务,例如 HTTP、DNS 等协议。数据单位为报文。
传输层 :为进程提供通用数据传输服务。由于应用层协议很多,定义通用的传输层协议就可以支持不断增多的应用层协议。
运输层包括两种协议:(TCP 主要提供完整性服务,UDP 主要提供及时性服务。)1.传输控制协议 TCP,提供面向连接、可靠的数据传输服务,数据单位为报文段;
2.用户数据报协议 UDP,提供无连接、尽最大努力的数据传输服务,数据单位为用户数据报。网络层 :为主机提供数据传输服务。而传输层协议是为主机中的进程提供数据传输服务。网络层把传输层传递下来的报文段或者用户数据报封装成分组。
数据链路层 :网络层针对的还是主机之间的数据传输服务,而主机之间可以有很多链路,链路层协议就是为同一链路的主机提供数据传输服务。数据链路层把网络层传下来的分组封装成帧。
物理层 :考虑的是怎样在传输媒体上传输数据比特流,而不是指具体的传输媒体。物理层的作用是尽可能屏蔽传输媒体和通信手段的差异,使数据链路层感觉不到这些差异。
| 层名 | 传输的数据 | 作用 | 协议 |
|---|---|---|---|
| 应用层 | 报文 | 为特定应用程序提供数据传输服务 | FTP(文件传输协议) DNS(域名系统) HTTP(超文本传输协议) DHCP(动态主机配置协议) TELNET(远程登录协议) SMTP() POP3() IMAP() |
| 传输层 | TCP报文段 UDP用户数据包 |
为进程提供通用数据传输服务 | TCP(传输控制协议) UDP(用户数据报协议) |
| 网络层 | IP数据包 | 为主机提供数据传输服务 | IP(网络互连协议) ARP(地址解析协议) ICMP(网际控制报文协议) IGMP(网际组管理协议) |
| 数据链路层 | 数据帧 | 为同一链路的主机提供数据传输服务 | PPP协议 |
| 物理层 | 数据比特流 | 虑的是怎样在传输媒体上传输数据比特流 |
1.5.2 OSI
其中表示层和会话层用途如下:
- 表示层 :数据压缩、加密以及数据描述,这使得应用程序不必关心在各台主机中数据内部格式不同的问题。
- 会话层 :建立及管理会话。
五层协议没有表示层和会话层,而是将这些功能留给应用程序开发者处理。
1.5.3 TCP/IP
其中表示层和会话层用途如下:
- 表示层 :数据压缩、加密以及数据描述,这使得应用程序不必关心在各台主机中数据内部格式不同的问题。
- 会话层 :建立及管理会话。
五层协议没有表示层和会话层,而是将这些功能留给应用程序开发者处理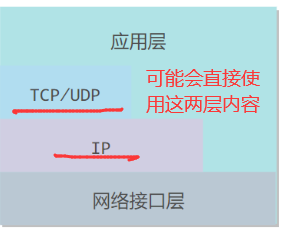
1.5.4 数据在各层的传递过程
在向下的过程中,需要添加下层协议所需要的首部或者尾部,而在向上的过程中不断拆开首部和尾部。
路由器只有下面三层协议,因为路由器位于网络核心中,不需要为进程或者应用程序提供服务,因此也就不需要传输层和应用层。
2.物理层
2.1 通信方式
根据信息在传输线上的传送方向,分为以下三种通信方式:
- 单工通信:单向传输
- 半双工通信:双向交替传输
- 全双工通信:双向同时传输
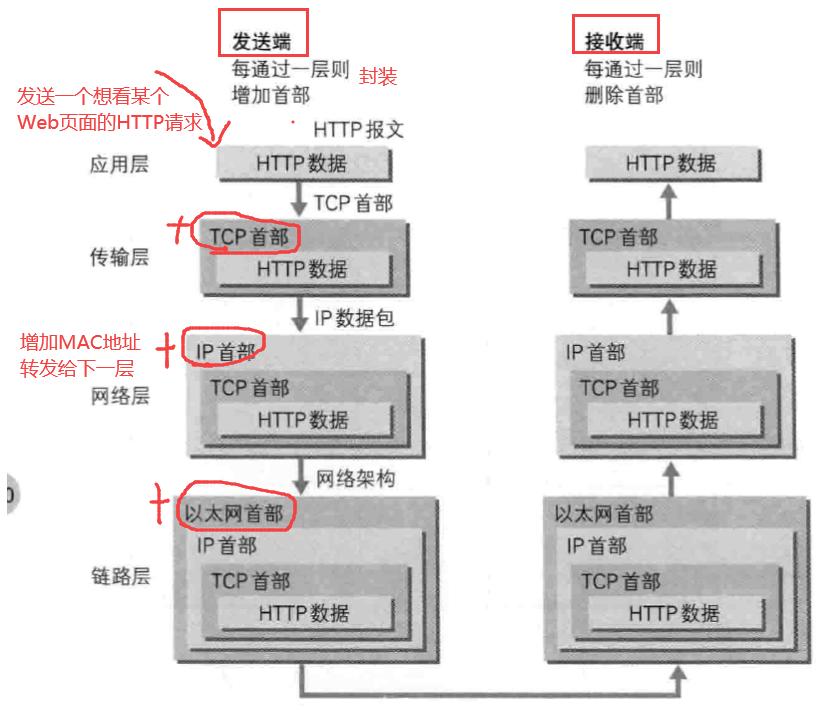
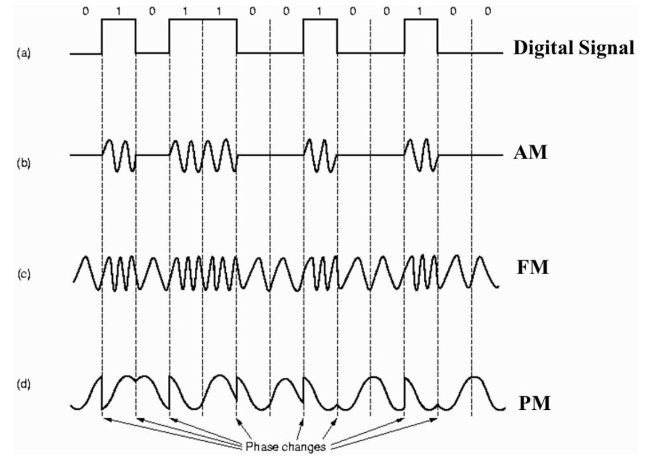
2.2 带通调制
- 带通调制:数字信号(离散的信号)–> 模拟信号(连续的信号)
3.数据链路层
3.1 三大基本问题
3.1.1 封装成帧
将网络层传下来的分组添加首部和尾部(向下封装),用于标记帧的开始和结束

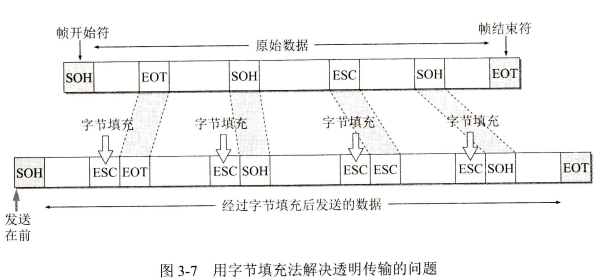
3.1.2 透明传输
帧使用首部和尾部进行定界,如果帧的数据部分含有和首部尾部相同的内容,那么帧的开始和结束位置就会被错误的判定。需要在数据部分出现首部尾部相同的内容前面插入转义字符。如果数据部分出现转义字符,那么就在转义字符前面再加个转义字符。在接收端进行处理之后可以还原出原始数据。这个过程透明传输的内容是转义字符,用户察觉不到转义字符的存在
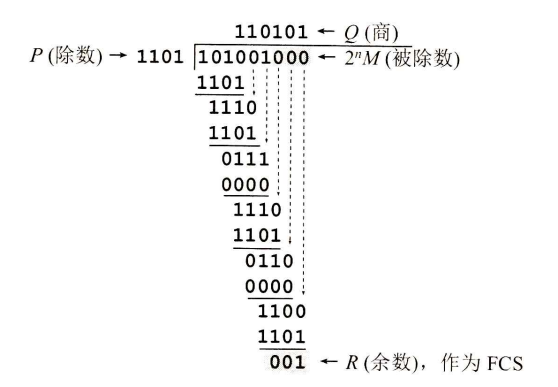
3.1.3 差错检测
目前数据链路层广泛使用循环冗余检验(CRC)来检查比特差错
3.2 信道分类
| 形式 | 具体细节 | 控制方式 | |
|---|---|---|---|
| 广播信道 | 一对多 | 一个节点发送的数据能够被广播信道上所有的节点接收到 【所以节点在同一个广播信道上发送数据,需要专门的控制方法进行协调,避免发生冲突】 |
1.信道复用技术 2.CSMA/CD协议 |
| 点对点信道 | 一对一 | 一个节点发送的数据只能被对应节点接收到 【不会发生碰撞,比较简单】 |
PPP协议 |
3.3 广播信道的两种控制方式
3.3.1 信道复用技术
| 定义 | 图形 | |
|---|---|---|
| 频分复用 | 所有主机在相同的时间占用不同的频率带宽资源 |  |
| 时分复用 | 所有主机在不同的时间占用相同的频率带宽资源 |  |
| 统计时分复用 | 对时分复用的一种改进,不固定每个用户在时分复用帧中的位置,只要有数据就集中起来组成统计时分复用帧然后发送 | 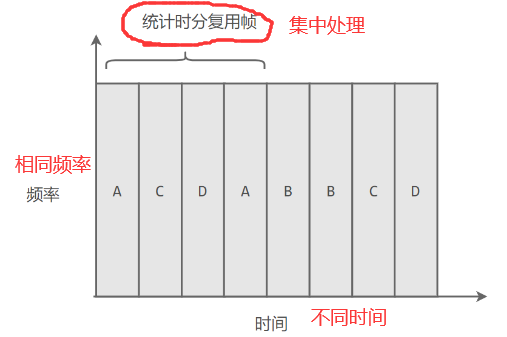 |
| 波分复用 | 光的频分复用 【由于光的频率很高,因此习惯上用波长而不是频率来表示所使用的光载波】 |
 |
| 码分复用 | 当码分复用信道为多个不同地址的用户所共享时 |  |
3.3.2 CSMA/CD协议
- 多点接入 :说明这是总线型网络,许多主机以多点的方式连接到总线上。
- 载波监听 :每个主机都必须不停地监听信道。在发送前,如果监听到信道正在使用,就必须等待。
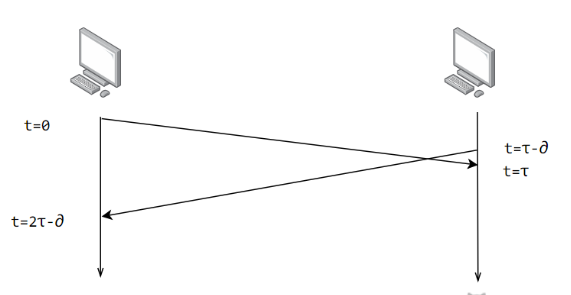
- 碰撞检测 :在发送中,如果监听到信道已有其它主机正在发送数据,就表示发生了碰撞。虽然每个主机在发送数据之前都已经监听到信道为空闲,但是由于电磁波的传播时延的存在,还是有可能会发生碰撞。
记端到端的传播时延为 τ,最先发送的站点最多经过 2τ 就可以知道是否发生了碰撞,称 2τ 为 争用期 。只有经过争用期之后还没有检测到碰撞,才能肯定这次发送不会发生碰撞。
当发生碰撞时,站点要停止发送,等待一段时间再发送。这个时间采用 截断二进制指数退避算法 来确定。从离散的整数集合 {0, 1, .., (2k-1)} 中随机取出一个数,记作 r,然后取 r 倍的争用期作为重传等待时间。
3.4 点对点信道的控制方式
3.4.1 PPP协议
互联网用户通常需要连接到某个 ISP 之后才能接入到互联网,PPP 协议是用户计算机和 ISP 进行通信时所使用的数据链路层协议
- F 字段为帧的定界符
- A 和 C 字段暂时没有意义
- 信息部分的长度不超过 1500
- FCS 字段是使用 CRC 的检验序列

3.5 MAC地址
- MAC地址=链路层地址(一台主机拥有多少个网络适配器就有多少个 MAC 地址)
- MAC地址用于唯一标识网络适配器(网卡)
- MAC地址长度为6字节(48位)
3.6 局域网
- 局域网是一种典型的广播信道,主要特点是网络为一个单位所拥有,且地理范围和站点数目均有限
- 局域网技术分类:①以太网(主要市场) ②令牌环网 ③FDDI ④ATM
- 局域网按照网络拓扑结构分类:
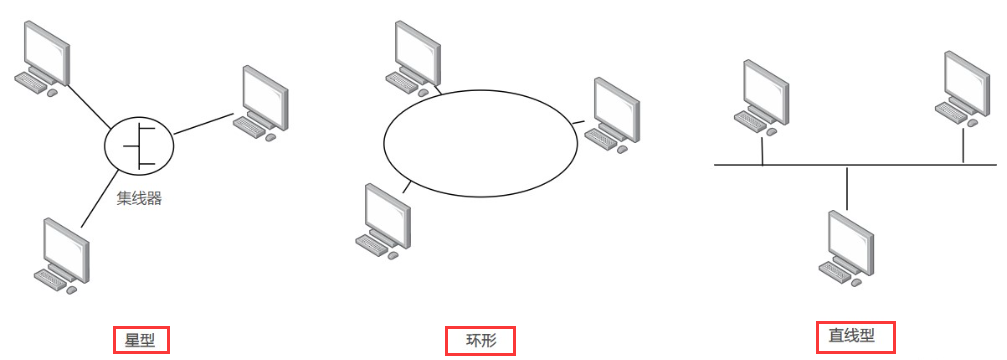
3.6.1 以太网
其中星型拓扑结构局域网—-以太网
早期,使用集线器进行连接,集线器是一种物理层设备, 作用于比特而不是帧,当一个比特到达接口时,集线器重新生成这个比特,并将其能量强度放大,从而扩大网络的传输距离,之后再将这个比特发送到其它所有接口。如果集线器同时收到两个不同接口的帧,那么就发生了碰撞。
目前,使用交换机替代了集线器,交换机是一种链路层设备,它不会发生碰撞,能根据 MAC 地址进行存储转发。
以太网帧格式:
类型 :标记上层使用的协议;
数据 :长度在 46-1500 之间,如果太小则需要填充;
FCS :帧检验序列,使用的是 CRC 检验方法;

3.7 交换机
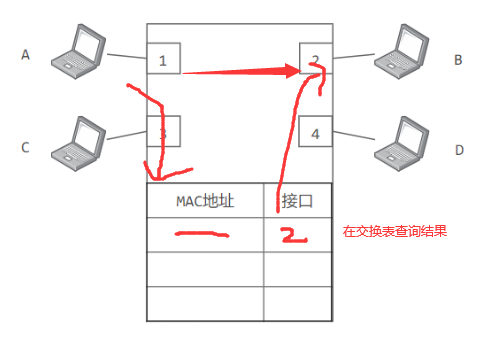
交换机学习交换表内容(存储MAC地址到接口的映射)
由于这种自学习能力,因此交换机是一种即插即用设备,不需要网络管理员手动配置交换表内容。
下图中,交换机有 4 个接口,主机 A 向主机 B 发送数据帧时,交换机把主机 A 到接口 1 的映射写入交换表中。为了发送数据帧到 B,先查交换表,此时没有主机 B 的表项,那么主机 A 就发送广播帧,主机 C 和主机 D 会丢弃该帧,主机 B 回应该帧向主机 A 发送数据包时,交换机查找交换表得到主机 A 映射的接口为 1,就发送数据帧到接口 1,同时交换机添加主机 B 到接口 2 的映射
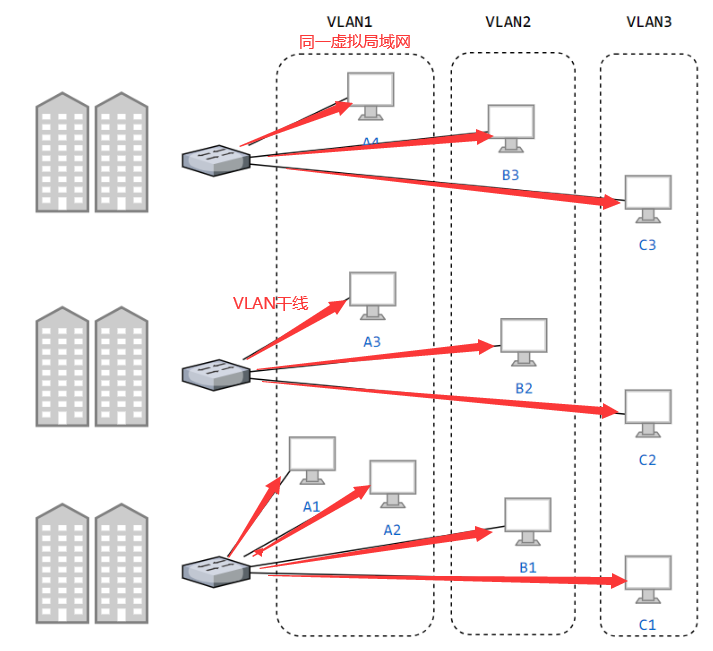
3.8 虚拟局域网
虚拟局域网可以建立与物理位置无关的逻辑组,只有在同一个虚拟局域网中的成员才会收到链路层广播信息。
例如下图中 (A1, A2, A3, A4) 属于一个虚拟局域网,A1 发送的广播会被 A2、A3、A4 收到,而其它站点收不到。
使用 VLAN 干线连接来建立虚拟局域网,每台交换机上的一个特殊接口被设置为干线接口,以互连 VLAN 交换机。IEEE 定义了一种扩展的以太网帧格式 802.1Q,它在标准以太网帧上加进了 4 字节首部 VLAN 标签,用于表示该帧属于哪一个虚拟局域网
4.网络层
网络层是整个互联网的核心,因此应当让网络层尽可能简单。网络层向上只提供简单灵活的、无连接的、尽最大努力交互的数据报服务
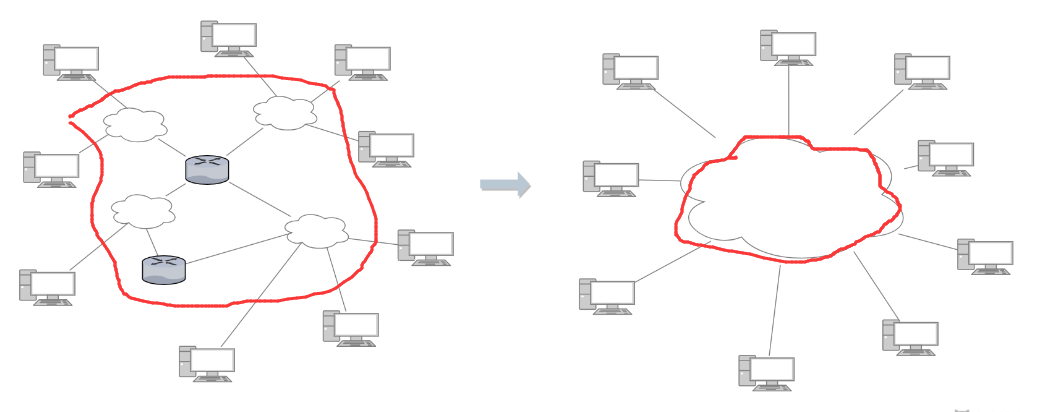
使用 IP 协议,可以把异构的物理网络连接起来,使得在网络层看起来好像是一个统一的网络
4.1 IP协议
4.1.1 IP数据包格式
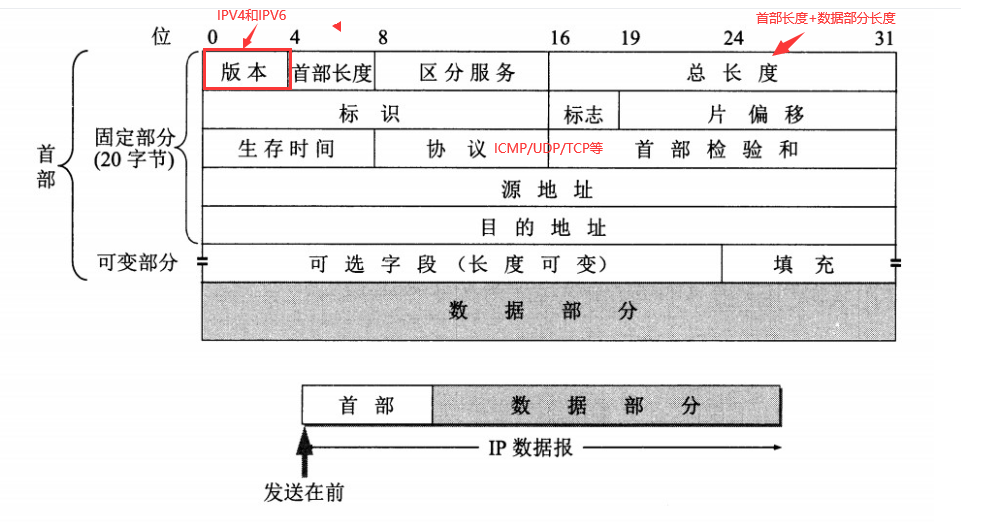
- 版本 : 有 4(IPv4)和 6(IPv6)两个值;
- 首部长度 : 占 4 位,因此最大值为 15。值为 1 表示的是 1 个 32 位字的长度,也就是 4 字节。因为固定部分长度为 20 字节,因此该值最小为 5。如果可选字段的长度不是 4 字节的整数倍,就用尾部的填充部分来填充。
- 区分服务 : 用来获得更好的服务,一般情况下不使用。
- 总长度 : 包括首部长度和数据部分长度。
- 生存时间 :TTL,它的存在是为了防止无法交付的数据报在互联网中不断兜圈子。以路由器跳数为单位,当 TTL 为 0 时就丢弃数据报。
- 协议 :指出携带的数据应该上交给哪个协议进行处理,例如 ICMP、TCP、UDP 等。
- 首部检验和 :因为数据报每经过一个路由器,都要重新计算检验和,因此检验和不包含数据部分可以减少计算的工作量。
- 标识 : 在数据报长度过长从而发生分片的情况下,相同数据报的不同分片具有相同的标识符。
- 片偏移 : 和标识符一起,用于发生分片的情况。片偏移的单位为 8 字节
4.1.2 IP地址编址方式
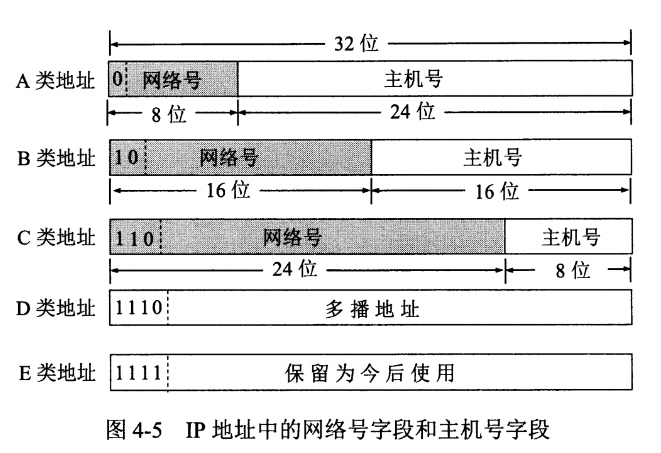
4.1.2.1 分类
由两部分组成,网络号和主机号,其中不同分类具有不同的网络号长度,并且是固定的。
IP 地址 ::= {< 网络号 >, < 主机号 >}
4.1.2.2 子网划分
通过在主机号字段中拿一部分作为子网号,把两级 IP 地址划分为三级 IP 地址。
IP 地址 ::= {< 网络号 >, < 子网号 >, < 主机号 >}
使用子网,必须配置子网掩码。一个 B 类地址的默认子网掩码为 255.255.0.0,如果 B 类地址的子网占两个比特,那么子网掩码为 11111111 11111111 11000000 00000000,也就是 255.255.192.0。
注意,外部网络看不到子网的存在。
4.1.2.3 不分类
无分类编址 CIDR 消除了传统 A 类、B 类和 C 类地址以及划分子网的概念,使用网络前缀和主机号来对 IP 地址进行编码,网络前缀的长度可以根据需要变化。
IP 地址 ::= {< 网络前缀号 >, < 主机号 >}
CIDR 的记法:IP 地址+网络前缀长度,例如 128.14.35.7/20 表示前 20 位为网络前缀。
CIDR 的地址掩码:子网掩码,子网掩码首 1 长度为网络前缀的长度。
一个 CIDR 地址块中有很多地址,一个 CIDR 表示的网络就可以表示原来的很多个网络,并且在路由表中只需要一个路由就可以代替原来的多个路由,减少了路由表项的数量。把这种通过使用网络前缀来减少路由表项的方式称为路由聚合,也称为 构成超网 。
在路由表中的项目由“网络前缀”和“下一跳地址”组成,在查找时可能会得到不止一个匹配结果,应当采用最长前缀匹配来确定应该匹配哪一个。
4.2 ARP 地址解析协议
网络层实现主机之间的通信,而链路层实现具体每段链路之间的通信。因此在通信过程中,IP 数据报的源地址和目的地址始终不变,而 MAC 地址随着链路的改变而改变。
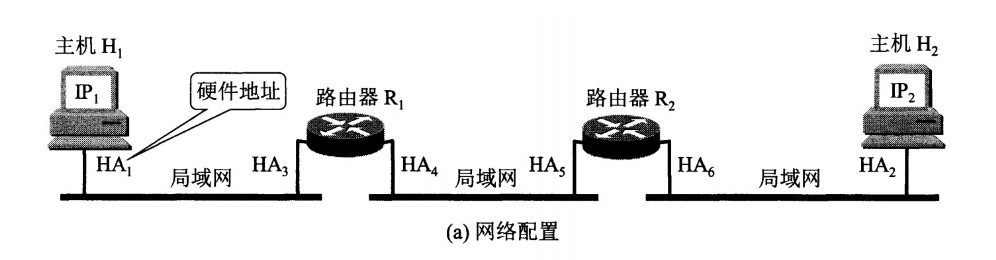
ARP 实现: IP 地址 –> MAC 地址
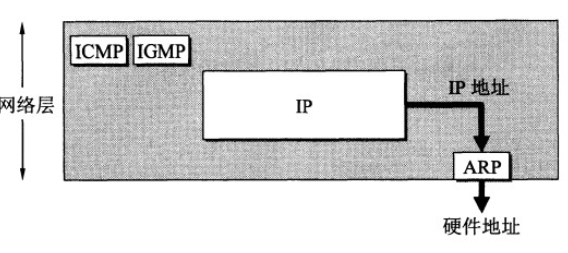
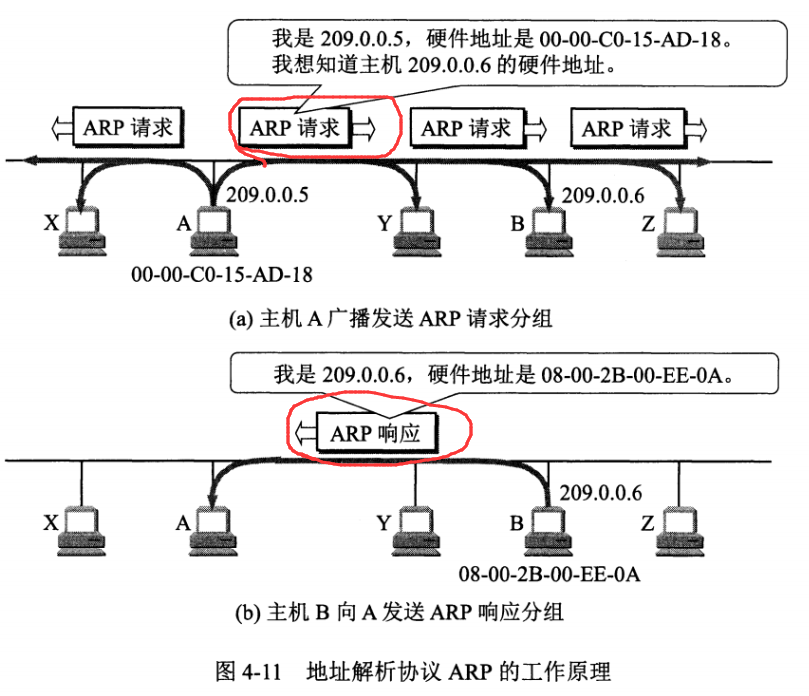
每个主机都有一个 ARP 高速缓存(局域网上的各主机和路由器的 IP 地址到 MAC 地址)映射表。
如果主机 A 知道主机 B 的 IP 地址,但是 ARP 高速缓存中没有该 IP 地址到 MAC 地址的映射,此时主机 A 通过广播的方式发送 ARP 请求分组,主机 B 收到该请求后会发送 ARP 响应分组给主机 A 告知其 MAC 地址,随后主机 A 向其高速缓存中写入主机 B 的 IP 地址到 MAC 地址的映射。
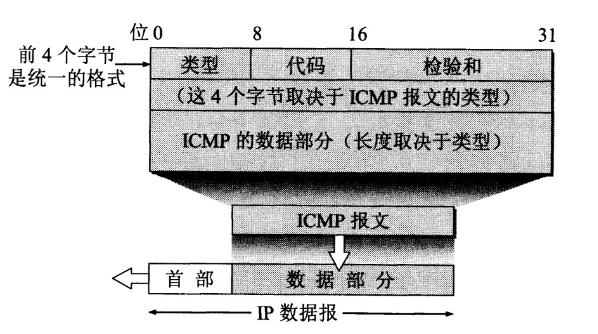
4.3 ICMP 网际控制报文协议
ICMP 是为了更有效地转发 IP 数据报和提高交付成功的机会
ICMP封装在 IP 数据报中,但是不属于高层协议
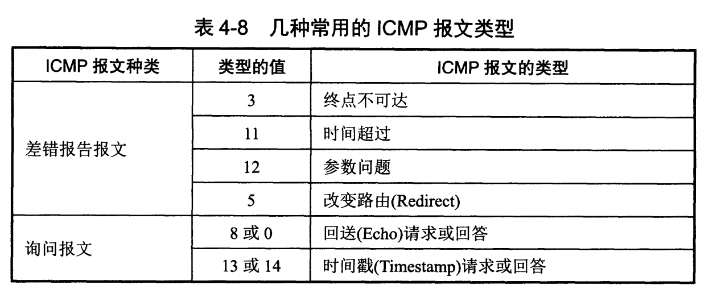
ICMP 报文分为差错报告报文和询问报文
4.3.1 Ping
1.作用:用来测试两台主机之间的连通性
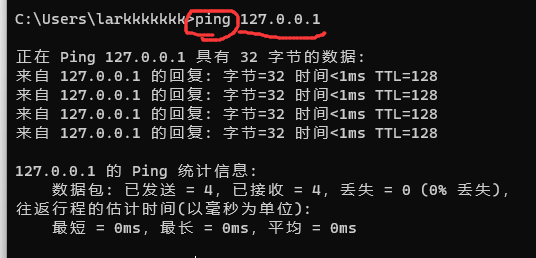
2.Ping 的原理:是通过向目的主机发送 ICMP Echo 请求报文,目的主机收到之后会发送 Echo 回答报文。Ping 会根据时间和成功响应的次数估算出数据包往返时间以及丢包率
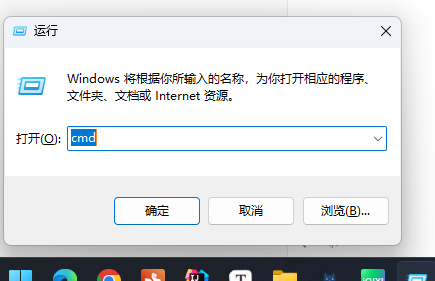
具体步骤:
1.Win+R快捷键输入cmd
2.输入ping ip地址
4.3.2 Traceroute
1.作用:用来跟踪一个分组从源点到终点的路径
Traceroute 发送的 IP 数据报封装的是无法交付的 UDP 用户数据报,并由目的主机发送终点不可达差错报告报文。
- 源主机向目的主机发送一连串的 IP 数据报。第一个数据报 P1 的生存时间 TTL 设置为 1,当 P1 到达路径上的第一个路由器 R1 时,R1 收下它并把 TTL 减 1,此时 TTL 等于 0,R1 就把 P1 丢弃,并向源主机发送一个 ICMP 时间超过差错报告报文;
- 源主机接着发送第二个数据报 P2,并把 TTL 设置为 2。P2 先到达 R1,R1 收下后把 TTL 减 1 再转发给 R2,R2 收下后也把 TTL 减 1,由于此时 TTL 等于 0,R2 就丢弃 P2,并向源主机发送一个 ICMP 时间超过差错报文。
- 不断执行这样的步骤,直到最后一个数据报刚刚到达目的主机,主机不转发数据报,也不把 TTL 值减 1。但是因为数据报封装的是无法交付的 UDP,因此目的主机要向源主机发送 ICMP 终点不可达差错报告报文。
- 之后源主机知道了到达目的主机所经过的路由器 IP 地址以及到达每个路由器的往返时间。
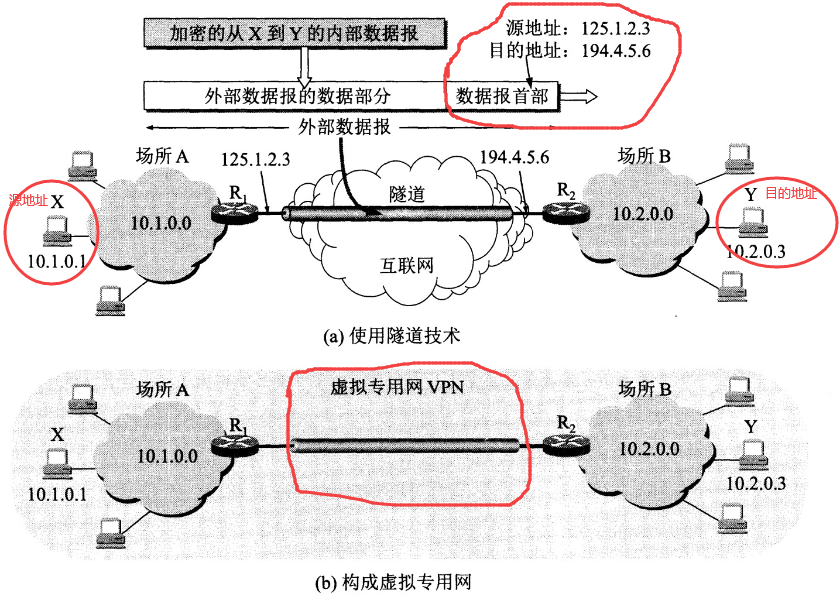
4.4 虚拟专用网 VPN
由于 IP 地址的紧缺,一个机构能申请到的 IP 地址数 << 本机构所拥有的主机数。并且一个机构并不需要把所有的主机接入到外部的互联网中,机构内的计算机可以使用仅在本机构有效的 IP 地址(专用地址)
有三个专用地址块:
- 10.0.0.0 ~ 10.255.255.255
- 172.16.0.0 ~ 172.31.255.255
- 192.168.0.0 ~ 192.168.255.255
VPN 使用公用的互联网作为本机构各专用网之间的通信载体。专用指机构内的主机只与本机构内的其它主机通信;虚拟指好像是,而实际上并不是,它有经过公用的互联网。
4.5 网络地址转换 NAT
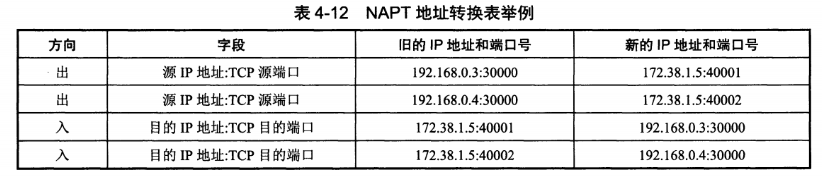
专用网内部的主机使用本地 IP 地址又想和互联网上的主机通信时,可以使用 NAT 来将本地 IP –> 全球 IP。
在以前,NAT 将本地 IP 和全球 IP 一一对应,这种方式下拥有 n 个全球 IP 地址的专用网内最多只可以同时有 n 台主机接入互联网。为了更有效地利用全球 IP 地址,现在常用的 NAT 转换表把传输层的端口号也用上了,使得多个专用网内部的主机共用一个全球 IP 地址。使用端口号的 NAT 也叫做网络地址与端口转换 NAPT
4.6 路由器
4.6.1 路由器的结构
| 功能划分 | 组成 |
|---|---|
| 路由选择 | 内部网关协议 RIP 内部网关协议 OSPF 外部网关协议 BGP |
| 分组转发 | 交换结构 一组输入端口 一组输出端口 |
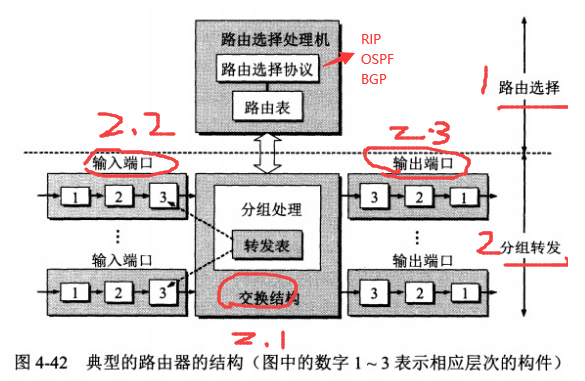
4.6.2 路由选择-三大协议
路由选择协议都是自适应的,能随着网络通信量和拓扑结构的变化而自适应地进行调整。
互联网可以划分为许多较小的自治系统 AS,一个 AS 可以使用一种和别的 AS 不同的路由选择协议。
可以把路由选择协议划分为两大类:
- 自治系统内部的路由选择:RIP 和 OSPF
- 自治系统间的路由选择:BGP
4.6.2.1 内部网关协议 RIP
RIP 是一种基于距离向量的路由选择协议。距离是指跳数,直接相连的路由器跳数为 1。跳数最多为 15,超过 15 表示不可达。
RIP 按固定的时间间隔仅和相邻路由器交换自己的路由表,经过若干次交换之后,所有路由器最终会知道到达本自治系统中任何一个网络的最短距离和下一跳路由器地址。
距离向量算法:
- 对地址为 X 的相邻路由器发来的 RIP 报文,先修改报文中的所有项目,把下一跳字段中的地址改为 X,并把所有的距离字段加 1;
- 对修改后的 RIP 报文中的每一个项目,进行以下步骤:
- 若原来的路由表中没有目的网络 N,则把该项目添加到路由表中;
- 否则:若下一跳路由器地址是 X,则把收到的项目替换原来路由表中的项目;否则:若收到的项目中的距离 d 小于路由表中的距离,则进行更新(例如原始路由表项为 Net2, 5, P,新表项为 Net2, 4, X,则更新);否则什么也不做。
- 若 3 分钟还没有收到相邻路由器的更新路由表,则把该相邻路由器标为不可达,即把距离置为 16。
RIP 协议实现简单,开销小。但是 RIP 能使用的最大距离为 15,限制了网络的规模。并且当网络出现故障时,要经过比较长的时间才能将此消息传送到所有路由器。
4.6.2.2 内部网关协议 OSPF
开放最短路径优先 OSPF,是为了克服 RIP 的缺点而开发出来的。
开放表示 OSPF 不受某一家厂商控制,而是公开发表的;最短路径优先表示使用了 Dijkstra 提出的最短路径算法 SPF。
OSPF 具有以下特点:
- 向本自治系统中的所有路由器发送信息,这种方法是洪泛法。
- 发送的信息就是与相邻路由器的链路状态,链路状态包括与哪些路由器相连以及链路的度量,度量用费用、距离、时延、带宽等来表示。
- 只有当链路状态发生变化时,路由器才会发送信息。
所有路由器都具有全网的拓扑结构图,并且是一致的。相比于 RIP,OSPF 的更新过程收敛的很快。
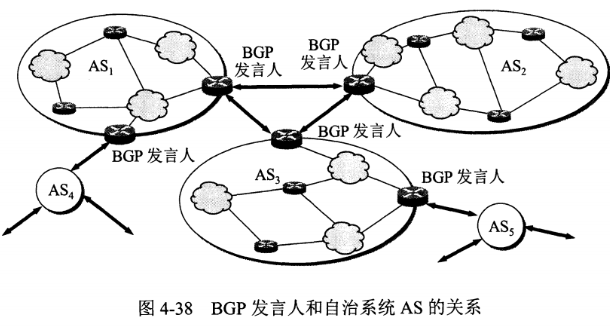
4.6.2.3 外部网关协议 BGP
BGP(Border Gateway Protocol,边界网关协议)
AS 之间的路由选择很困难,主要是由于:
- 互联网规模很大;
- 各个 AS 内部使用不同的路由选择协议,无法准确定义路径的度量;
- AS 之间的路由选择必须考虑有关的策略,比如有些 AS 不愿意让其它 AS 经过。
BGP 只能寻找一条比较好的路由,而不是最佳路由。
每个 AS 都必须配置 BGP 发言人,通过在两个相邻 BGP 发言人之间建立 TCP 连接来交换路由信息。
4.6.3 分组转发-具体流程
- 从数据报的首部提取目的主机的 IP 地址 D,得到目的网络地址 N。
- 若 N 就是与此路由器直接相连的某个网络地址,则进行直接交付;
- 若路由表中有目的地址为 D 的特定主机路由,则把数据报传送给表中所指明的下一跳路由器;
- 若路由表中有到达网络 N 的路由,则把数据报传送给路由表中所指明的下一跳路由器;
- 若路由表中有一个默认路由,则把数据报传送给路由表中所指明的默认路由器;
- 报告转发分组出错
5.传输层
网络层只把分组发送到目的主机,但是真正通信的并不是主机而是主机中的进程。传输层提供了进程间的逻辑通信,传输层向高层用户屏蔽了下面网络层的核心细节,使应用程序看起来像是在两个传输层实体之间有一条端到端的逻辑通信信道。
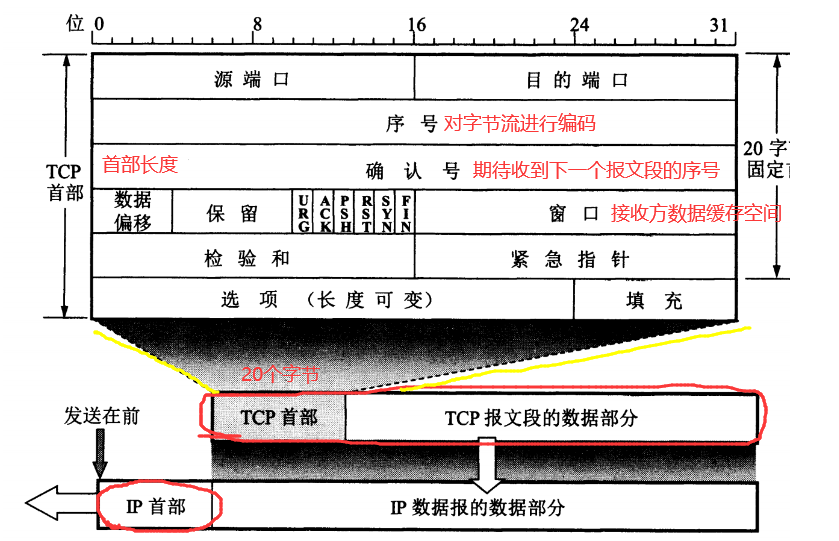
5.1 TCP 传输控制协议
传输控制协议 TCP(Transmission Control Protocol)是面向连接的,提供可靠交付,有流量控制,拥塞控制,提供全双工通信,面向字节流(把应用层传下来的报文看成字节流,把字节流组织成大小不等的数据块),每一条 TCP 连接只能是点对点的(一对一)。
TCP首部格式:
5.2 UDP 用户数据报协议
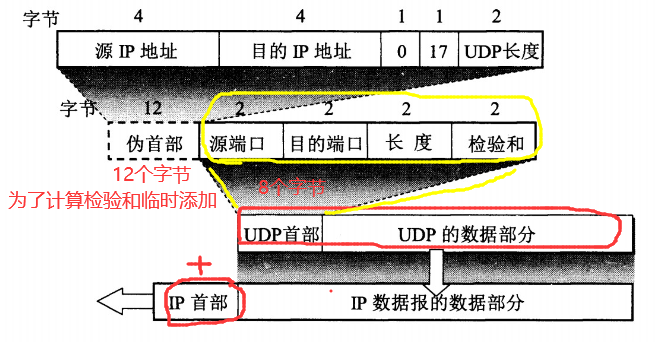
用户数据报协议 UDP(User Datagram Protocol)是无连接的,尽最大可能交付,没有拥塞控制,面向报文(对于应用程序传下来的报文不合并也不拆分,只是添加 UDP 首部),支持一对一、一对多、多对一和多对多的交互通信。
UDP首部格式:
5.3 TCP三次握手
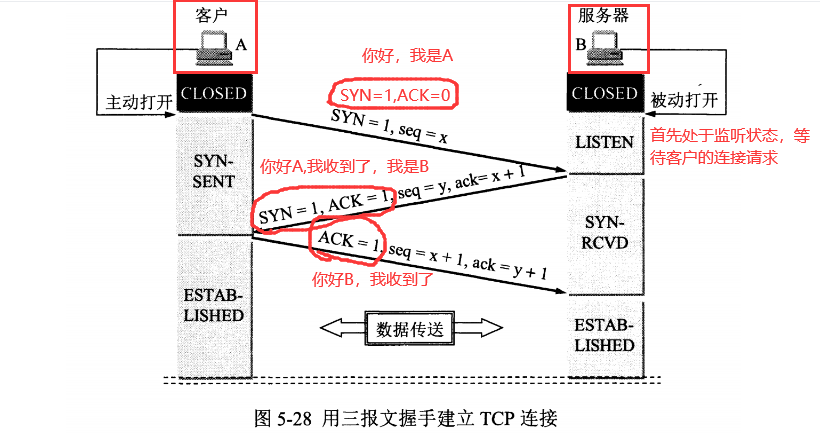
1 | 假设 A 为客户端,B 为服务器端 |
第三次握手是为了防止失效的连接请求到达服务器,让服务器错误打开连接。
客户端发送的连接请求如果在网络中滞留,那么就会隔很长一段时间才能收到服务器端发回的连接确认。客户端等待一个超时重传时间之后,就会重新请求连接。但是这个滞留的连接请求最后还是会到达服务器,如果不进行三次握手,那么服务器就会打开两个连接。如果有第三次握手,客户端会忽略服务器之后发送的对滞留连接请求的连接确认,不进行第三次握手,因此就不会再次打开连接。
5.4 TCP四次挥手
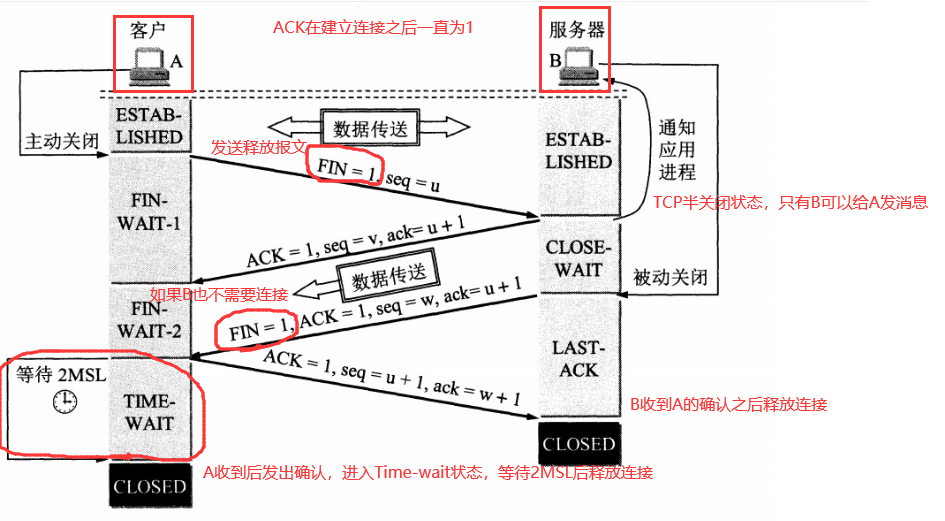
1 | 以下描述不讨论序号和确认号,因为序号和确认号的规则比较简单。并且不讨论 ACK,因为 ACK 在连接建立之后都为 1。 |
第四次挥手是因为客户端发送了 FIN 连接释放报文之后,服务器收到了这个报文,就进入了 CLOSE-WAIT 状态(这个状态是为了让服务器端发送还未传送完毕的数据,传送完毕之后,服务器会发送 FIN 连接释放报文)
其中TIME_WAIT状态:
客户端接收到服务器端的 FIN 报文后进入此状态,此时并不是直接进入 CLOSED 状态,还需要等待一个时间计时器设置的时间 2MSL。这么做有两个理由:
- 确保A给B发送的最后一个确认报文B收到了。如果 B 没收到 A 发送来的确认报文,那么就会重新发送连接释放请求报文,A 等待一段时间就是为了处理这种情况的发生。
- 为了让本连接持续时间内所产生的所有报文都从网络中消失,使得下一个新的连接不会出现旧的连接请求报文。
5.5 TCP三大特性
5.5.1 可靠传输
TCP使用超时重传来实现可靠传输:如果一个已经发送的报文段在超时时间内没有收到确认,那么就重传这个报文段。
一个报文段从发送再到接收到确认所经过的时间称为往返时间 RTT,加权平均往返时间 RTTs 计算如下:
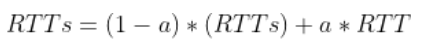
其中,0 ≤ a < 1,RTTs 随着 a 的增加更容易受到 RTT 的影响。
超时时间 RTO 应该略大于 RTTs,TCP 使用的超时时间计算如下:
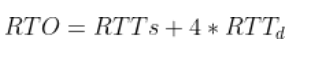
其中 RTTd 为偏差的加权平均值。
5.5.1.1 TCP滑动窗口
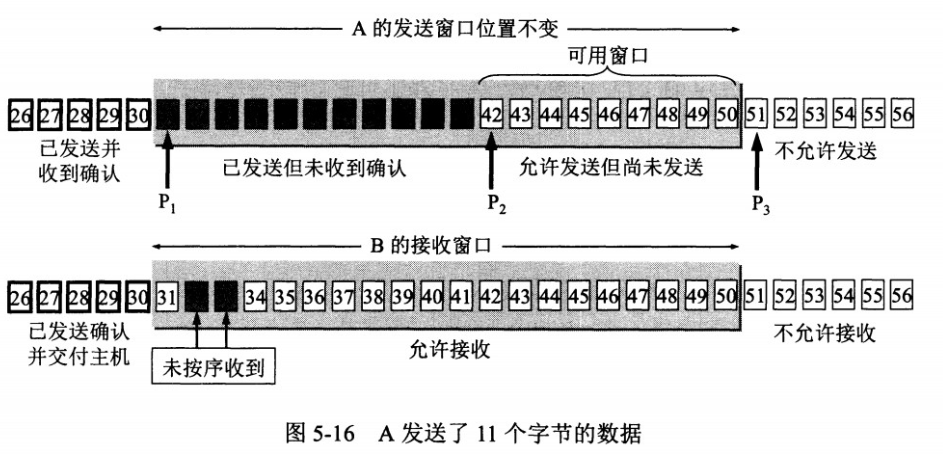
窗口是缓存的一部分,用来暂时存放字节流。发送方和接收方各有一个窗口,接收方通过 TCP 报文段中的窗口字段告诉发送方自己的窗口大小,发送方根据这个值和其它信息设置自己的窗口大小。
发送窗口内的字节都允许被发送,接收窗口内的字节都允许被接收。如果发送窗口左部的字节已经发送并且收到了确认,那么就将发送窗口向右滑动一定距离,直到左部第一个字节不是已发送并且已确认的状态;接收窗口的滑动类似,接收窗口左部字节已经发送确认并交付主机,就向右滑动接收窗口。
接收窗口只会对窗口内最后一个按序到达的字节进行确认,例如接收窗口已经收到的字节为 {31, 34, 35},其中 {31} 按序到达,而 {34, 35} 就不是,因此只对字节 31 进行确认。发送方得到一个字节的确认之后,就知道这个字节之前的所有字节都已经被接收。
5.5.2 流量控制
流量控制是为了控制发送方发送速率,保证接收方来得及接收。
接收方发送的确认报文中的窗口字段可以用来控制发送方窗口大小,从而影响发送方的发送速率。将窗口字段设置为 0,则发送方不能发送数据。
5.5.3 拥塞控制
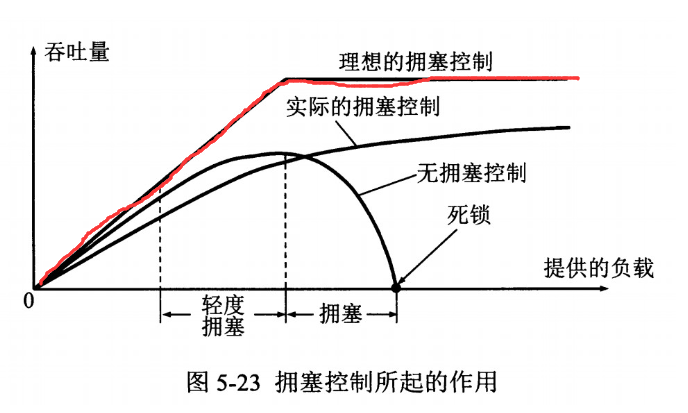
如果网络出现拥塞,分组将会丢失,此时发送方会继续重传,从而导致网络拥塞程度更高。因此当出现拥塞时,应当控制发送方的速率。这一点和流量控制很像,但是出发点不同。流量控制是为了让接收方能来得及接收,而拥塞控制是为了降低整个网络的拥塞程度。
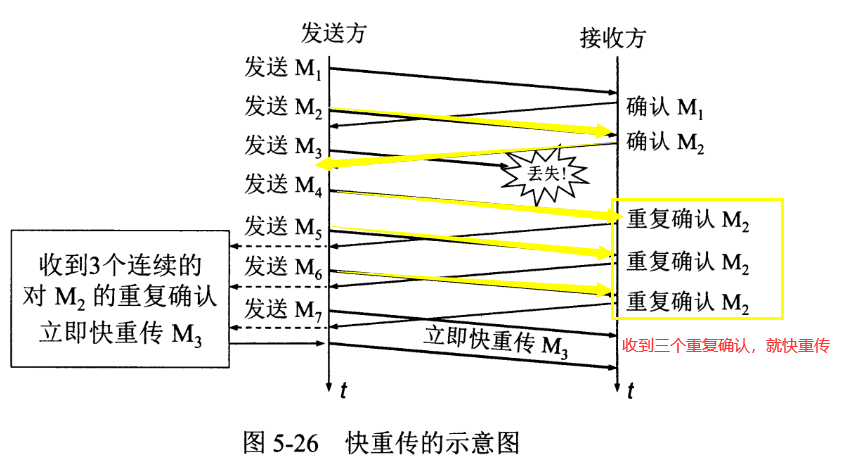
TCP 主要通过四个算法来进行拥塞控制:慢开始、拥塞避免、快重传、快恢复
- 慢开始和拥塞避免:
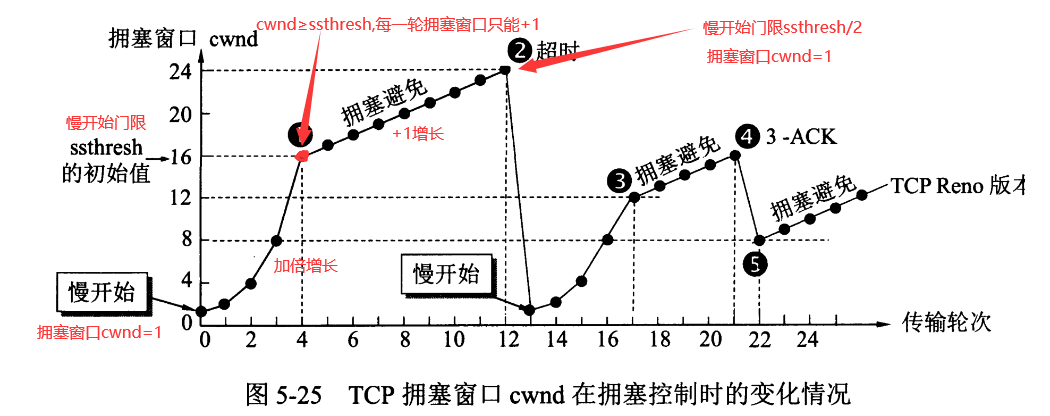
- 快恢复:
其中,快恢复和慢开始的区别就是慢开始的时候cwnd变为1重新开始,而快恢复是直接到cwnd=ssthresh,直接进入拥塞避免阶段
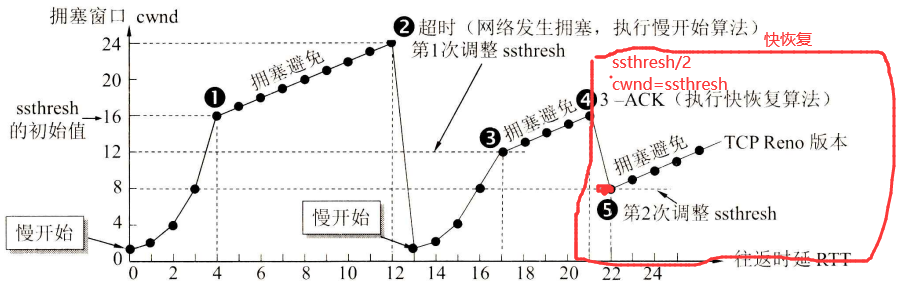
- 快重传:
6.应用层
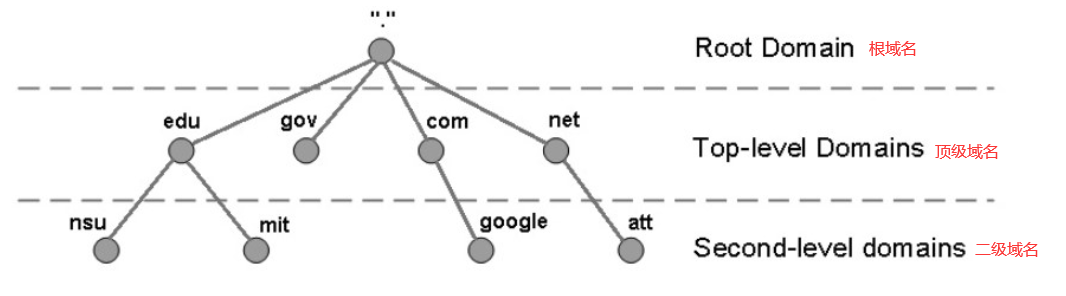
6.1 DNS 域名系统
DNS 是一个分布式数据库,提供了主机名和 IP 地址之间相互转换的服务。这里的分布式数据库是指,每个站点只保留它自己的那部分数据。
其中,域名具有层次结构,从上到下依次为:根域名、顶级域名、二级域名。
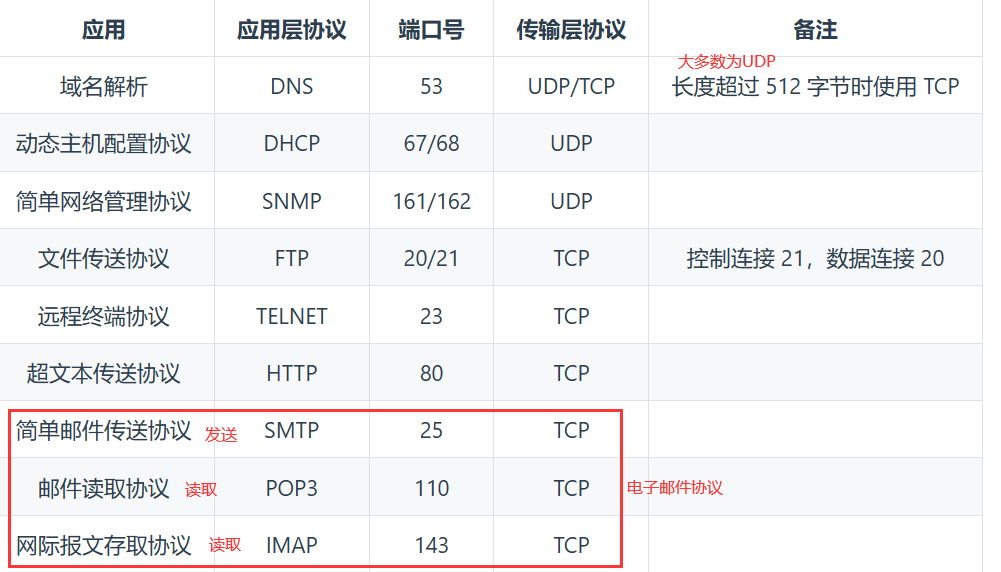
DNS 可以使用 UDP(大多数情况) / TCP 进行传输,使用的端口号都为 53。这就要求域名解析器和域名服务器都必须自己处理超时和重传从而保证可靠性。在两种情况下会使用 TCP 进行传输:
- 如果返回的响应超过的 512 字节(UDP 最大只支持 512 字节的数据)。
- 区域传送(区域传送是主域名服务器向辅助域名服务器传送变化的那部分数据)。
6.2 FTP 文件传输协议
FTP 使用 TCP 进行连接,它需要两个连接来传送一个文件:
- 控制连接:服务器打开端口号 21 等待客户端的连接,客户端主动建立连接后,使用这个连接将客户端的命令传送给服务器,并传回服务器的应答。
- 数据连接:用来传送一个文件数据。
根据数据连接是否是服务器端主动建立 –> FTP有主动模式和被动模式:
- 主动模式:服务器端主动建立数据连接,– 服务器端的端口号为 20,客户端的端口号随机,但是必须大于 1024(因为 0~1023 是熟知端口号)

- 被动模式:客户端主动建立数据连接,其中客户端的端口号由客户端自己指定,服务器端的端口号随机。

6.3 DHCP 动态主机配置协议
DHCP提供了即插即用的连网方式,用户不再需要手动配置 IP 地址(子网掩码,网关IP地址)
DHCP 工作过程如下:
- 客户端发送 Discover 报文,该报文的目的地址为 255.255.255.255:67,源地址为 0.0.0.0:68,被放入 UDP 中,该报文被广播到同一个子网的所有主机上。如果客户端和 DHCP 服务器不在同一个子网,就需要使用中继代理。
- DHCP 服务器收到 Discover 报文之后,发送 Offer 报文给客户端,该报文包含了客户端所需要的信息。因为客户端可能收到多个 DHCP 服务器提供的信息,因此客户端需要进行选择。
- 如果客户端选择了某个 DHCP 服务器提供的信息,那么就发送 Request 报文给该 DHCP 服务器。
- DHCP 服务器发送 Ack 报文,表示客户端此时可以使用提供给它的信息。
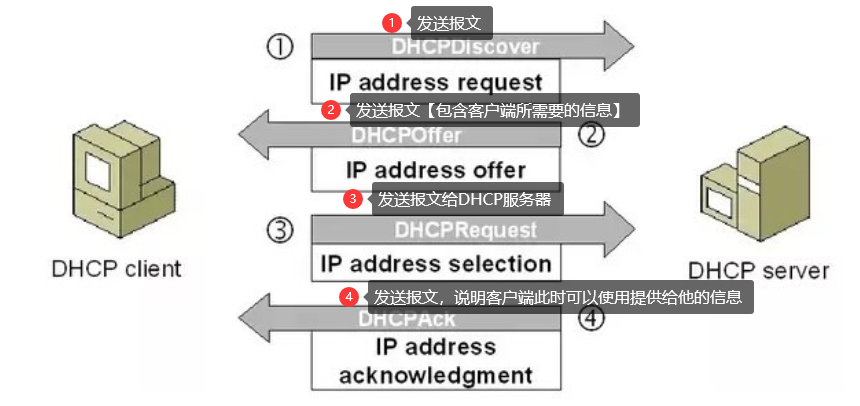
6.4 TELNET 远程登录协议
TELNET 用于登录到远程主机上,并且远程主机上的输出也会返回。
TELNET 可以适应许多计算机和操作系统的差异,例如不同操作系统系统的换行符定义。
6.5 电子邮件协议
一个电子邮件系统由三部分组成:用户代理、邮件服务器以及邮件协议。
| 三个部分 | 分类 | 举例 |
|---|---|---|
| 用户代理 | ||
| 邮件服务器 | ||
| 邮件协议 | 发送协议和读取协议 | 1.发送协议:SMTP 2.读取协议:POP3和IMAP |
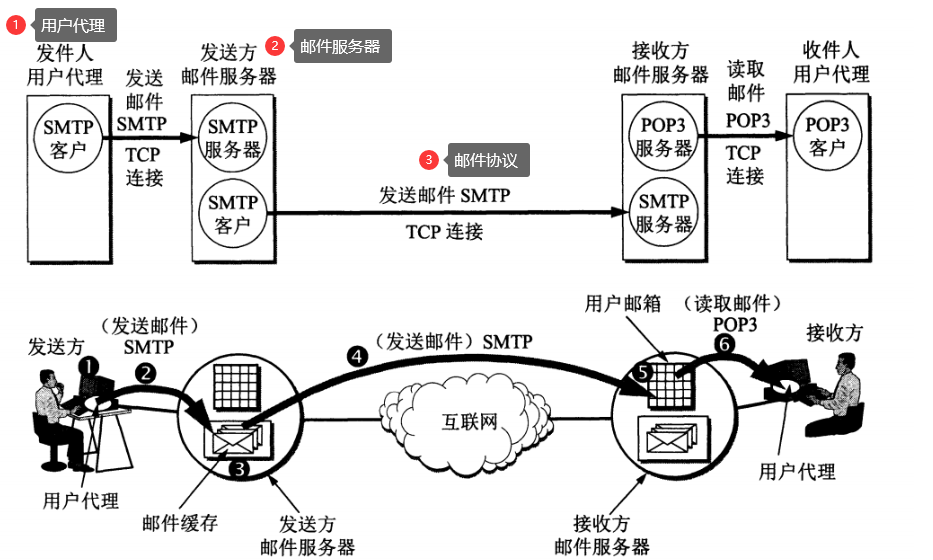
6.5.1 SMTP
SMTP 只能发送 ASCII 码,而互联网邮件扩充 MIME 可以发送二进制文件。MIME 并没有改动或者取代 SMTP,而是增加邮件主体的结构,定义了非 ASCII 码的编码规则。

6.5.2 POP3
只要用户从服务器上读取了邮件,就把该邮件删除。
6.5.3 IMAP
IMAP 协议中客户端和服务器上的邮件保持同步,如果不手动删除邮件,那么服务器上的邮件也不会被删除。IMAP 这种做法可以让用户随时随地去访问服务器上的邮件。
7.常用端口
8.Web页面请求过程

- 1.浏览器会对url进行解析:从而生成发送给web服务器的请求信息
- 2.DNS域名解析出IP地址:本地DNS将该域名和对应的IP地址写入自身缓存,然后将解析的IP地址返回给客户端
- 3.浏览器和服务器进行三次握手:建立连接
- 4.浏览器向服务器端发生HTTP请求报文:第一步对 URL 进行解析之后,浏览器确定了 Web 服务器和文件名,接下来就是根据这些信息来生成 HTTP 请求消息了,此时则可以发送HTTP请求报文
- 5.服务器端向浏览器发送HTTP响应报文和首页HTML文件:
- 6.浏览器渲染HTML页面:
- 7.浏览器和服务器进行四次挥手:断开连接
JAVA-网络编程
第16章_网络编程
本章专题与脉络
1. 网络编程概述
Java是 Internet 上的语言,它从语言级上提供了对网络应用程序的支持,程序员能够很容易开发常见的网络应用程序。
Java提供的网络类库,可以实现无痛的网络连接,联网的底层细节被隐藏在 Java 的本机安装系统里,由 JVM 控制。并且 Java 实现了一个跨平台的网络库,程序员面对的是一个统一的网络编程环境。
1.1 软件架构
- C/S架构 :全称为Client/Server结构,是指客户端和服务器结构。常见程序有QQ、美团app、360安全卫士等软件。

B/S架构 :全称为Browser/Server结构,是指浏览器和服务器结构。常见浏览器有IE、谷歌、火狐等。

两种架构各有优势,但是无论哪种架构,都离不开网络的支持。网络编程,就是在一定的协议下,实现两台计算机的通信的程序。
1.2 网络基础
计算机网络:
把分布在不同地理区域的计算机与专门的外部设备用通信线路互连成一个规模大、功能强的网络系统,从而使众多的计算机可以方便地互相传递信息、共享硬件、软件、数据信息等资源。网络编程的目的:直接/间接地通过网络协议与其它计算机实现数据交换,进行通讯。
网络编程中有三个主要的问题:
- 问题1:如何准确地定位网络上一台或多台主机(去看病如何找到你?) —使用IP地址(找到你)
- 问题2:如何定位主机上的特定的应用(找到你之后如何判断是哪里有病?) —使用端口号(定位你身上特定的位置)
- 问题3:找到主机后,如何可靠、高效地进行数据传输(确定病因如何用药?) —规范网络通信协议(可靠、高效地进行数据传输)
2. 网络通信要素
2.1 如何实现网络中的主机互相通信
- 通信双方地址
- IP
- 端口号
- 一定的规则:不同的硬件、操作系统之间的通信,所有的这一切都需要一种规则。而我们就把这种规则称为协议,即网络通信协议。
生活类比:


2.2 通信要素一:IP地址和域名
2.2.1 IP地址
IP地址:指互联网协议地址(Internet Protocol Address),俗称IP。IP地址用来给网络中的一台计算机设备做唯一的编号。假如我们把“个人电脑”比作“一台电话”的话,那么“IP地址”就相当于“电话号码”。
IP地址分类方式一:
IPv4:是一个32位的二进制数,通常被分为4个字节,表示成a.b.c.d的形式,以点分十进制表示,例如192.168.65.100。其中a、b、c、d都是0~255之间的十进制整数。
这种方式最多可以表示42亿个。其中,30亿都在北美,亚洲4亿,中国2.9亿。2011年初已经用尽。
IP地址 = 网络地址 +主机地址
- 网络地址:标识计算机或网络设备所在的网段
主机地址:标识特定主机或网络设备
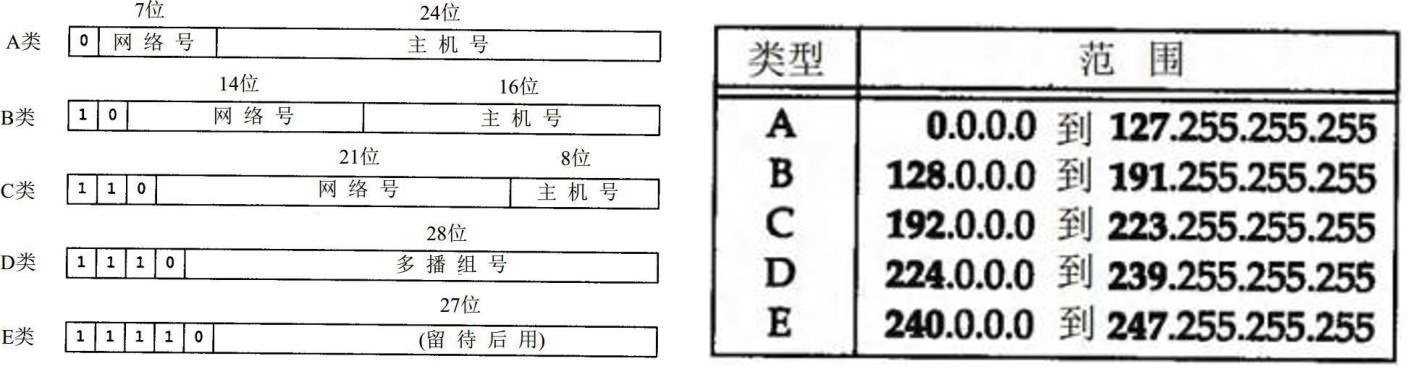
其中,E类用于科研。
IPv6:由于互联网的蓬勃发展,IP地址的需求量愈来愈大,但是网络地址资源有限,使得IP的分配越发紧张。 为了扩大地址空间,拟通过IPv6重新定义地址空间,采用128位地址长度,共16个字节,写成8个无符号整数,每个整数用四个十六进制位表示,数之间用冒号(:)分开。
比如:ABCD:EF01:2345:6789:ABCD:EF01:2345:6789,按保守方法估算IPv6实际可分配的地址,整个地球的每平方米面积上仍可 分配1000多个地址,这样就解决了网络地址资源数量不够的问题。2012年6月6日,国际互联网协会举行了世界IPv6启动纪念日,这一天,全球IPv6网络正式启动。多家知名网站,如Google、Facebook和Yahoo等,于当天全球标准时间0点(北京时间8点整)开始永久性支持IPv6访问。2018年6月,三大运营商联合阿里云宣布,将全面对外提供IPv6服务,并计划在2025年前助推中国互联网真正实现“IPv6 Only”。在IPv6的设计过程中除了一劳永逸地解决了地址短缺问题以外,还考虑了在IPv4中解决不好的其它问题,主要有端到端IP连接、服务质量(QoS)、安全性、多播、移动性、即插即用等。
IP地址分类方式二:
公网地址( 万维网使用)和 私有地址( 局域网使用)。192.168.开头的就是私有地址,范围即为192.168.0.0–192.168.255.255,专门为组织机构内部使用。
常用命令:
- 查看本机IP地址,在控制台输入:
1 | ipconfig |
- 检查网络是否连通,在控制台输入:
1 | ping 空格 IP地址 |
特殊的IP地址:
- 本地回环地址(hostAddress):
127.0.0.1 - 主机名(hostName):
localhost
2.2.2 域名
Internet上的主机有两种方式表示地址:
- 域名(hostName):www.atguigu.com
- IP 地址(hostAddress):202.108.35.210
域名解析:因为IP地址数字不便于记忆,因此出现了域名。域名容易记忆,当在连接网络时输入一个主机的域名后,域名服务器(DNS,Domain Name System,域名系统)负责将域名转化成IP地址,这样才能和主机建立连接。
简单理解:
详细理解:
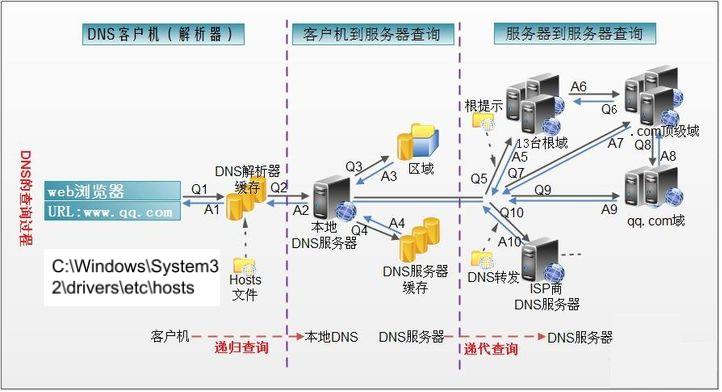
- 在浏览器中输入www . qq .com 域名,操作系统会先检查自己本地的
hosts文件是否有这个网址映射关系,如果有,就先调用这个IP地址映射,完成域名解析。 - 如果hosts里没有这个域名的映射,则查找
本地DNS解析器缓存,是否有这个网址映射关系,如果有,直接返回,完成域名解析。 - 如果hosts与本地DNS解析器缓存都没有相应的网址映射关系,首先会找TCP/IP参数中设置的首选DNS服务器,在此我们叫它
本地DNS服务器,此服务器收到查询时,如果要查询的域名,包含在本地配置区域资源中,则返回解析结果给客户机,完成域名解析,此解析具有权威性。 - 如果要查询的域名,不由本地DNS服务器区域解析,但该服务器已
缓存了此网址映射关系,则调用这个IP地址映射,完成域名解析,此解析不具有权威性。 - 如果本地DNS服务器本地区域文件与缓存解析都失效,则根据本地DNS服务器的设置(是否设置转发器)进行查询,如果未用转发模式,本地DNS就把请求发至13台根DNS,根DNS服务器收到请求后会判断这个域名(.com)是谁来授权管理,并会返回一个负责该顶级域名服务器的一个IP。本地DNS服务器收到IP信息后,将会联系负责.com域的这台服务器。这台负责.com域的服务器收到请求后,如果自己无法解析,它就会找一个管理.com域的下一级DNS服务器地址(http://qq.com)给本地DNS服务器。当本地DNS服务器收到这个地址后,就会找(http://qq.com)域服务器,重复上面的动作,进行查询,直至找到www.qq.com主机。
- 如果用的是转发模式,此DNS服务器就会把请求转发至上一级DNS服务器,由上一级服务器进行解析,上一级服务器如果不能解析,或找根DNS或把转请求转至上上级,以此循环。不管是本地DNS服务器用是是转发,还是根提示,最后都是把结果返回给本地DNS服务器,由此DNS服务器再返回给客户机。
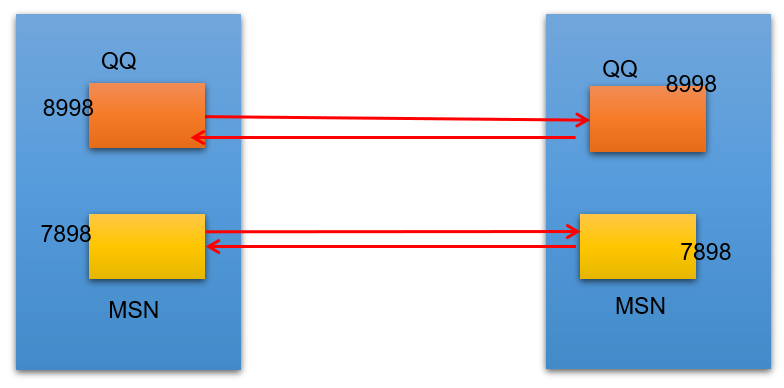
2.3 通信要素二:端口号
网络的通信,本质上是两个进程(应用程序)的通信。每台计算机都有很多的进程,那么在网络通信时,如何区分这些进程呢?
如果说IP地址可以唯一标识网络中的设备,那么端口号就可以唯一标识设备中的进程(应用程序)。
不同的进程,设置不同的端口号。
- 端口号:用两个字节表示的整数,它的取值范围是0~65535。
- 公认端口:0~1023。被预先定义的服务通信占用,如:HTTP(80),FTP(21),Telnet(23)
- 注册端口:1024~49151。分配给用户进程或应用程序。如:Tomcat(8080),MySQL(3306),Oracle(1521)。
- 动态/ 私有端口:49152~65535。
如果端口号被另外一个服务或应用所占用,会导致当前程序启动失败。
2.4 通信要素三:网络通信协议
通过计算机网络可以使多台计算机实现连接,位于同一个网络中的计算机在进行连接和通信时需要遵守一定的规则,这就好比在道路中行驶的汽车一定要遵守交通规则一样。
网络通信协议:在计算机网络中,这些连接和通信的规则被称为网络通信协议,它对数据的传输格式、传输速率、传输步骤、出错控制等做了统一规定,通信双方必须同时遵守才能完成数据交换。
新的问题:网络协议涉及内容太多、太复杂。如何解决?
计算机网络通信涉及内容很多,比如指定源地址和目标地址,加密解密,压缩解压缩,差错控制,流量控制,路由控制,如何实现如此复杂的网络协议呢?通信协议分层思想。
在制定协议时,把复杂成份分解成一些简单的成份,再将它们复合起来。最常用的复合方式是层次方式,即同层间可以通信、上一层可以调用下一层,而与再下一层不发生关系。各层互不影响,利于系统的开发和扩展。
这里有两套参考模型
- OSI参考模型:模型过于理想化,未能在因特网上进行广泛推广
- TCP/IP参考模型(或TCP/IP协议):事实上的国际标准。

上图中,OSI参考模型:模型过于理想化,未能在因特网上进行广泛推广。 TCP/IP参考模型(或TCP/IP协议):事实上的国际标准。
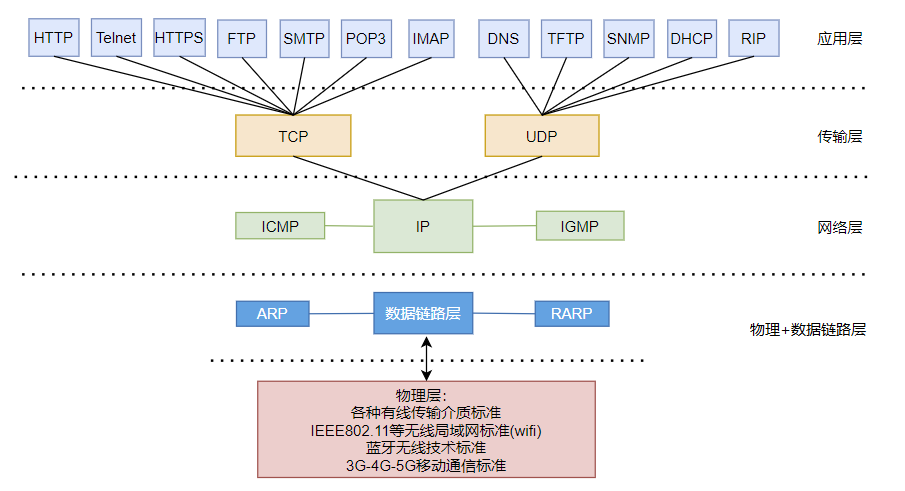
TCP/IP协议: 传输控制协议/因特网互联协议( Transmission Control Protocol/Internet Protocol),TCP/IP 以其两个主要协议:传输控制协议(TCP)和网络互联协议(IP)而得名,实际上是一组协议,包括多个具有不同功能且互为关联的协议。是Internet最基本、最广泛的协议。
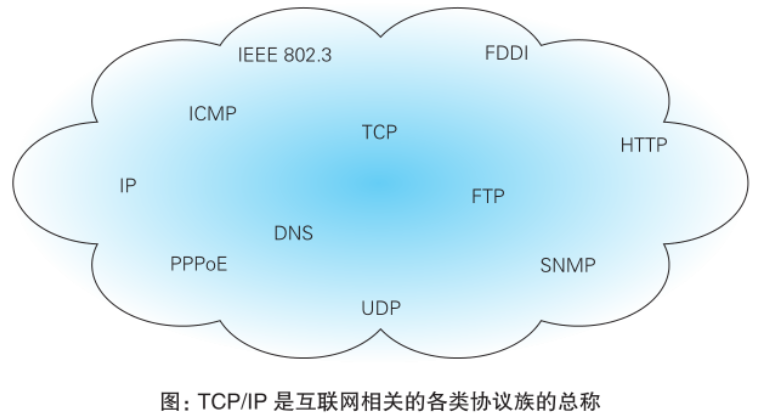
TCP/IP协议中的四层介绍:
应用层:应用层决定了向用户提供应用服务时通信的活动。主要协议有:HTTP协议、FTP协议、SNMP(简单网络管理协议)、SMTP(简单邮件传输协议)和POP3(Post Office Protocol 3的简称,即邮局协议的第3个版)等。传输层:主要使网络程序进行通信,在进行网络通信时,可以采用TCP协议,也可以采用UDP协议。TCP(Transmission Control Protocol)协议,即传输控制协议,是一种面向连接的、可靠的、基于字节流的传输层通信协议。UDP(User Datagram Protocol,用户数据报协议):是一个无连接的传输层协议、提供面向事务的简单不可靠的信息传送服务。网络层:网络层是整个TCP/IP协议的核心,支持网间互连的数据通信。它主要用于将传输的数据进行分组,将分组数据发送到目标计算机或者网络。而IP协议是一种非常重要的协议。IP(internet protocal)又称为互联网协议。IP的责任就是把数据从源传送到目的地。它在源地址和目的地址之间传送一种称之为数据包的东西,它还提供对数据大小的重新组装功能,以适应不同网络对包大小的要求。
物理+数据链路层:链路层是用于定义物理传输通道,通常是对某些网络连接设备的驱动协议,例如针对光纤、网线提供的驱动。
2. 谈传输层协议:TCP与UDP协议
通信的协议还是比较复杂的,java.net 包中包含的类和接口,它们提供低层次的通信细节。我们可以直接使用这些类和接口,来专注于网络程序开发,而不用考虑通信的细节。
java.net 包中提供了两种常见的网络协议的支持:
- UDP:用户数据报协议(User Datagram Protocol)。
- TCP:传输控制协议 (Transmission Control Protocol)。
2.1 TCP协议与UDP协议
TCP协议:
- TCP协议进行通信的两个应用进程:客户端、服务端。
- 使用TCP协议前,须先
建立TCP连接,形成基于字节流的传输数据通道 - 传输前,采用“三次握手”方式,点对点通信,是
可靠的- TCP协议使用
重发机制,当一个通信实体发送一个消息给另一个通信实体后,需要收到另一个通信实体确认信息,如果没有收到另一个通信实体确认信息,则会再次重复刚才发送的消息。
- TCP协议使用
- 在连接中可进行
大数据量的传输 - 传输完毕,需
释放已建立的连接,效率低
UDP协议:
- UDP协议进行通信的两个应用进程:发送端、接收端。
- 将数据、源、目的封装成数据包(传输的基本单位),
不需要建立连接 - 发送不管对方是否准备好,接收方收到也不确认,不能保证数据的完整性,故是
不可靠的 - 每个数据报的大小限制在
64K内 - 发送数据结束时
无需释放资源,开销小,通信效率高 - 适用场景:音频、视频和普通数据的传输。例如视频会议
TCP生活案例:打电话
UDP生活案例:发送短信、发电报
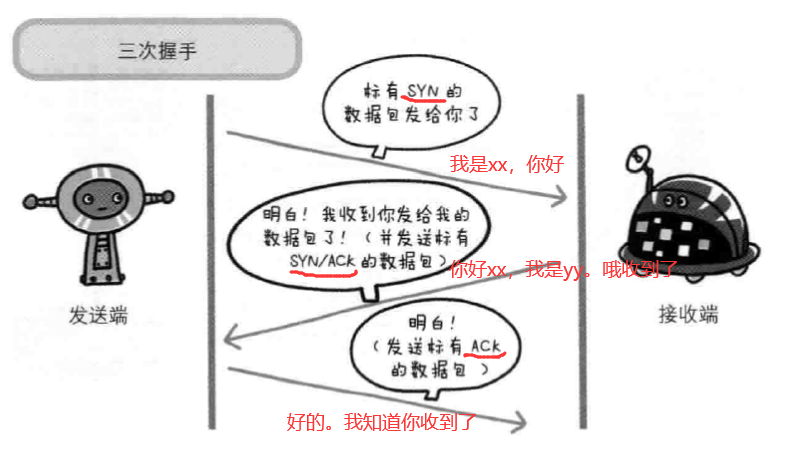
2.2 三次握手
TCP协议中,在发送数据的准备阶段,客户端与服务器之间的三次交互,以保证连接的可靠。
- 第一次握手,客户端向服务器端发起TCP连接的请求
- 第二次握手,服务器端发送针对客户端TCP连接请求的确认
- 第三次握手,客户端发送确认的确认
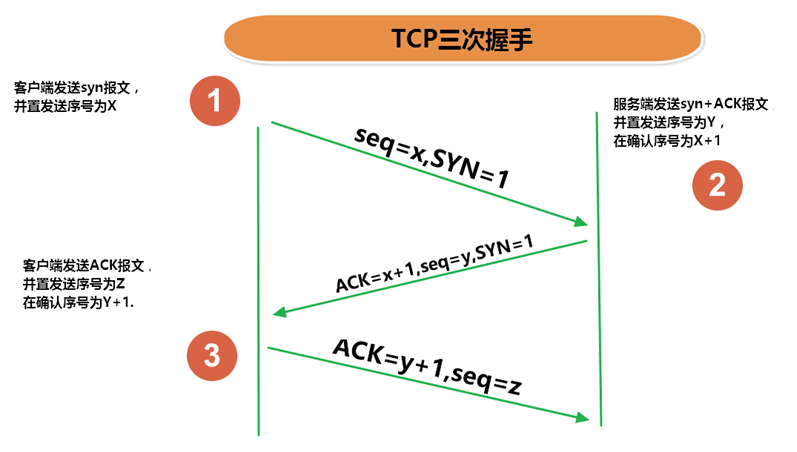
1、客户端会随机一个初始序列号seq=x,设置SYN=1 ,表示这是SYN握手报文。然后就可以把这个 SYN 报文发送给服务端了,表示向服务端发起连接,之后客户端处于
同步已发送状态。2、服务端收到客户端的 SYN 报文后,也随机一个初始序列号(seq=y),设置ack=x+1,表示收到了客户端的x之前的数据,希望客户端下次发送的数据从x+1开始。
设置 SYN=1 和 ACK=1。表示这是一个SYN握手和ACK确认应答报文。最后把该报文发给客户端,该报文也不包含应用层数据,之后服务端处于同步已接收状态。3、客户端收到服务端报文后,还要向服务端回应最后一个应答报文,将ACK置为 1 ,表示这是一个应答报文
ack=y+1 ,表示收到了服务器的y之前的数据,希望服务器下次发送的数据从y+1开始。
最后把报文发送给服务端,这次报文可以携带数据,之后客户端处于 连接已建立 状态。服务器收到客户端的应答报文后,也进入连接已建立状态。
完成三次握手,连接建立后,客户端和服务器就可以开始进行数据传输了。由于这种面向连接的特性,TCP协议可以保证传输数据的安全,所以应用十分广泛,例如下载文件、浏览网页等。
2.3 四次挥手
TCP协议中,在发送数据结束后,释放连接时需要经过四次挥手。
- 第一次挥手:客户端向服务器端提出结束连接,
让服务器做最后的准备工作。此时,客户端处于半关闭状态,即表示不再向服务器发送数据了,但是还可以接受数据。 - 第二次挥手:服务器接收到客户端释放连接的请求后,
会将最后的数据发给客户端。并告知上层的应用进程不再接收数据。 - 第三次挥手:服务器发送完数据后,会给客户端
发送一个释放连接的报文。那么客户端接收后就知道可以正式释放连接了。 - 第四次挥手:客户端接收到服务器最后的释放连接报文后,要
回复一个彻底断开的报文。这样服务器收到后才会彻底释放连接。这里客户端,发送完最后的报文后,会等待2MSL,因为有可能服务器没有收到最后的报文,那么服务器迟迟没收到,就会再次给客户端发送释放连接的报文,此时客户端在等待时间范围内接收到,会重新发送最后的报文,并重新计时。如果等待2MSL后,没有收到,那么彻底断开。
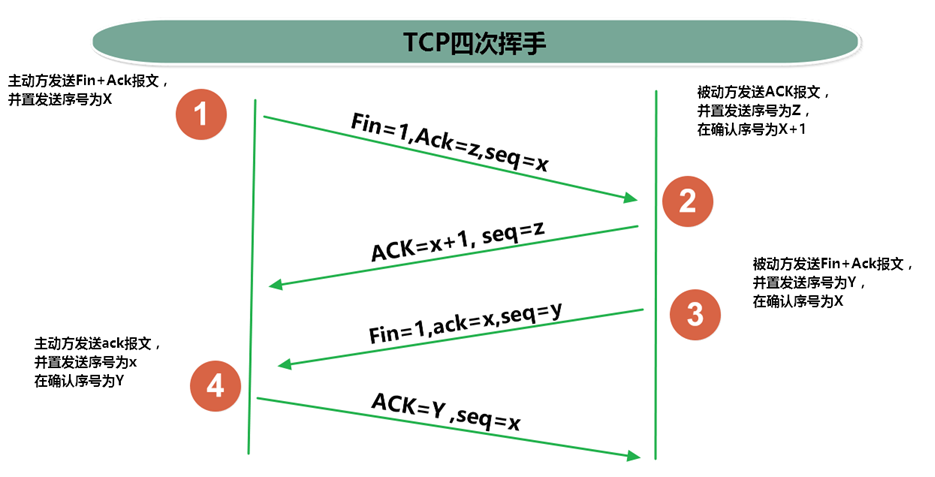
1、客户端打算断开连接,向服务器发送FIN报文(FIN标记位被设置为1,1表示为FIN,0表示不是),FIN报文中会指定一个序列号,之后客户端进入FIN_WAIT_1状态。也就是客户端发出连接释放报文段(FIN报文),指定序列号seq = u,主动关闭TCP连接,等待服务器的确认。
2、服务器收到连接释放报文段(FIN报文)后,就向客户端发送ACK应答报文,以客户端的FIN报文的序列号 seq+1 作为ACK应答报文段的确认序列号ack = seq+1 = u + 1。接着服务器进入CLOSE_WAIT(等待关闭)状态,此时的TCP处于半关闭状态(下面会说什么是半关闭状态),客户端到服务器的连接释放。客户端收到来自服务器的ACK应答报文段后,进入FIN_WAIT_2状态。
3、服务器也打算断开连接,向客户端发送连接释放(FIN)报文段,之后服务器进入LASK_ACK(最后确认)状态,等待客户端的确认。服务器的连接释放(FIN)报文段的FIN=1,ACK=1,序列号seq=m,确认序列号ack=u+1。
4、客户端收到来自服务器的连接释放(FIN)报文段后,会向服务器发送一个ACK应答报文段,以连接释放(FIN)报文段的确认序号 ack 作为ACK应答报文段的序列号 seq,以连接释放(FIN)报文段的序列号 seq+1作为确认序号ack。
之后客户端进入TIME_WAIT(时间等待)状态,服务器收到ACK应答报文段后,服务器就进入CLOSE(关闭)状态,到此服务器的连接已经完成关闭。客户端处于TIME_WAIT状态时,此时的TCP还未释放掉,需要等待2MSL后,客户端才进入CLOSE状态。
3. 网络编程API
3.1 InetAddress类
InetAddress类主要表示IP地址,两个子类:Inet4Address、Inet6Address。
InetAddress 类没有提供公共的构造器,而是提供如下几个静态方法来获取InetAddress 实例
- public static InetAddress getLocalHost()
- public static InetAddress getByName(String host)
- public static InetAddress getByAddress(byte[] addr)
InetAddress 提供了如下几个常用的方法
- public String getHostAddress() :返回 IP 地址字符串(以文本表现形式)
- public String getHostName() :获取此 IP 地址的主机名
- public boolean isReachable(int timeout):测试是否可以达到该地址
1 | import java.net.InetAddress; |

3.2 Socket类
- 具有唯一标识的IP地址+端口号 –组合–> 构成唯一能识别的标识符套接字(Socket)。
- 利用套接字(Socket)开发网络应用程序早已被广泛的采用,以至于成为事实上的标准。网络通信其实就是Socket间的通信。
通信的两端都要有Socket,是两台机器间通信的端点。
Socket允许程序把网络连接当成一个流,数据在两个Socket间通过IO传输。
一般主动发起通信的应用程序属客户端,等待通信请求的为服务端。
Socket分类:
- 流套接字(stream socket):使用TCP提供可依赖的字节流服务
- ServerSocket:此类实现TCP服务器套接字。服务器套接字等待请求通过网络传入。
- Socket:此类实现客户端套接字(也可以就叫“套接字”)。套接字是两台机器间通信的端点。
- 数据报套接字(datagram socket):使用UDP提供“尽力而为”的数据报服务
- DatagramSocket:此类表示用来发送和接收UDP数据报包的套接字。
- 流套接字(stream socket):使用TCP提供可依赖的字节流服务
3.3 Socket相关类API
3.3.1 ServerSocket类
ServerSocket类的构造方法:
- ServerSocket(int port) :创建绑定到特定端口的服务器套接字。
ServerSocket类的常用方法:
- Socket accept():侦听并接受到此套接字的连接。
3.3.2 Socket类
Socket类的常用构造方法:
- public Socket(InetAddress address,int port):创建一个流套接字并将其连接到指定 IP 地址的指定端口号。
- public Socket(String host,int port):创建一个流套接字并将其连接到指定主机上的指定端口号。
Socket类的常用方法:
- public InputStream getInputStream():返回此套接字的输入流,可以用于接收消息
- public OutputStream getOutputStream():返回此套接字的输出流,可以用于发送消息
- public InetAddress getInetAddress():此套接字连接到的远程 IP 地址;如果套接字是未连接的,则返回 null。
- public InetAddress getLocalAddress():获取套接字绑定的本地地址。
- public int getPort():此套接字连接到的远程端口号;如果尚未连接套接字,则返回 0。
- public int getLocalPort():返回此套接字绑定到的本地端口。如果尚未绑定套接字,则返回 -1。
- public void close():关闭此套接字。套接字被关闭后,便不可在以后的网络连接中使用(即无法重新连接或重新绑定)。需要创建新的套接字对象。 关闭此套接字也将会关闭该套接字的 InputStream 和 OutputStream。
- public void shutdownInput():如果在套接字上调用 shutdownInput() 后从套接字输入流读取内容,则流将返回 EOF(文件结束符)。 即不能在从此套接字的输入流中接收任何数据。
- public void shutdownOutput():禁用此套接字的输出流。对于 TCP 套接字,任何以前写入的数据都将被发送,并且后跟 TCP 的正常连接终止序列。 如果在套接字上调用 shutdownOutput() 后写入套接字输出流,则该流将抛出 IOException。 即不能通过此套接字的输出流发送任何数据。
注意:先后调用Socket的shutdownInput()和shutdownOutput()方法,仅仅关闭了输入流和输出流,并不等于调用Socket的close()方法。在通信结束后,仍然要调用Scoket的close()方法,因为只有该方法才会释放Socket占用的资源,比如占用的本地端口号等。
3.3.3 DatagramSocket类
DatagramSocket 类的常用方法:
- public DatagramSocket(int port)创建数据报套接字并将其绑定到本地主机上的指定端口。套接字将被绑定到通配符地址,IP 地址由内核来选择。
- public DatagramSocket(int port,InetAddress laddr)创建数据报套接字,将其绑定到指定的本地地址。本地端口必须在 0 到 65535 之间(包括两者)。如果 IP 地址为 0.0.0.0,套接字将被绑定到通配符地址,IP 地址由内核选择。
- public void close()关闭此数据报套接字。
- public void send(DatagramPacket p)从此套接字发送数据报包。DatagramPacket 包含的信息指示:将要发送的数据、其长度、远程主机的 IP 地址和远程主机的端口号。
- public void receive(DatagramPacket p)从此套接字接收数据报包。当此方法返回时,DatagramPacket 的缓冲区填充了接收的数据。数据报包也包含发送方的 IP 地址和发送方机器上的端口号。 此方法在接收到数据报前一直阻塞。数据报包对象的 length 字段包含所接收信息的长度。如果信息比包的长度长,该信息将被截短。
- public InetAddress getLocalAddress()获取套接字绑定的本地地址。
- public int getLocalPort()返回此套接字绑定的本地主机上的端口号。
- public InetAddress getInetAddress()返回此套接字连接的地址。如果套接字未连接,则返回 null。
- public int getPort()返回此套接字的端口。如果套接字未连接,则返回 -1。
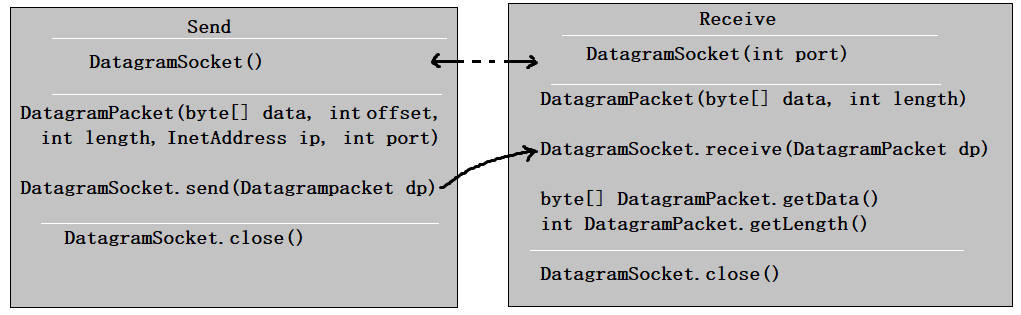
3.3.4 DatagramPacket类
DatagramPacket类的常用方法:
- public DatagramPacket(byte[] buf,int length)构造 DatagramPacket,用来接收长度为 length 的数据包。 length 参数必须小于等于 buf.length。
- public DatagramPacket(byte[] buf,int length,InetAddress address,int port)构造数据报包,用来将长度为 length 的包发送到指定主机上的指定端口号。length 参数必须小于等于 buf.length。
- public InetAddress getAddress()返回某台机器的 IP 地址,此数据报将要发往该机器或者是从该机器接收到的。
- public int getPort()返回某台远程主机的端口号,此数据报将要发往该主机或者是从该主机接收到的。
public byte[] getData()返回数据缓冲区。接收到的或将要发送的数据从缓冲区中的偏移量 offset 处开始,持续 length 长度。public int getLength()返回将要发送或接收到的数据的长度。
4. TCP网络编程
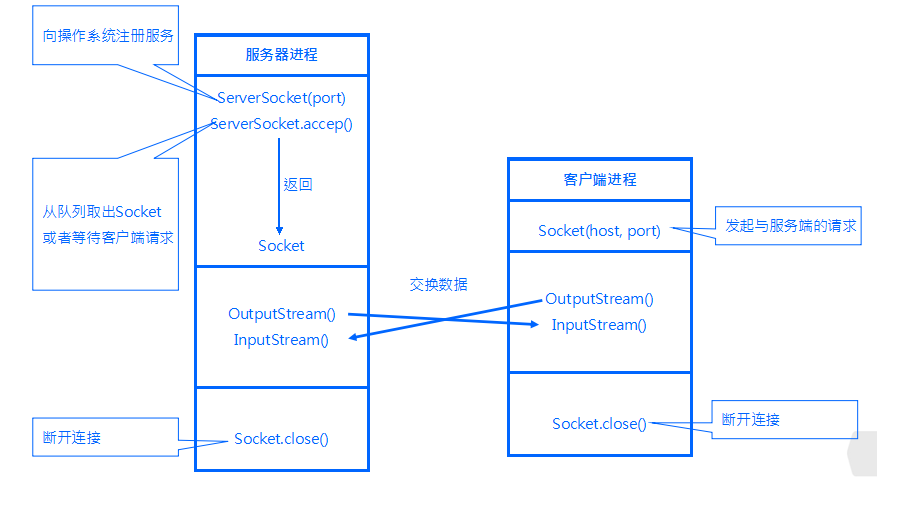
4.1 通信模型
Java语言的基于套接字TCP编程分为服务端编程和客户端编程,其通信模型如图所示:
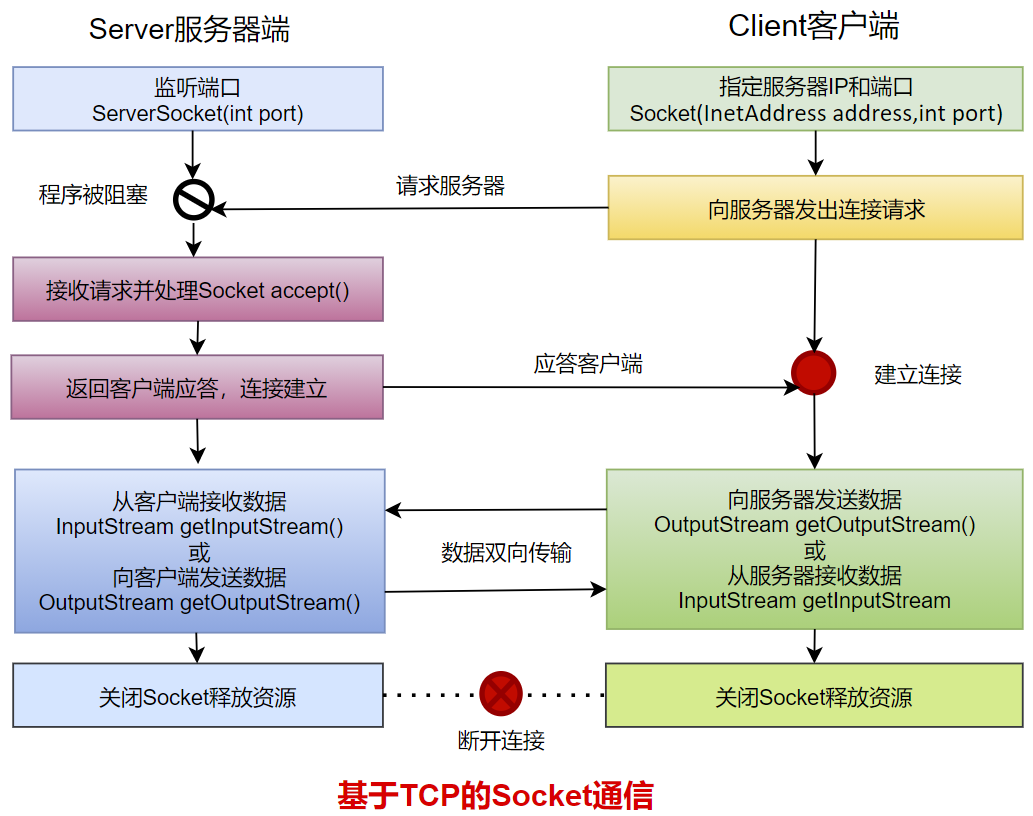
4.2 开发步骤
客户端程序包含以下四个基本的步骤 :
- 创建 Socket :根据指定服务端的 IP 地址或端口号构造 Socket 类对象。若服务器端响应,则建立客户端到服务器的通信线路。若连接失败,会出现异常。
- 打开连接到 Socket 的输入/ 出流: 使用 getInputStream()方法获得输入流,使用getOutputStream()方法获得输出流,进行数据传输
- 按照一定的协议对 Socket 进行读/ 写操作:通过输入流读取服务器放入线路的信息(但不能读取自己放入线路的信息),通过输出流将信息写入线路。
- 关闭 Socket :断开客户端到服务器的连接,释放线路
服务器端程序包含以下四个基本的 步骤:
- 调用 ServerSocket(int port) :创建一个服务器端套接字,并绑定到指定端口上。用于监听客户端的请求。
- 调用 accept() :监听连接请求,如果客户端请求连接,则接受连接,返回通信套接字对象。
- 调用 该Socket 类对象的 getOutputStream() 和 getInputStream () :获取输出流和输入流,开始网络数据的发送和接收。
- 关闭Socket 对象:客户端访问结束,关闭通信套接字。
4.3 例题与练习
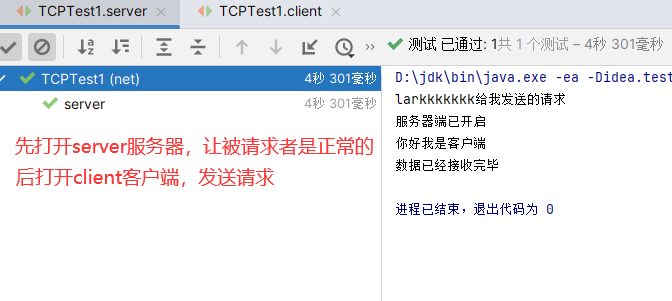
例题1:
1 | import org.junit.Test; |
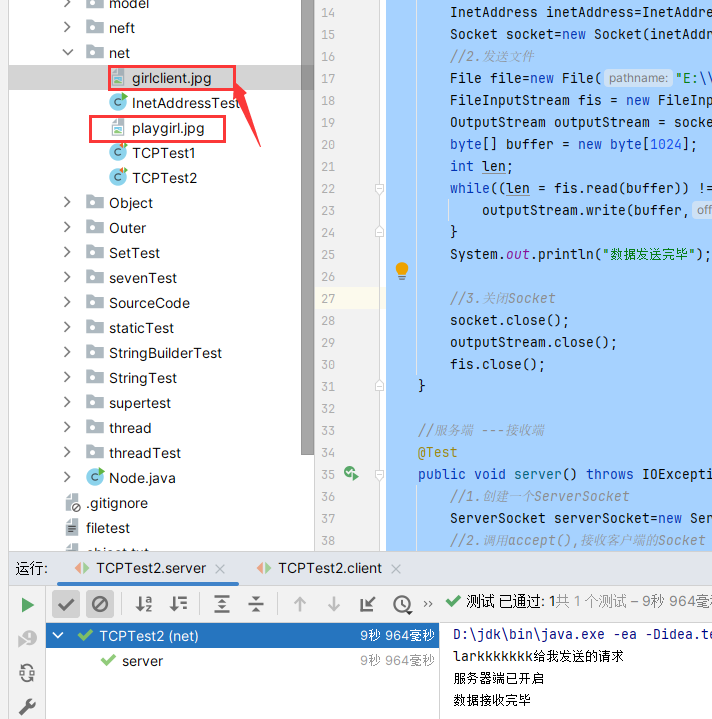
例题2:客户端发送文件给服务端,服务端将文件保存在本地。
1 | package net; |
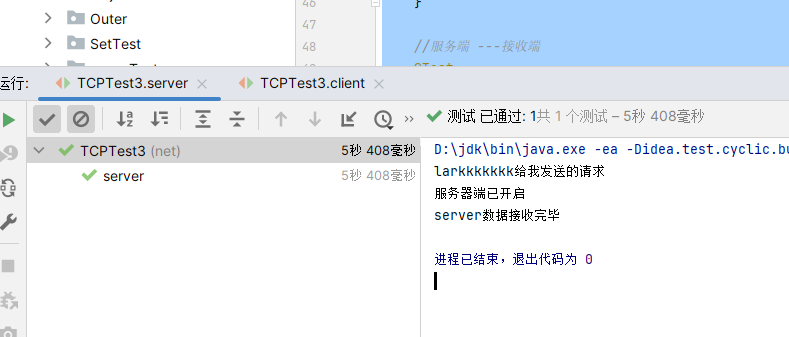
例题3:从客户端发送文件给服务端,服务端保存到本地。并返回“发送成功”给客户端。并关闭相应的连接。
1 | package net; |
练习1:服务端读取图片并发送给客户端,客户端保存图片到本地
练习2:客户端给服务端发送文本,服务端会将文本转成大写在返回给客户端。
演示单个客户端与服务器单次通信:
需求:客户端连接服务器,连接成功后给服务发送“lalala”,服务器收到消息后,给客户端返回“欢迎登录”,客户端接收消息后,断开连接
1、服务器端示例代码
1 | import java.io.InputStream; |
2、客户端示例代码
1 | import java.io.InputStream; |
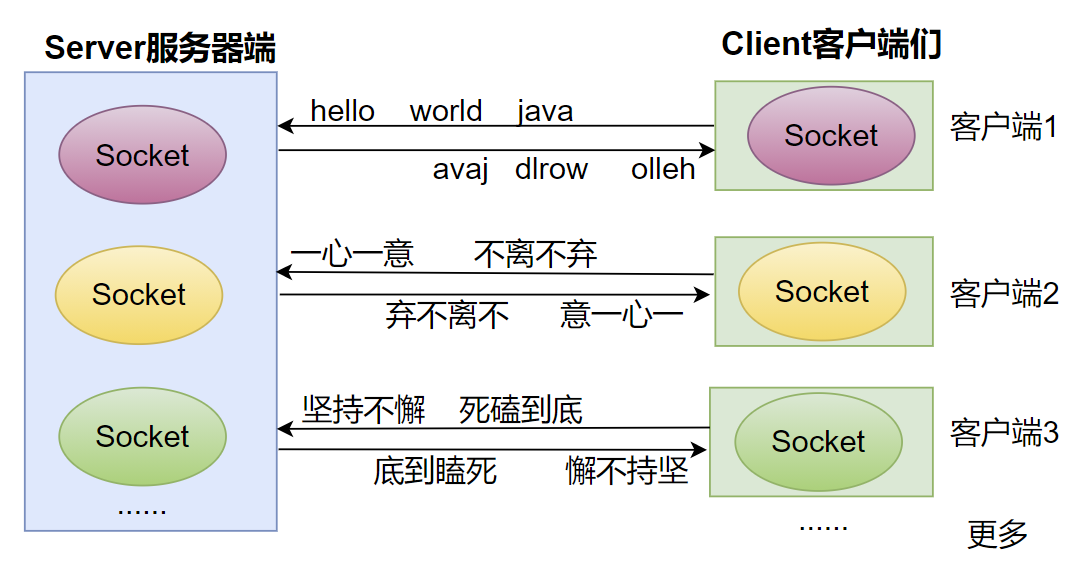
演示多个客户端与服务器之间的多次通信:
通常情况下,服务器不应该只接受一个客户端请求,而应该不断地接受来自客户端的所有请求,所以Java程序通常会通过循环,不断地调用ServerSocket的accept()方法。
如果服务器端要“同时”处理多个客户端的请求,因此服务器端需要为每一个客户端单独分配一个线程来处理,否则无法实现“同时”。
咱们之前学习IO流的时候,提到过装饰者设计模式,该设计使得不管底层IO流是怎样的节点流:文件流也好,网络Socket产生的流也好,程序都可以将其包装成处理流,甚至可以多层包装,从而提供更多方便的处理。
案例需求:多个客户端连接服务器,并进行多次通信
- 每一个客户端连接成功后,从键盘输入英文单词或中国成语,并发送给服务器
- 服务器收到客户端的消息后,把词语“反转”后返回给客户端
- 客户端接收服务器返回的“词语”,打印显示
- 当客户端输入“stop”时断开与服务器的连接
- 多个客户端可以同时给服务器发送“词语”,服务器可以“同时”处理多个客户端的请求
1、服务器端示例代码
1 | import java.io.BufferedReader; |
2、客户端示例代码
1 | import java.io.BufferedReader; |
4.4 案例:聊天室
服务端:
1 | import java.io.BufferedReader; |
客户端:
1 | import java.io.IOException; |
4.5 理解客户端、服务端
客户端:
- 自定义
- 浏览器(browser — server)
服务端:
- 自定义
- Tomcat服务器
5. UDP网络编程
UDP(User Datagram Protocol,用户数据报协议):是一个无连接的传输层协议、提供面向事务的简单不可靠的信息传送服务,类似于短信。
5.1 通信模型
UDP协议是一种面向非连接的协议,面向非连接指的是在正式通信前不必与对方先建立连接,不管对方状态就直接发送,至于对方是否可以接收到这些数据内容,UDP协议无法控制,因此说,UDP协议是一种不可靠的协议。无连接的好处就是快,省内存空间和流量,因为维护连接需要创建大量的数据结构。UDP会尽最大努力交付数据,但不保证可靠交付,没有TCP的确认机制、重传机制,如果因为网络原因没有传送到对端,UDP也不会给应用层返回错误信息。
UDP协议是面向数据报文的信息传送服务。UDP在发送端没有缓冲区,对于应用层交付下来的报文在添加了首部之后就直接交付于ip层,不会进行合并,也不会进行拆分,而是一次交付一个完整的报文。比如我们要发送100个字节的报文,我们调用一次send()方法就会发送100字节,接收方也需要用receive()方法一次性接收100字节,不能使用循环每次获取10个字节,获取十次这样的做法。
UDP协议没有拥塞控制,所以当网络出现的拥塞不会导致主机发送数据的速率降低。虽然UDP的接收端有缓冲区,但是这个缓冲区只负责接收,并不会保证UDP报文的到达顺序是否和发送的顺序一致。因为网络传输的时候,由于网络拥塞的存在是很大的可能导致先发的报文比后发的报文晚到达。如果此时缓冲区满了,后面到达的报文将直接被丢弃。这个对实时应用来说很重要,比如:视频通话、直播等应用。
因此UDP适用于一次只传送少量数据、对可靠性要求不高的应用环境,数据报大小限制在64K以下。
类 DatagramSocket 和 DatagramPacket 实现了基于 UDP 协议网络程序。
UDP数据报通过数据报套接字 DatagramSocket 发送和接收,系统不保证 UDP数据报一定能够安全送到目的地,也不能确定什么时候可以抵达。
DatagramPacket 对象封装了UDP数据报,在数据报中包含了发送端的IP地址和端口号以及接收端的IP地址和端口号。
UDP协议中每个数据报都给出了完整的地址信息,因此无须建立发送方和接收方的连接。如同发快递包裹一样。
5.2 开发步骤
发送端程序包含以下四个基本的步骤:
- 创建DatagramSocket :默认使用系统随机分配端口号。
- 创建DatagramPacket:将要发送的数据用字节数组表示,并指定要发送的数据长度,接收方的IP地址和端口号。
- 调用 该DatagramSocket 类对象的 send方法 :发送数据报DatagramPacket对象。
- 关闭DatagramSocket 对象:发送端程序结束,关闭通信套接字。
接收端程序包含以下四个基本的步骤 :
- 创建DatagramSocket :指定监听的端口号。
- 创建DatagramPacket:指定接收数据用的字节数组,起到临时数据缓冲区的效果,并指定最大可以接收的数据长度。
- 调用 该DatagramSocket 类对象的receive方法 :接收数据报DatagramPacket对象。。
- 关闭DatagramSocket :接收端程序结束,关闭通信套接字。
5.3 演示发送和接收消息
基于UDP协议的网络编程仍然需要在通信实例的两端各建立一个Socket,但这两个Socket之间并没有虚拟链路,这两个Socket只是发送、接收数据报的对象,Java提供了DatagramSocket对象作为基于UDP协议的Socket,使用DatagramPacket代表DatagramSocket发送、接收的数据报。
举例1:
发送端:
1 | DatagramSocket ds = null; |
接收端:
1 | DatagramSocket ds = null; |
举例2:
发送端:
1 | package com.atguigu.udp; |
接收端:
1 | package com.atguigu.udp; |
6. URL编程
6.1 URL类
URL(Uniform Resource Locator):统一资源定位符,它表示 Internet 上某一资源的地址。
通过 URL 我们可以访问 Internet 上的各种网络资源,比如最常见的 www,ftp 站点。浏览器通过解析给定的 URL 可以在网络上查找相应的文件或其他资源。
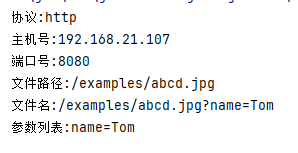
URL的基本结构由5部分组成:
1 | <传输协议>://<主机名>:<端口号>/<文件名>#片段名?参数列表 |
例如: http://192.168.1.100:8080/helloworld/index.jsp#a?username=shkstart&password=123
- 片段名:即锚点,例如看小说,直接定位到章节
- 参数列表格式:参数名=参数值&参数名=参数值….
为了表示URL,java.net 中实现了类 URL。我们可以通过下面的构造器来初始化一个 URL 对象:
public URL (String spec):通过一个表示URL地址的字符串可以构造一个URL对象。例如:
1
URL url = new URL("http://www. atguigu.com/");
public URL(URL context, String spec):通过基 URL 和相对 URL 构造一个 URL 对象。例如:
1
URL downloadUrl = new URL(url, “download.html")
public URL(String protocol, String host, String file); 例如:
1
URL url = new URL("http", "www.atguigu.com", “download. html");
public URL(String protocol, String host, int port, String file); 例如:
1
URL gamelan = new URL("http", "www.atguigu.com", 80, “download.html");
URL类的构造器都声明抛出非运行时异常,必须要对这一异常进行处理,通常是用 try-catch 语句进行捕获。
6.2 URL类常用方法
一个URL对象生成后,其属性是不能被改变的,但可以通过它给定的方法来获取这些属性:
public String getProtocol( ) 获取该URL的协议名
public String getHost( ) 获取该URL的主机名
public String getPort( ) 获取该URL的端口号
public String getPath( ) 获取该URL的文件路径
public String getFile( ) 获取该URL的文件名
public String getQuery( ) 获取该URL的查询名
1 | import java.net.MalformedURLException; |
6.3 针对HTTP协议的URLConnection类
URL的方法 openStream():能从网络上读取数据
若希望输出数据,例如向服务器端的 CGI (公共网关接口-Common Gateway Interface-的简称,是用户浏览器和服务器端的应用程序进行连接的接口)程序发送一些数据,则必须先与URL建立连接,然后才能对其进行读写,此时需要使用 URLConnection 。
URLConnection:表示到URL所引用的远程对象的连接。当与一个URL建立连接时,首先要在一个 URL 对象上通过方法 openConnection() 生成对应的 URLConnection 对象。如果连接过程失败,将产生IOException.
String str="http://raw.githubusercontent.com/.images/202311031512799.png"; URL url=new URL(str); HttpURLConnection urlConnection= (HttpURLConnection) url.openConnection();import java.io.IOException; import java.io.InputStream; import java.net.HttpURLConnection; import java.net.MalformedURLException; import java.net.URL; import java.io.*; public class UrlTestDown { public static void main(String[] args) throws IOException { //将URL代表的资源下载到本地 //1.获取URL实例 String str="http://raw.githubusercontent.com/Larkkkkkkk/hexo-picture/main/.images/202311031512799.png"; URL url=new URL(str); //2.建立与服务器端的连接 HttpURLConnection urlConnection= (HttpURLConnection) url.openConnection(); //3.获取输入流(从服务器得到)、创建输出流(存储到本地) InputStream is = urlConnection.getInputStream(); File file=new File("hahha.png"); FileOutputStream fos=new FileOutputStream(file); //4.读写数据 byte[] buffer = new byte[1024]; int len; while ((len = is.read(buffer)) != -1) { fos.write(buffer, 0, len); } System.out.println("文件下载完成"); //5.关闭资源 fos.close(); is.close(); urlConnection.disconnect(); //还比较特殊 } }1
2
3
4
5
6
7
8
9
10
- 通过URLConnection对象获取的输入流和输出流,即可以与现有的CGI程序进行交互。
- public Object getContent( ) throws IOException
- public int getContentLength( )
- public String getContentType( )
- public long getDate( )
- public long getLastModified( )
- public InputStream getInputStream ( ) throws IOException
- public OutputSteram getOutputStream( )throws IOException

6.4 小结
- 位于网络中的计算机具有唯一的IP地址,这样不同的主机可以互相区分。
- 客户端-服务器是一种最常见的网络应用程序模型。服务器是一个为其客户端提供某种特定服务的硬件或软件。客户机是一个用户应用程序,用于访问某台服务器提供的服务。端口号是对一个服务的访问场所,它用于区分同一物理计算机上的多个服务。套接字用于连接客户端和服务器,客户端和服务器之间的每个通信会话使用一个不同的套接字。TCP协议用于实现面向连接的会话。
- Java 中有关网络方面的功能都定义在 java.net 程序包中。Java 用 InetAddress 对象表示 IP 地址,该对象里有两个字段:主机名(String) 和 IP 地址(int)。
- 类 Socket 和 ServerSocket 实现了基于TCP协议的客户端-服务器程序。Socket是客户端和服务器之间的一个连接,连接创建的细节被隐藏了。这个连接提供了一个安全的数据传输通道,这是因为 TCP 协议可以解决数据在传送过程中的丢失、损坏、重复、乱序以及网络拥挤等问题,它保证数据可靠的传送。
- 类 URL 和 URLConnection 提供了最高级网络应用。URL 的网络资源的位置来同一表示 Internet 上各种网络资源。通过URL对象可以创建当前应用程序和 URL 表示的网络资源之间的连接,这样当前程序就可以读取网络资源数据,或者把自己的数据传送到网络上去。
JAVA-File类和IO流
第15章_File类与IO流
本章专题与脉络
1. java.io.File类的使用
1.1 概述
- File类及本章下的各种流,都定义在java.io包下。
- 一个File对象 —-代表—-> 硬盘或网络中可能存在的一个文件/文件目录(俗称文件夹),与平台无关。(体会万事万物皆对象)
- File 能新建、删除、重命名文件和目录,但 File 不能访问文件内容本身。如果需要访问文件内容本身,则需要使用输入/输出流。
- File对象可以作为参数传递给流的构造器。
- 想要在Java程序中表示一个真实存在的文件或目录,那么必须有一个File对象,但是Java程序中的一个File对象,可能没有一个真实存在的文件或目录。
1.2 构造器
public File(String pathname):以pathname为路径创建File对象,可以是绝对路径或者相对路径,如果pathname是相对路径,则默认的当前路径在系统属性user.dir中存储。public File(String parent, String child):以parent为父路径,child为子路径创建File对象。public File(File parent, String child):根据一个父File对象和子文件路径创建File对象
关于路径:
- 绝对路径:从盘符开始的路径,这是一个完整的路径。
- 相对路径:相对于
项目目录的路径,这是一个便捷的路径,开发中经常使用。- IDEA中,main中的文件的相对路径,是相对于”
当前工程project“ - IDEA中,单元测试方法中的文件的相对路径,是相对于”
当前模块module“
- IDEA中,main中的文件的相对路径,是相对于”
举例:
1 | import java.io.File; |
注意:
无论该路径下是否存在文件或者目录,都不影响File对象的创建。
window的路径分隔符使用“\”,而Java程序中的“\”表示转义字符,所以在Windows中表示路径,需要用“\”。或者直接使用“/”也可以,Java程序支持将“/”当成平台无关的
路径分隔符。或者直接使用File.separator常量值表示。比如:File file2 = new File(“d:” + File.separator + “atguigu” + File.separator + “info.txt”);
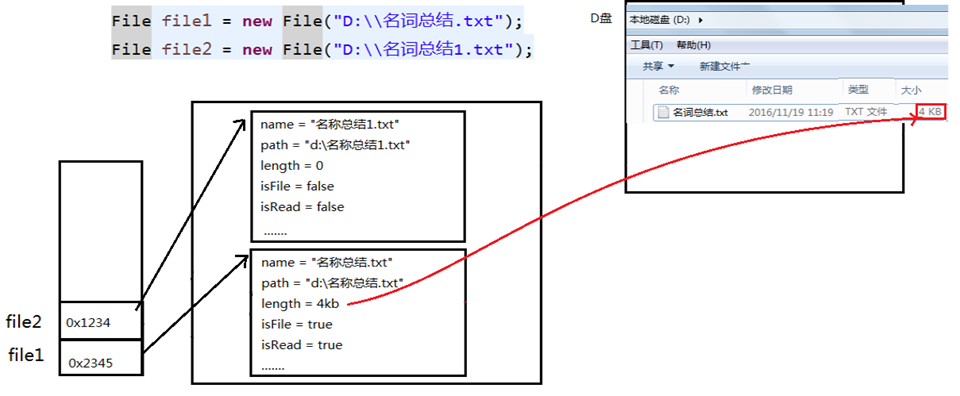
当构造路径是绝对路径时,那么getPath和getAbsolutePath结果一样
当构造路径是相对路径时,那么getAbsolutePath的路径 = user.dir的路径 + 构造路径
1.3 常用方法
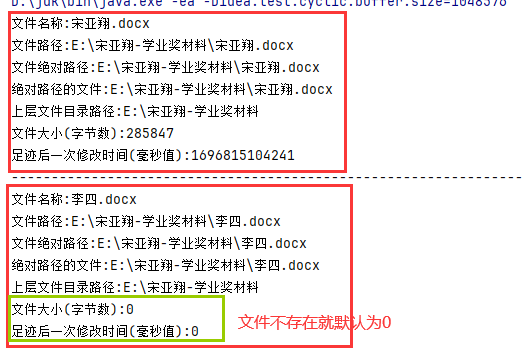
1、获取文件和目录基本信息
- public String getName() :获取名称
- public String getPath() :获取路径
public String getAbsolutePath():获取绝对路径- public File getAbsoluteFile():获取绝对路径表示的文件
public String getParent():获取上层文件目录路径。若无,返回null- public long length() :获取文件长度(即:字节数)。不能获取目录的长度。
- public long lastModified() :获取最后一次的修改时间,毫秒值
如果File对象代表的文件或目录存在,则File对象实例初始化时,就会用硬盘中对应文件或目录的属性信息(例如,时间、类型等)为File对象的属性赋值,否则除了路径和名称,File对象的其他属性将会保留默认值。
举例:
1 |
|
2、列出目录的下一级
- public String[] list() :返回一个String数组,表示该File目录中的所有子文件或目录。
- public File[] listFiles() :返回一个File数组,表示该File目录中的所有的子文件或目录。
1 |
|

3、File类的重命名功能
- public boolean renameTo(File dest):把文件重命名为指定的文件路径。
4、判断功能的方法
public boolean exists():此File表示的文件或目录是否实际存在。public boolean isDirectory():此File表示的是否为目录。public boolean isFile():此File表示的是否为文件。- public boolean canRead() :判断是否可读
- public boolean canWrite() :判断是否可写
- public boolean isHidden() :判断是否隐藏
举例:
1 |
|

如果文件或目录不存在,那么exists()、isFile()和isDirectory()都是返回true
5、创建、删除功能
public boolean createNewFile():创建文件。若文件存在,则不创建,返回false。public boolean mkdir():创建文件目录。如果此文件目录存在,就不创建了。如果此文件目录的上层目录不存在,也不创建。public boolean mkdirs():创建文件目录。如果上层文件目录不存在,一并创建。public boolean delete():删除文件或者文件夹
删除注意事项:① Java中的删除不走回收站。② 要删除一个文件目录,请注意该文件目录内不能包含文件或者文件目录。
举例:
1 | import java.io.File; |
1 | 运行结果: |
API中说明:delete方法,如果此File表示目录,则目录必须为空才能删除。
1.4 练习
练习1:利用File构造器,new 一个文件目录file
1) 在其中创建多个文件和目录
2) 编写方法,实现删除file中指定文件的操作1 | @Test |
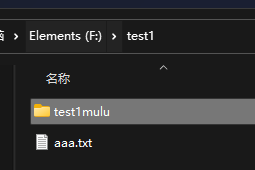
练习2:判断指定目录下是否有后缀名为.jpg的文件。如果有,就输出该文件名称
1 | public class FindJPGFileTest { |
练习3:遍历指定目录所有文件名称,包括子文件目录中的文件。
拓展1:并计算指定目录占用空间的大小
拓展2:删除指定文件目录及其下的所有文件
1 | public class ListFilesTest { |
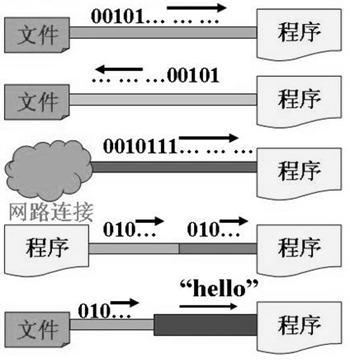
2. IO流原理及流的分类

2.1 Java IO原理
Java程序中,数据的输入/输出操作以“
流(stream)” 的方式进行,可以看做是一种数据的流动。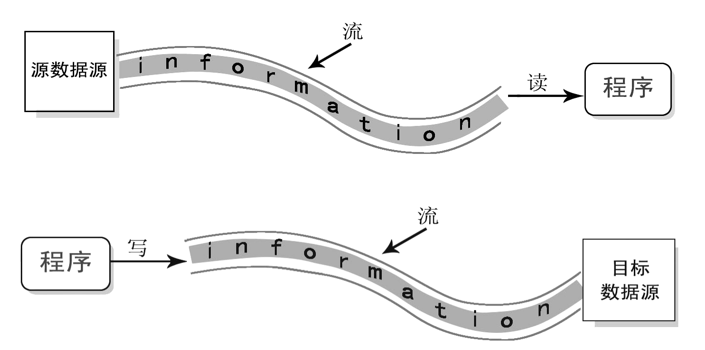
I/O流中的I/O是
Input/Output的缩写, I/O技术是非常实用的技术,用于处理设备之间的数据传输。如读/写文件,网络通讯等。输入input:读取外部数据(磁盘、光盘等存储设备的数据)到程序(内存)中。输出output:将程序(内存)数据输出到磁盘、光盘等存储设备中。
2.2 流的分类
java.io包下提供了各种“流”类和接口,用以获取不同种类的数据,并通过标准的方法输入或输出数据。
按数据的流向不同 —-> :输入流和输出流。
- 输入流 :把数据从
其他设备上读取到内存中的流。- 以InputStream、Reader结尾
- 输出流 :把数据从
内存中写出到其他设备上的流。- 以OutputStream、Writer结尾
- 输入流 :把数据从
按操作数据单位的不同 ** —-> :字节流(8bit)和字符流(16bit)**。
- 字节流 :以字节为单位,读写数据的流。
- 以InputStream、OutputStream结尾
- 字符流 :以字符为单位,读写数据的流。
- 以Reader、Writer结尾
- 字节流 :以字节为单位,读写数据的流。
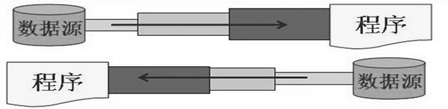
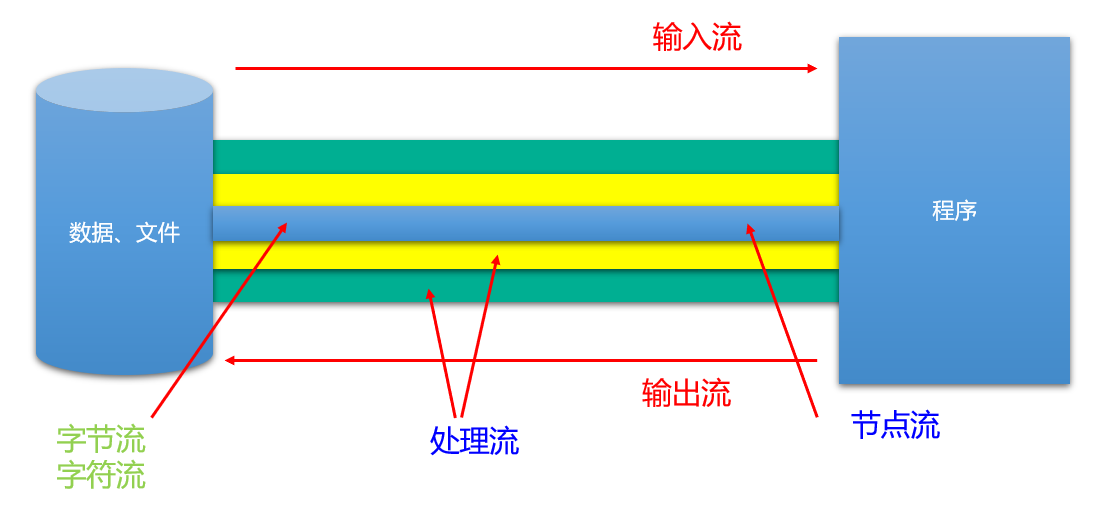
根据IO流的角色不同 —-> :节点流和处理流。
节点流:直接从数据源或目的地读写数据

处理流:不直接连接到数据源或目的地,而是“连接”在已存在的流(节点流或处理流)之上,通过对数据的处理为程序提供更为强大的读写功能。
小结:图解
2.3 流的API
- Java的IO流共涉及40多个类,实际上非常规则,都是从如下4个抽象基类派生的。
| (抽象基类) | 输入流 | 输出流 |
|---|---|---|
| 字节流(以字节为单位,读写数据) | InputStream | OutputStream |
| 字符流(以字符为单位,读写数据) | Reader | Writer |
- 由这四个类派生出来的子类名称都是以其父类名作为子类名后缀。
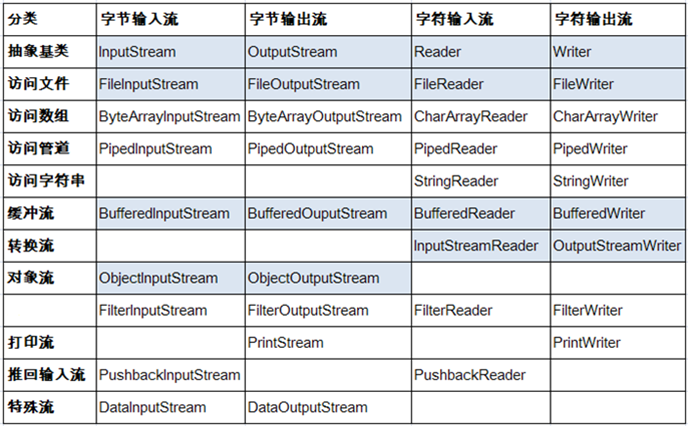
常用节点流:
- 文件流: FileInputStream、FileOutputStrean、FileReader、FileWriter
- 字节/字符数组流: ByteArrayInputStream、ByteArrayOutputStream、CharArrayReader、CharArrayWriter
- 对数组进行处理的节点流(对应的不再是文件,而是内存中的一个数组)。
常用处理流:
- 缓冲流:BufferedInputStream、BufferedOutputStream、BufferedReader、BufferedWriter
- 作用:增加缓冲功能,避免频繁读写硬盘,进而提升读写效率。
- 转换流:InputStreamReader、OutputStreamReader
- 作用:实现字节流和字符流之间的转换。
- 对象流:ObjectInputStream、ObjectOutputStream
- 作用:提供直接读写Java对象功能
3. 节点流之一:FileReader\FileWriter
3.1 Reader与Writer
Java提供一些字符流类,以字符为单位读写数据,专门用于处理文本文件。不能操作图片,视频等非文本文件。
常见的文本文件有如下的格式:.txt、.java、.c、.cpp、.py等
注意:.doc、.xls、.ppt这些都不是文本文件。
3.1.1 字符输入流:Reader
java.io.Reader抽象类是表示用于读取字符流的所有类的父类,可以读取字符信息到内存中。它定义了字符输入流的基本共性功能方法。
public int read(): 从输入流读取一个字符。 虽然读取了一个字符,但是会自动提升为int类型。返回该字符的Unicode编码值。如果已经到达流末尾了,则返回-1。public int read(char[] cbuf): 从输入流中读取一些字符,并将它们存储到字符数组 cbuf中 。每次最多读取cbuf.length个字符。返回实际读取的字符个数。如果已经到达流末尾,没有数据可读,则返回-1。public int read(char[] cbuf,int off,int len):从输入流中读取一些字符,并将它们存储到字符数组 cbuf中,从cbuf[off]开始的位置存储。每次最多读取len个字符。返回实际读取的字符个数。如果已经到达流末尾,没有数据可读,则返回-1。public void close():关闭此流并释放与此流相关联的任何系统资源。
注意:当完成流的操作时,必须调用close()方法,释放系统资源,否则会造成内存泄漏。
3.1.2 字符输出流:Writer
java.io.Writer抽象类是表示用于写出字符流的所有类的超类,将指定的字符信息写出到目的地。它定义了字节输出流的基本共性功能方法。
public void write(int c):写出单个字符。public void write(char[] cbuf):写出字符数组。public void write(char[] cbuf, int off, int len):写出字符数组的某一部分。off:数组的开始索引;len:写出的字符个数。public void write(String str):写出字符串。public void write(String str, int off, int len):写出字符串的某一部分。off:字符串的开始索引;len:写出的字符个数。public void flush():刷新该流的缓冲。public void close():关闭此流。
注意:当完成流的操作时,必须调用close()方法,释放系统资源,否则会造成内存泄漏。
3.2 FileReader 与 FileWriter
3.2.1 FileReader
java.io.FileReader类用于读取字符文件,构造时使用系统默认的字符编码和默认字节缓冲区。
FileReader(File file): 创建一个新的 FileReader ,给定要读取的File对象。FileReader(String fileName): 创建一个新的 FileReader ,给定要读取的文件的名称。
举例:读取hello.txt文件中的字符数据,并显示在控制台上
1 | public class FileReaderWriterTest { |
不同实现方式的类比:
3.2.2 FileWriter
java.io.FileWriter类用于写出字符到文件,构造时使用系统默认的字符编码和默认字节缓冲区。
FileWriter(File file): 创建一个新的 FileWriter,给定要读取的File对象。FileWriter(String fileName): 创建一个新的 FileWriter,给定要读取的文件的名称。FileWriter(File file,boolean append): 创建一个新的 FileWriter,指明是否在现有文件末尾追加内容。
举例:
1 | public class FWWrite { |
3.2.3 小结
1 | ① 因为出现流资源的调用,为了避免内存泄漏,需要使用try-catch-finally处理异常 |
3.3 关于flush(刷新)
因为内置缓冲区的原因,如果FileWriter不关闭输出流,无法写出字符到文件中。但是关闭的流对象,是无法继续写出数据的。如果我们既想写出数据,又想继续使用流,就需要flush() 方法了。
flush():刷新缓冲区,流对象可以继续使用。close():先刷新缓冲区,然后通知系统释放资源。流对象不可以再被使用了。
注意:即便是flush()方法写出了数据,操作的最后还是要调用close方法,释放系统资源。
举例:
1 | public class FWWriteFlush { |
4. 节点流之二:FileInputStream\FileOutputStream
如果我们读取或写出的数据是非文本文件,则Reader、Writer就无能为力了,必须使用字节流。
4.1 InputStream和OutputStream
4.1.1 字节输入流:InputStream
java.io.InputStream抽象类是表示字节输入流的所有类的超类,可以读取字节信息到内存中。它定义了字节输入流的基本共性功能方法。
public int read(): 从输入流读取一个字节。返回读取的字节值。虽然读取了一个字节,但是会自动提升为int类型。如果已经到达流末尾,没有数据可读,则返回-1。public int read(byte[] b): 从输入流中读取一些字节数,并将它们存储到字节数组 b中 。每次最多读取b.length个字节。返回实际读取的字节个数。如果已经到达流末尾,没有数据可读,则返回-1。public int read(byte[] b,int off,int len):从输入流中读取一些字节数,并将它们存储到字节数组 b中,从b[off]开始存储,每次最多读取len个字节 。返回实际读取的字节个数。如果已经到达流末尾,没有数据可读,则返回-1。public void close():关闭此输入流并释放与此流相关联的任何系统资源。
说明:close()方法,当完成流的操作时,必须调用此方法,释放系统资源。
4.1.2 字节输出流:OutputStream
java.io.OutputStream抽象类是表示字节输出流的所有类的超类,将指定的字节信息写出到目的地。它定义了字节输出流的基本共性功能方法。
public void write(int b):将指定的字节输出流。虽然参数为int类型四个字节,但是只会保留一个字节的信息写出。public void write(byte[] b):将 b.length字节从指定的字节数组写入此输出流。public void write(byte[] b, int off, int len):从指定的字节数组写入 len字节,从偏移量 off开始输出到此输出流。public void flush():刷新此输出流并强制任何缓冲的输出字节被写出。public void close():关闭此输出流并释放与此流相关联的任何系统资源。
说明:close()方法,当完成流的操作时,必须调用此方法,释放系统资源。
4.2 FileInputStream 与 FileOutputStream
4.2.1 FileInputStream
java.io.FileInputStream类是文件输入流,从文件中读取字节。
FileInputStream(File file): 通过打开与实际文件的连接来创建一个 FileInputStream ,该文件由文件系统中的 File对象 file命名。FileInputStream(String name): 通过打开与实际文件的连接来创建一个 FileInputStream ,该文件由文件系统中的路径名 name命名。
举例:
1 | //read.txt文件中的内容如下: |
读取操作
1 | public class FISRead { |
4.2.2 FileOutputStream
java.io.FileOutputStream类是文件输出流,用于将数据写出到文件。
public FileOutputStream(File file):创建文件输出流,写出由指定的 File对象表示的文件。public FileOutputStream(String name): 创建文件输出流,指定的名称为写出文件。public FileOutputStream(File file, boolean append): 创建文件输出流,指明是否在现有文件末尾追加内容。
举例:
1 | import org.junit.Test; |
4.3 练习
练习:实现图片加密操作。
提示:

1 | public class FileSecretTest { |
5. 处理流之一:缓冲流
为了提高数据读写的速度,Java API提供了带缓冲功能的流类:缓冲流。缓冲流要“套接”在相应的节点流之上,根据数据操作单位可以把缓冲流分为:
- 字节缓冲流:
BufferedInputStream,BufferedOutputStream - 字符缓冲流:
BufferedReader,BufferedWriter
- 字节缓冲流:
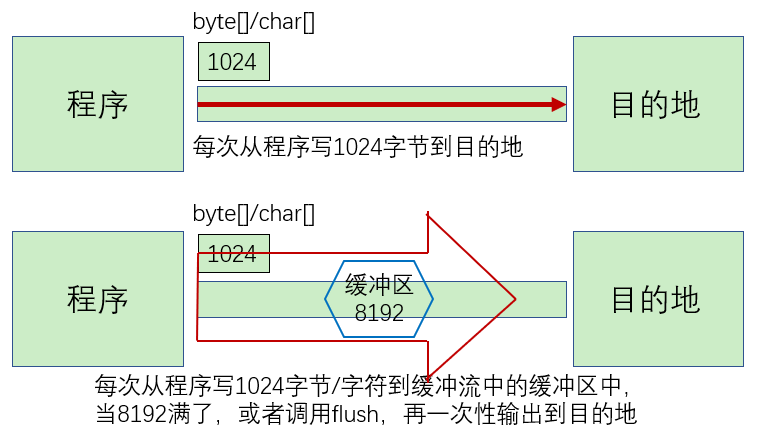
缓冲流的基本原理:在创建流对象时,内部会创建一个缓冲区数组(缺省使用
8192个字节(8Kb)的缓冲区),通过缓冲区读写,减少系统IO次数,从而提高读写的效率。

5.1 构造器
public BufferedInputStream(InputStream in):创建一个 新的字节型的缓冲输入流。public BufferedOutputStream(OutputStream out): 创建一个新的字节型的缓冲输出流。
代码举例:
1 | // 创建字节缓冲输入流 |
public BufferedReader(Reader in):创建一个 新的字符型的缓冲输入流。public BufferedWriter(Writer out): 创建一个新的字符型的缓冲输出流。
代码举例:
1 | // 创建字符缓冲输入流 |
5.2 效率测试
查询API,缓冲流读写方法与基本的流是一致的,我们通过复制大文件(375MB),测试它的效率。
1 | //方法1:使用FileInputStream\FileOutputStream实现非文本文件的复制 |
5.3 字符缓冲流特有方法
字符缓冲流的基本方法与普通字符流调用方式一致,不再阐述,我们来看它们具备的特有方法。
- BufferedReader:
public String readLine(): 读一行文字。 - BufferedWriter:
public void newLine(): 写一行行分隔符,由系统属性定义符号。
1 | public class BufferedIOLine { |
说明:
涉及到嵌套的多个流时,如果都显式关闭的话,需要先关闭外层的流,再关闭内层的流
其实在开发中,只需要关闭最外层的流即可,因为在关闭外层流时,内层的流也会被关闭。
5.4 练习
练习1:分别使用节点流:FileInputStream、FileOutputStream和缓冲流:BufferedInputStream、BufferedOutputStream实现文本文件/图片/视频文件的复制。并比较二者在数据复制方面的效率。
练习2:
姓氏统计:一个文本文件中存储着北京所有高校在校生的姓名,格式如下:
1 | 每行一个名字,姓与名以空格分隔: |
现在想统计所有的姓氏在文件中出现的次数,请描述一下你的解决方案。
1 | public static void main(String[] args) { |
6. 处理流之二:转换流
6.1 问题引入
引入情况1:
使用FileReader 读取项目中的文本文件。由于IDEA设置中针对项目设置了UTF-8编码,当读取Windows系统中创建的文本文件时,如果Windows系统默认的是GBK编码,则读入内存中会出现乱码。
1 | import java.io.FileReader; |
那么如何读取GBK编码的文件呢?
引入情况2:
针对文本文件,现在使用一个字节流进行数据的读入,希望将数据显示在控制台上。此时针对包含中文的文本数据,可能会出现乱码。
6.2 转换流的理解
作用:转换流是字节与字符间的桥梁!

具体来说:
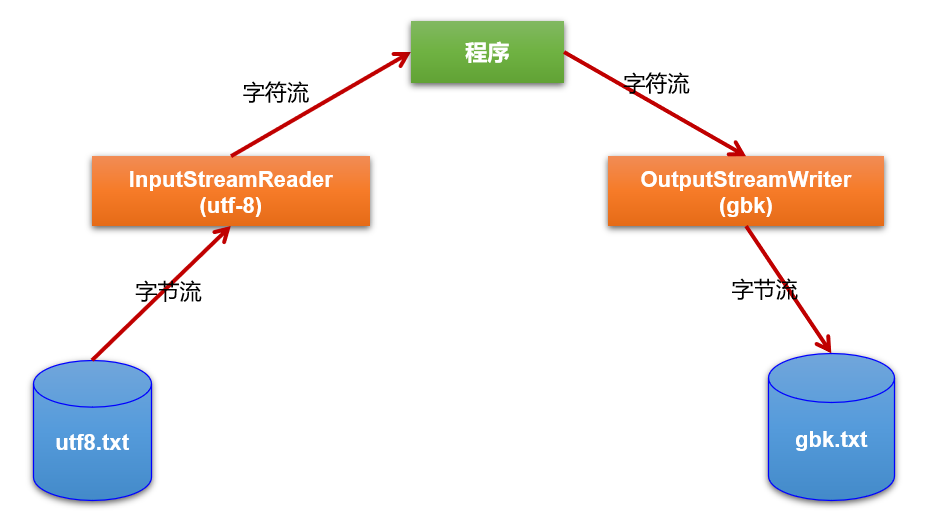
6.3 InputStreamReader 与 OutputStreamWriter
InputStreamReader
转换流
java.io.InputStreamReader,是Reader的子类,是从字节流到字符流的桥梁。它读取字节,并使用指定的字符集将其解码为字符。它的字符集可以由名称指定,也可以接受平台的默认字符集。构造器
InputStreamReader(InputStream in): 创建一个使用默认字符集的字符流。InputStreamReader(InputStream in, String charsetName): 创建一个指定字符集的字符流。
举例
1
2
3
4//使用默认字符集
InputStreamReader isr1 = new InputStreamReader(new FileInputStream("in.txt"));
//使用指定字符集
InputStreamReader isr2 = new InputStreamReader(new FileInputStream("in.txt") , "GBK");示例代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31package com.atguigu.transfer;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
public class InputStreamReaderDemo {
public static void main(String[] args) throws IOException {
// 定义文件路径,文件为gbk编码
String fileName = "E:\\file_gbk.txt";
//方式1:
// 创建流对象,默认UTF8编码
InputStreamReader isr1 = new InputStreamReader(new FileInputStream(fileName));
// 定义变量,保存字符
int charData;
// 使用默认编码字符流读取,乱码
while ((charData = isr1.read()) != -1) {
System.out.print((char)charData); // ��Һ�
}
isr1.close();
//方式2:
// 创建流对象,指定GBK编码
InputStreamReader isr2 = new InputStreamReader(new FileInputStream(fileName) , "GBK");
// 使用指定编码字符流读取,正常解析
while ((charData = isr2.read()) != -1) {
System.out.print((char)charData);// 大家好
}
isr2.close();
}
}
OutputStreamWriter
转换流
java.io.OutputStreamWriter,是Writer的子类,是从字符流到字节流的桥梁。使用指定的字符集将字符编码为字节。它的字符集可以由名称指定,也可以接受平台的默认字符集。构造器
OutputStreamWriter(OutputStream in): 创建一个使用默认字符集的字符流。OutputStreamWriter(OutputStream in,String charsetName): 创建一个指定字符集的字符流。
举例:
1
2
3
4//使用默认字符集
OutputStreamWriter isr = new OutputStreamWriter(new FileOutputStream("out.txt"));
//使用指定的字符集
OutputStreamWriter isr2 = new OutputStreamWriter(new FileOutputStream("out.txt") , "GBK");示例代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26package com.atguigu.transfer;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter;
public class OutputStreamWriterDemo {
public static void main(String[] args) throws IOException {
// 定义文件路径
String FileName = "E:\\out_utf8.txt";
// 创建流对象,默认UTF8编码
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream(FileName));
// 写出数据
osw.write("你好"); // 保存为6个字节
osw.close();
// 定义文件路径
String FileName2 = "E:\\out_gbk.txt";
// 创建流对象,指定GBK编码
OutputStreamWriter osw2 = new OutputStreamWriter(new
FileOutputStream(FileName2),"GBK");
// 写出数据
osw2.write("你好");// 保存为4个字节
osw2.close();
}
}
6.4 字符编码和字符集
6.4.1 编码与解码
计算机中储存的信息都是用二进制数表示的,而我们在屏幕上看到的数字、英文、标点符号、汉字等字符是二进制数转换之后的结果。按照某种规则,将字符存储到计算机中,称为编码 。反之,将存储在计算机中的二进制数按照某种规则解析显示出来,称为解码 。
字符编码(Character Encoding) : 就是一套自然语言的字符与二进制数之间的对应规则。
编码表:生活中文字和计算机中二进制的对应规则
乱码的情况:按照A规则存储,同样按照A规则解析,那么就能显示正确的文本符号。反之,按照A规则存储,再按照B规则解析,就会导致乱码现象。
1 | 编码:字符(人能看懂的)--字节(人看不懂的) |
6.4.2 字符集
- 字符集Charset:也叫编码表。是一个系统支持的所有字符的集合,包括各国家文字、标点符号、图形符号、数字等。
- 计算机要准确的存储和识别各种字符集符号,需要进行字符编码,一套字符集必然至少有一套字符编码。常见字符集有ASCII字符集、GBK字符集、Unicode字符集等。
可见,当指定了编码,它所对应的字符集自然就指定了,所以编码才是我们最终要关心的。
ASCII字符集 :
- ASCII码(American Standard Code for Information Interchange,美国信息交换标准代码):上个世纪60年代,美国制定了一套字符编码,对
英语字符与二进制位之间的关系,做了统一规定。这被称为ASCII码。 - ASCII码用于显示现代英语,主要包括控制字符(回车键、退格、换行键等)和可显示字符(英文大小写字符、阿拉伯数字和西文符号)。
- 基本的ASCII字符集,使用7位(bits)表示一个字符(最前面的1位统一规定为0),共
128个字符。比如:空格“SPACE”是32(二进制00100000),大写的字母A是65(二进制01000001)。 - 缺点:不能表示所有字符。
- ASCII码(American Standard Code for Information Interchange,美国信息交换标准代码):上个世纪60年代,美国制定了一套字符编码,对
ISO-8859-1字符集:
- 拉丁码表,别名Latin-1,用于显示欧洲使用的语言,包括荷兰语、德语、意大利语、葡萄牙语等
- ISO-8859-1使用单字节编码,兼容ASCII编码。
GBxxx字符集:
- GB就是国标的意思,是为了
显示中文而设计的一套字符集。 - GB2312:简体中文码表。一个小于127的字符的意义与原来相同,即向下兼容ASCII码。但两个大于127的字符连在一起时,就表示一个汉字,这样大约可以组合了包含
7000多个简体汉字,此外数学符号、罗马希腊的字母、日文的假名们都编进去了,这就是常说的”全角”字符,而原来在127号以下的那些符号就叫”半角”字符了。 - GBK:最常用的中文码表。是在GB2312标准基础上的扩展规范,使用了
双字节编码方案,共收录了21003个汉字,完全兼容GB2312标准,同时支持繁体汉字以及日韩汉字等。 - GB18030:最新的中文码表。收录汉字
70244个,采用多字节编码,每个字可以由1个、2个或4个字节组成。支持中国国内少数民族的文字,同时支持繁体汉字以及日韩汉字等。
- GB就是国标的意思,是为了
Unicode字符集 :
- Unicode编码为表达
任意语言的任意字符而设计,也称为统一码、标准万国码。Unicode 将世界上所有的文字用2个字节统一进行编码,为每个字符设定唯一的二进制编码,以满足跨语言、跨平台进行文本处理的要求。
- Unicode 的缺点:这里有三个问题:
- 第一,英文字母只用一个字节表示就够了,如果用更多的字节存储是
极大的浪费。 - 第二,如何才能
区别Unicode和ASCII?计算机怎么知道两个字节表示一个符号,而不是分别表示两个符号呢? - 第三,如果和GBK等双字节编码方式一样,用最高位是1或0表示两个字节和一个字节,就少了很多值无法用于表示字符,
不够表示所有字符。
- 第一,英文字母只用一个字节表示就够了,如果用更多的字节存储是
- Unicode在很长一段时间内无法推广,直到互联网的出现,为解决Unicode如何在网络上传输的问题,于是面向传输的众多 UTF(UCS Transfer Format)标准出现。具体来说,有三种编码方案,UTF-8、UTF-16和UTF-32。
- Unicode编码为表达
UTF-8字符集:
- Unicode是字符集,UTF-8、UTF-16、UTF-32是三种
将数字转换到程序数据的编码方案。顾名思义,UTF-8就是每次8个位传输数据,而UTF-16就是每次16个位。其中,UTF-8 是在互联网上使用最广的一种 Unicode 的实现方式。 - 互联网工程工作小组(IETF)要求所有互联网协议都必须支持UTF-8编码。所以,我们开发Web应用,也要使用UTF-8编码。UTF-8 是一种
变长的编码方式。它使用1-4个字节为每个字符编码,编码规则:- 128个US-ASCII字符,只需一个字节编码。
- 拉丁文等字符,需要二个字节编码。
- 大部分常用字(含中文),使用三个字节编码。
- 其他极少使用的Unicode辅助字符,使用四字节编码。
- Unicode是字符集,UTF-8、UTF-16、UTF-32是三种
- 举例
Unicode符号范围 | UTF-8编码方式
1 | (十六进制) | (二进制) |

- 小结
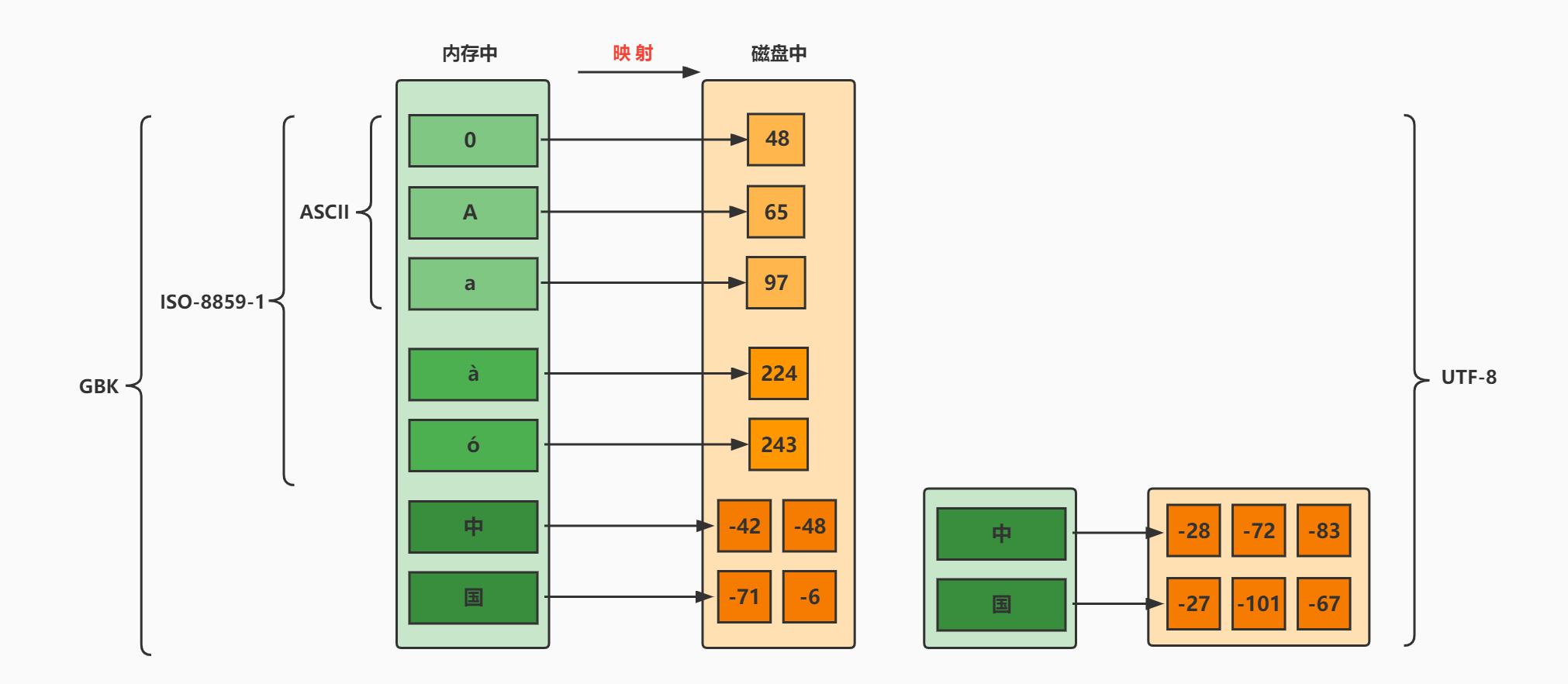
注意:在中文操作系统上,ANSI(美国国家标准学会、AMERICAN NATIONAL STANDARDS INSTITUTE: ANSI)编码即为GBK;在英文操作系统上,ANSI编码即为ISO-8859-1。
6.5 练习
把当前module下的《康师傅的话.txt》字符编码为GBK,复制到电脑桌面目录下的《寄语.txt》,
字符编码为UTF-8。
在当前module下的文本内容:
1 | 六项精进: |
代码:
1 | public class InputStreamReaderDemo { |
7. 处理流之三/四:数据流、对象流
7.1 数据流与对象流说明
如果需要将内存中定义的变量(包括基本数据类型或引用数据类型)保存在文件中,那怎么办呢?
1 | int age = 300; |
Java提供了数据流和对象流来处理这些类型的数据:
数据流:DataOutputStream、DataInputStream
DataOutputStream:允许应用程序将基本数据类型、String类型的变量写入输出流中
DataInputStream:允许应用程序以与机器无关的方式从底层输入流中读取基本数据类型、String类型的变量。
对象流DataInputStream中的方法:
1 | byte readByte() short readShort() |
- 对象流DataOutputStream中的方法:将上述的方法的read改为相应的write即可。
- 数据流的弊端:只支持Java基本数据类型和字符串的读写,而不支持其它Java对象的类型。而ObjectOutputStream和ObjectInputStream既支持Java基本数据类型的数据读写,又支持Java对象的读写,所以重点介绍对象流ObjectOutputStream和ObjectInputStream。
- 对象流:ObjectOutputStream、ObjectInputStream
- ObjectOutputStream:将 Java 基本数据类型和对象写入字节输出流中。通过在流中使用文件可以实现Java各种基本数据类型的数据以及对象的持久存储。
- ObjectInputStream:ObjectInputStream 对以前使用 ObjectOutputStream 写出的基本数据类型的数据和对象进行读入操作,保存在内存中。
说明:对象流的强大之处就是可以把Java中的对象写入到数据源中,也能把对象从数据源中还原回来。
7.2 对象流API
ObjectOutputStream中的构造器:
public ObjectOutputStream(OutputStream out): 创建一个指定的ObjectOutputStream。
1 | FileOutputStream fos = new FileOutputStream("game.dat"); |
ObjectOutputStream中的方法:
- public void writeBoolean(boolean val):写出一个 boolean 值。
- public void writeByte(int val):写出一个8位字节
- public void writeShort(int val):写出一个16位的 short 值
- public void writeChar(int val):写出一个16位的 char 值
- public void writeInt(int val):写出一个32位的 int 值
- public void writeLong(long val):写出一个64位的 long 值
- public void writeFloat(float val):写出一个32位的 float 值。
- public void writeDouble(double val):写出一个64位的 double 值
- public void writeUTF(String str):将表示长度信息的两个字节写入输出流,后跟字符串 s 中每个字符的 UTF-8 修改版表示形式。根据字符的值,将字符串 s 中每个字符转换成一个字节、两个字节或三个字节的字节组。注意,将 String 作为基本数据写入流中与将它作为 Object 写入流中明显不同。 如果 s 为 null,则抛出 NullPointerException。
public void writeObject(Object obj):写出一个obj对象- public void close() :关闭此输出流并释放与此流相关联的任何系统资源
ObjectInputStream中的构造器:
public ObjectInputStream(InputStream in): 创建一个指定的ObjectInputStream。
1 | FileInputStream fis = new FileInputStream("game.dat"); |
ObjectInputStream中的方法:
- public boolean readBoolean():读取一个 boolean 值
- public byte readByte():读取一个 8 位的字节
- public short readShort():读取一个 16 位的 short 值
- public char readChar():读取一个 16 位的 char 值
- public int readInt():读取一个 32 位的 int 值
- public long readLong():读取一个 64 位的 long 值
- public float readFloat():读取一个 32 位的 float 值
- public double readDouble():读取一个 64 位的 double 值
- public String readUTF():读取 UTF-8 修改版格式的 String
public void readObject(Object obj):读入一个obj对象- public void close() :关闭此输入流并释放与此流相关联的任何系统资源
7.3 认识对象序列化机制
1、何为对象序列化机制?
对象序列化机制允许把内存中的Java对象转换成平台无关的二进制流,从而允许把这种二进制流持久地保存在磁盘上,或通过网络将这种二进制流传输到另一个网络节点。//当其它程序获取了这种二进制流,就可以恢复成原来的Java对象。
- 序列化过程:用一个字节序列可以表示一个对象,该字节序列包含该
对象的类型和对象中存储的属性等信息。字节序列写出到文件之后,相当于文件中持久保存了一个对象的信息。
- 反序列化过程:该字节序列还可以从文件中读取回来,重构对象,对它进行
反序列化。对象的数据、对象的类型和对象中存储的数据信息,都可以用来在内存中创建对象。

2、序列化机制的重要性
序列化是 RMI(Remote Method Invoke、远程方法调用)过程的参数和返回值都必须实现的机制,而 RMI 是 JavaEE 的基础。因此序列化机制是 JavaEE 平台的基础。
序列化的好处,在于可将任何实现了Serializable接口的对象转化为字节数据,使其在保存和传输时可被还原。
3、实现原理
序列化:用ObjectOutputStream类保存基本类型数据或对象的机制。方法为:
public final void writeObject (Object obj): 将指定的对象写出。
反序列化:用ObjectInputStream类读取基本类型数据或对象的机制。方法为:
public final Object readObject (): 读取一个对象。

7.4 如何实现序列化机制
如果需要让某个对象支持序列化机制,则必须让对象所属的类及其属性是可序列化的,为了让某个类是可序列化的,该类必须实现java.io.Serializable 接口。Serializable 是一个标记接口,不实现此接口的类将不会使任何状态序列化或反序列化,会抛出NotSerializableException 。
- 如果对象的某个属性也是引用数据类型,那么如果该属性也要序列化的话,也要实现
Serializable接口 - 该类的所有属性必须是可序列化的。如果有一个属性不需要可序列化的,则该属性必须注明是瞬态的,使用
transient关键字修饰。 静态(static)变量的值不会序列化。因为静态变量的值不属于某个对象。
举例1:
1 | import org.junit.Test; |
举例2:
1 | import java.io.Serializable; |
1 | import org.junit.Test; |
举例3:如果有多个对象需要序列化,则可以将对象放到集合中,再序列化集合对象即可。
1 | import org.junit.Test; |
7.5 反序列化失败问题
问题1:
对于JVM可以反序列化对象,它必须是能够找到class文件的类。如果找不到该类的class文件,则抛出一个 ClassNotFoundException 异常。
问题2:
当JVM反序列化对象时,能找到class文件,但是class文件在序列化对象之后发生了修改,那么反序列化操作也会失败,抛出一个InvalidClassException异常。发生这个异常的原因如下:
- 该类的序列版本号与从流中读取的类描述符的版本号不匹配
- 该类包含未知数据类型
解决办法:
Serializable 接口给需要序列化的类,提供了一个序列版本号:serialVersionUID 。凡是实现 Serializable接口的类都应该有一个表示序列化版本标识符的静态变量:
1 | static final long serialVersionUID = 234242343243L; //它的值由程序员随意指定即可。 |
- serialVersionUID用来表明类的不同版本间的兼容性。简单来说,Java的序列化机制是通过在运行时判断类的serialVersionUID来验证版本一致性的。在进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地相应实体类的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常(InvalidCastException)。
- 如果类没有显示定义这个静态常量,它的值是Java运行时环境根据类的内部细节
自动生成的。若类的实例变量做了修改,serialVersionUID可能发生变化。因此,建议显式声明。 - 如果声明了serialVersionUID,即使在序列化完成之后修改了类导致类重新编译,则原来的数据也能正常反序列化,只是新增的字段值是默认值而已。
1 | import java.io.Serializable; |
7.6 面试题&练习
面试题:谈谈你对java.io.Serializable接口的理解,我们知道它用于序列化,是空方法接口,还有其它认识吗?
1 | 实现了Serializable接口的对象,可将它们转换成一系列字节,并可在以后完全恢复回原来的样子。这一过程亦可通过网络进行。这意味着序列化机制能自动补偿操作系统间的差异。换句话说,可以先在Windows机器上创建一个对象,对其序列化,然后通过网络发给一台Unix机器,然后在那里准确无误地重新“装配”。不必关心数据在不同机器上如何表示,也不必关心字节的顺序或者其他任何细节。 |
练习:
需求说明:
- 网上购物时某用户填写订单,订单内容为产品列表,保存在“save.bin”中。
- 运行时,如果不存在“save.bin”,则进行新订单录入,如果存在,则显示并计算客户所需付款。
分析:
- 编写Save()方法保存对象到“save.bin”
- 编写Load()方法获得对象,计算客户所需付款
8. 其他流的使用
8.1 标准输入、输出流
- System.in和System.out分别代表了系统标准的输入和输出设备
- 默认输入设备是:键盘,输出设备是:显示器
- System.in的类型是InputStream
- System.out的类型是PrintStream,其是OutputStream的子类FilterOutputStream 的子类
- 重定向:通过System类的setIn,setOut方法对默认设备进行改变。
- public static void setIn(InputStream in)
- public static void setOut(PrintStream out)
举例:
从键盘输入字符串,要求将读取到的整行字符串转成大写输出。然后继续进行输入操作,直至当输入“e”或者“exit”时,退出程序。
1 | System.out.println("请输入信息(退出输入e或exit):"); |
拓展:
System类中有三个常量对象:System.out、System.in、System.err
查看System类中这三个常量对象的声明:
1 | public final static InputStream in = null; |
奇怪的是,
- 这三个常量对象有final声明,但是却初始化为null。final声明的常量一旦赋值就不能修改,那么null不会空指针异常吗?
- 这三个常量对象为什么要小写?final声明的常量按照命名规范不是应该大写吗?
- 这三个常量的对象有set方法?final声明的常量不是不能修改值吗?set方法是如何修改它们的值的?
1 | final声明的常量,表示在Java的语法体系中它们的值是不能修改的,而这三个常量对象的值是由C/C++等系统函数进行初始化和修改值的,所以它们故意没有用大写,也有set方法。 |
1 | public static void setOut(PrintStream out) { |
练习:
Create a program named MyInput.java: Contain the methods for reading int, double, float, boolean, short, byte and String values from the keyboard.

1 | package com.atguigu.java; |
8.2 打印流
- 实现将基本数据类型的数据格式转化为字符串输出。
打印流:
PrintStream和PrintWriter提供了一系列重载的print()和println()方法,用于多种数据类型的输出

PrintStream和PrintWriter的输出不会抛出IOException异常
PrintStream和PrintWriter有自动flush功能
PrintStream 打印的所有字符都使用平台的默认字符编码转换为字节。在需要写入字符而不是写入字节的情况下,应该使用 PrintWriter 类。
System.out返回的是PrintStream的实例
构造器
- PrintStream(File file) :创建具有指定文件且不带自动行刷新的新打印流。
- PrintStream(File file, String csn):创建具有指定文件名称和字符集且不带自动行刷新的新打印流。
- PrintStream(OutputStream out) :创建新的打印流。
- PrintStream(OutputStream out, boolean autoFlush):创建新的打印流。 autoFlush如果为 true,则每当写入 byte 数组、调用其中一个 println 方法或写入换行符或字节 (‘\n’) 时都会刷新输出缓冲区。
- PrintStream(OutputStream out, boolean autoFlush, String encoding) :创建新的打印流。
- PrintStream(String fileName):创建具有指定文件名称且不带自动行刷新的新打印流。
- PrintStream(String fileName, String csn) :创建具有指定文件名称和字符集且不带自动行刷新的新打印流。
代码举例1
1 | import java.io.FileNotFoundException; |
- 代码举例2
1 | PrintStream ps = null; |
- 代码举例3:自定义一个日志工具
1 | /* |
1 | public class LogTest { |
8.3 Scanner类
构造方法
- Scanner(File source) :构造一个新的 Scanner,它生成的值是从指定文件扫描的。
- Scanner(File source, String charsetName) :构造一个新的 Scanner,它生成的值是从指定文件扫描的。
- Scanner(InputStream source) :构造一个新的 Scanner,它生成的值是从指定的输入流扫描的。
- Scanner(InputStream source, String charsetName) :构造一个新的 Scanner,它生成的值是从指定的输入流扫描的。
常用方法:
- boolean hasNextXxx(): 通过nextXxx(),此扫描器输入信息中的下一个标记可以解释为默认基数中的一个 Xxx 值,则返回 true。
- Xxx nextXxx(): 将输入信息的下一个标记扫描为一个Xxx
1 | import org.junit.Test; |
9. apache-common包的使用
9.1 介绍
IO技术开发中,代码量很大,而且代码的重复率较高,为此Apache软件基金会,开发了IO技术的工具类commonsIO,大大简化了IO开发。
Apahce软件基金会属于第三方,(Oracle公司第一方,我们自己第二方,其他都是第三方)我们要使用第三方开发好的工具,需要添加jar包。
9.2 导包及举例
在导入commons-io-2.5.jar包之后,内部的API都可以使用。

IOUtils类的使用
1 | - 静态方法:IOUtils.copy(InputStream in,OutputStream out)传递字节流,实现文件复制。 |
1 | public class Test01 { |
- FileUtils类的使用
1 | - 静态方法:void copyDirectoryToDirectory(File src,File dest):整个目录的复制,自动进行递归遍历 |
1 | public class Test02 { |