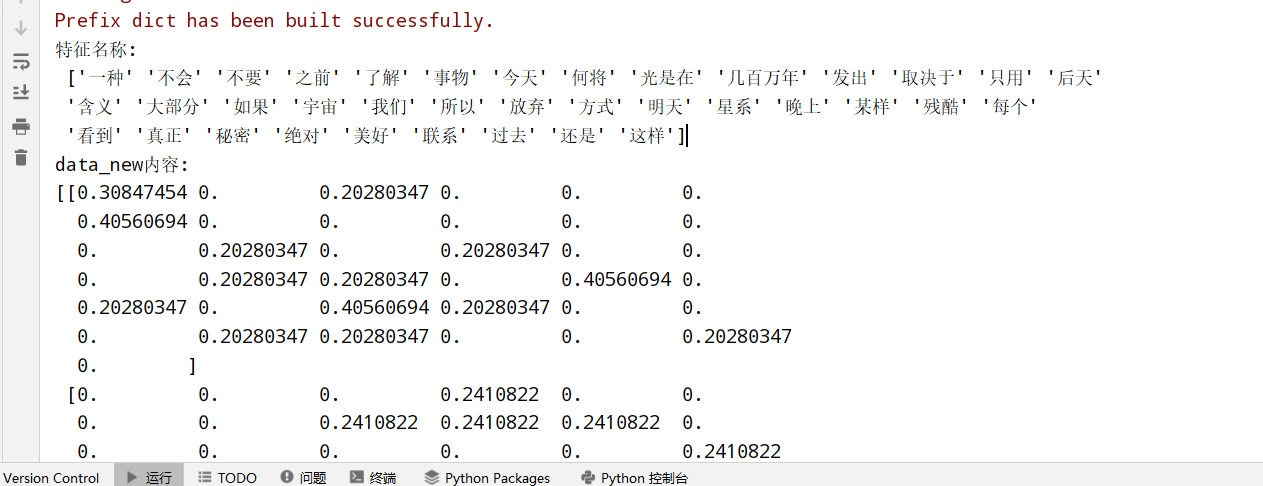
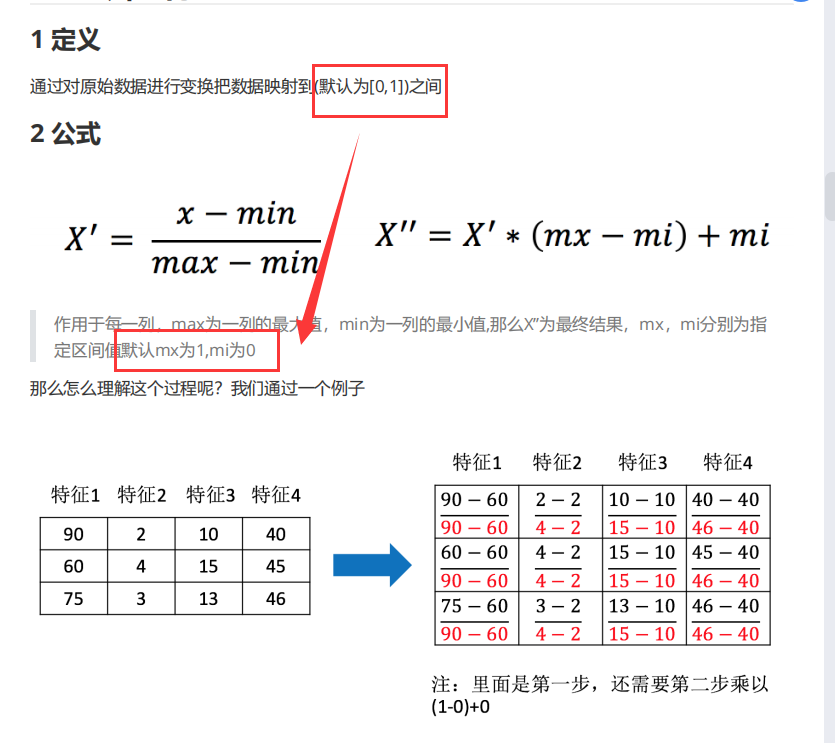
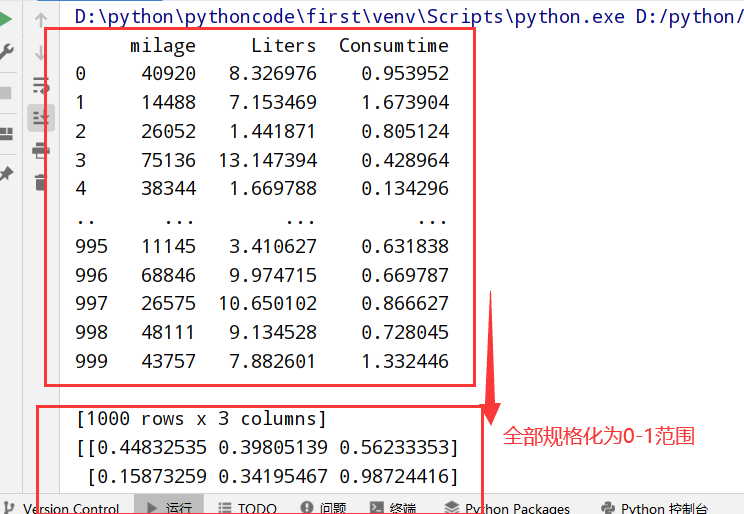
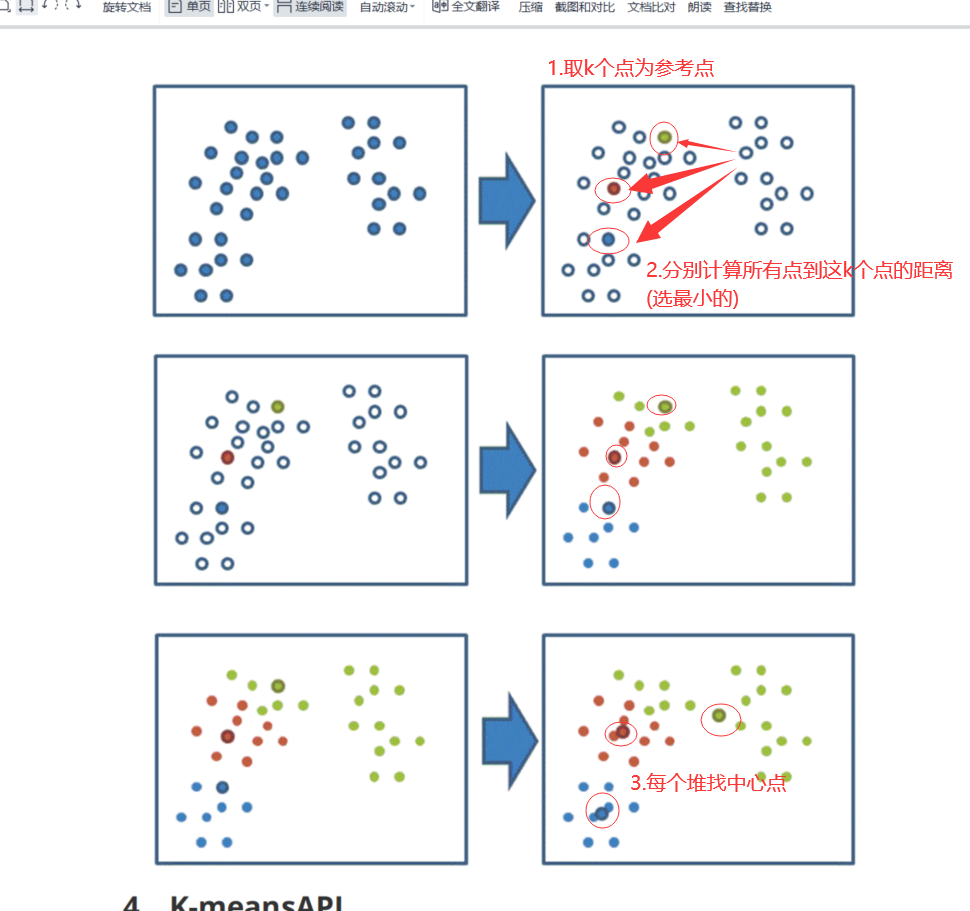
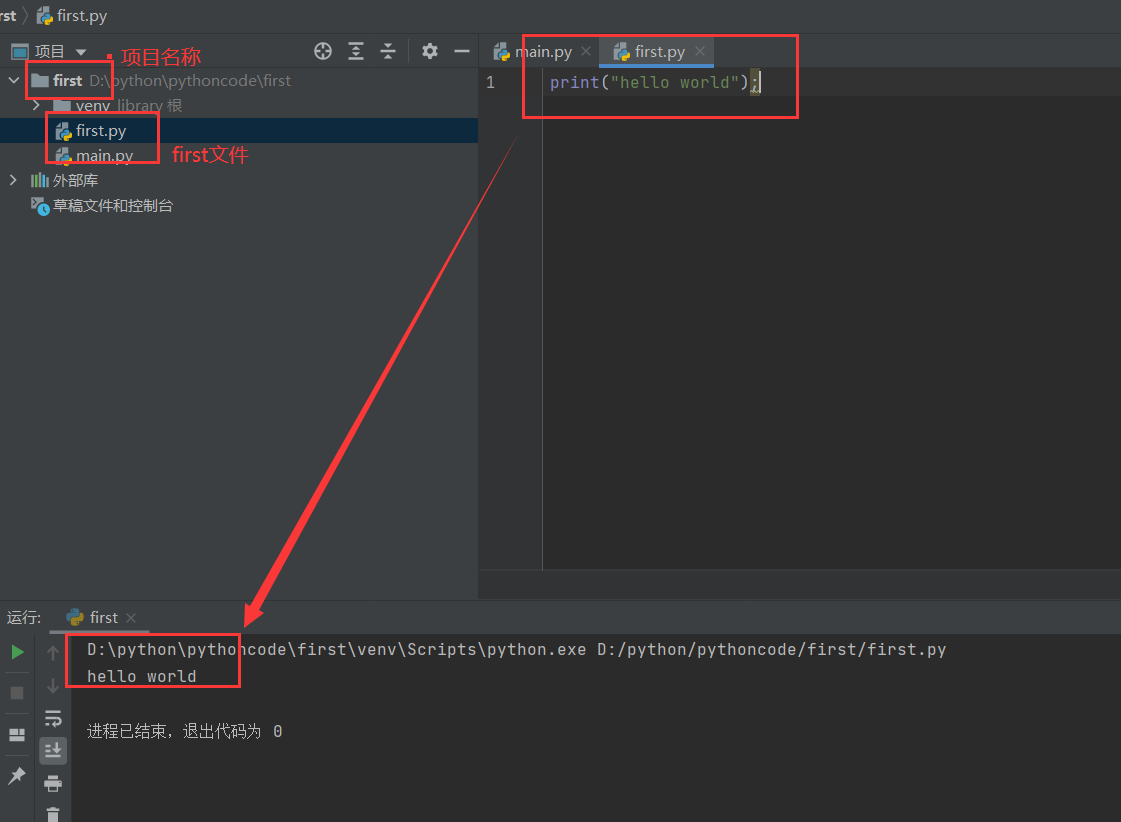
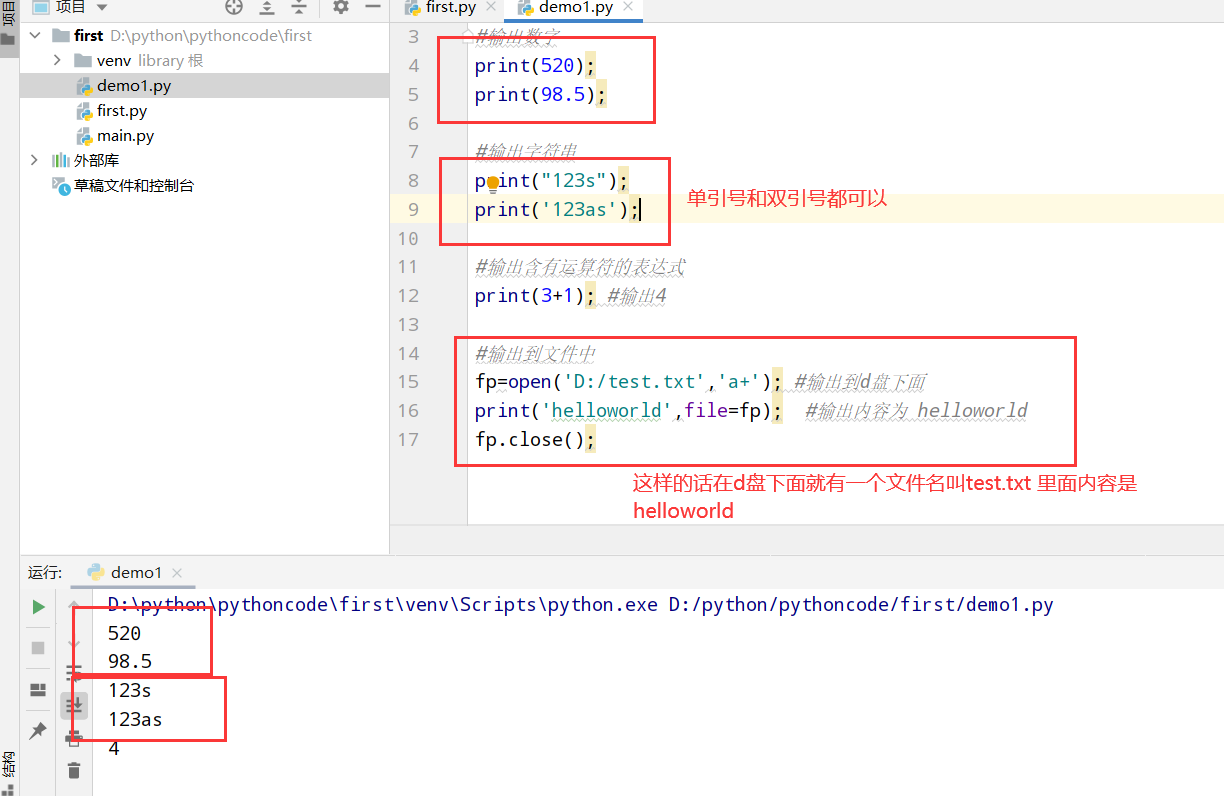
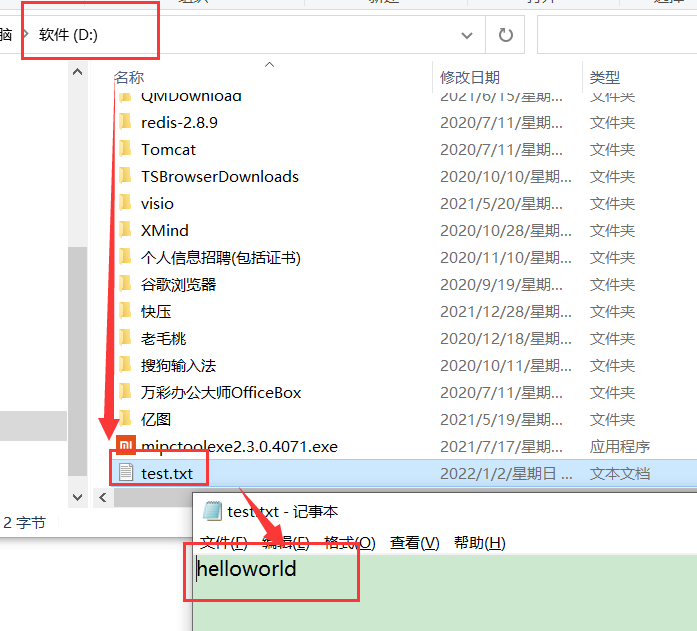
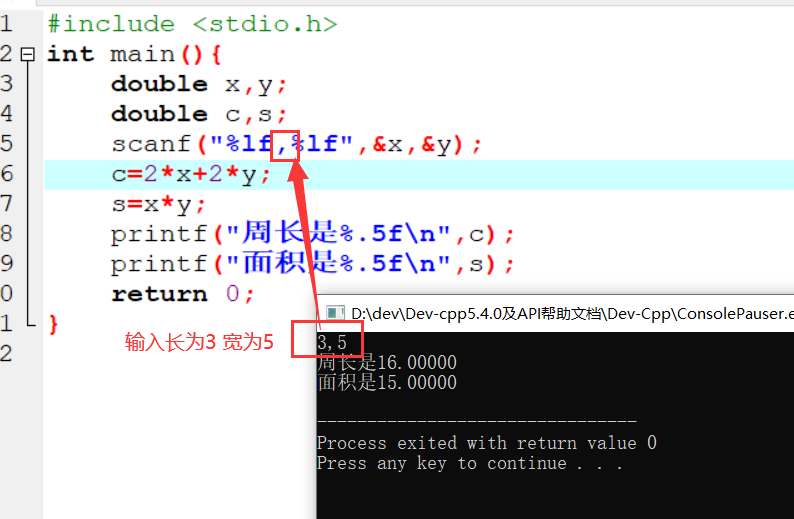
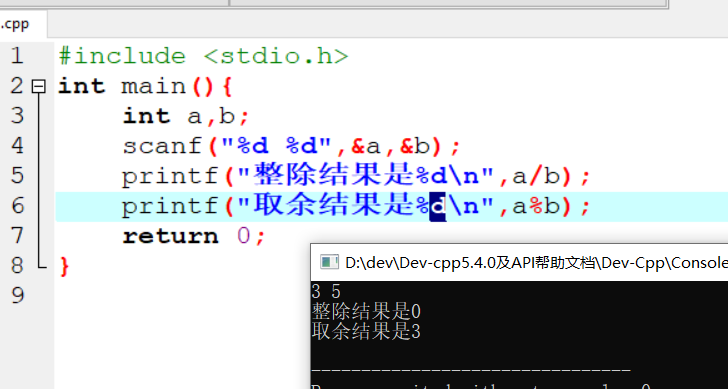
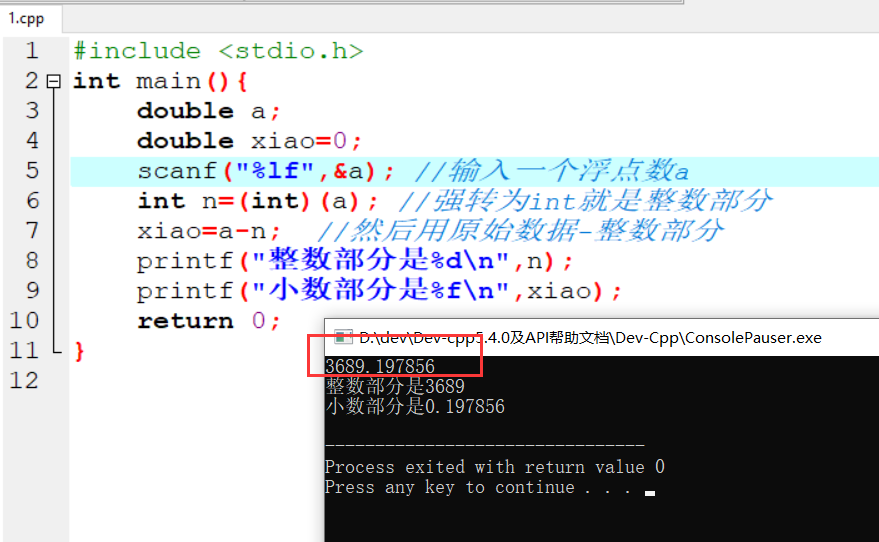
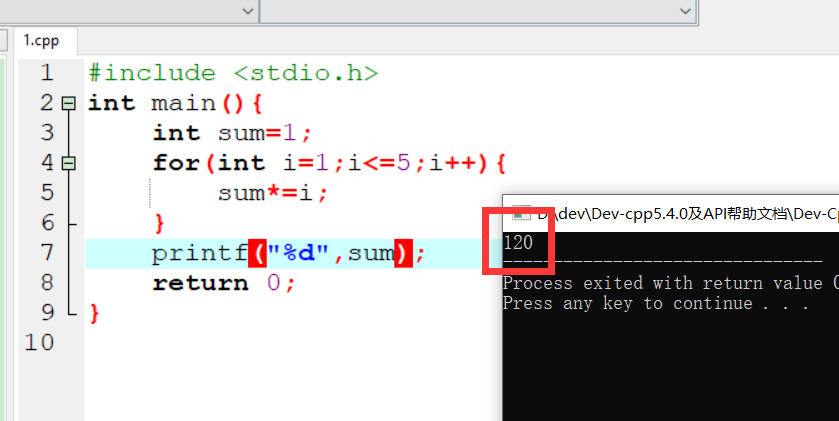
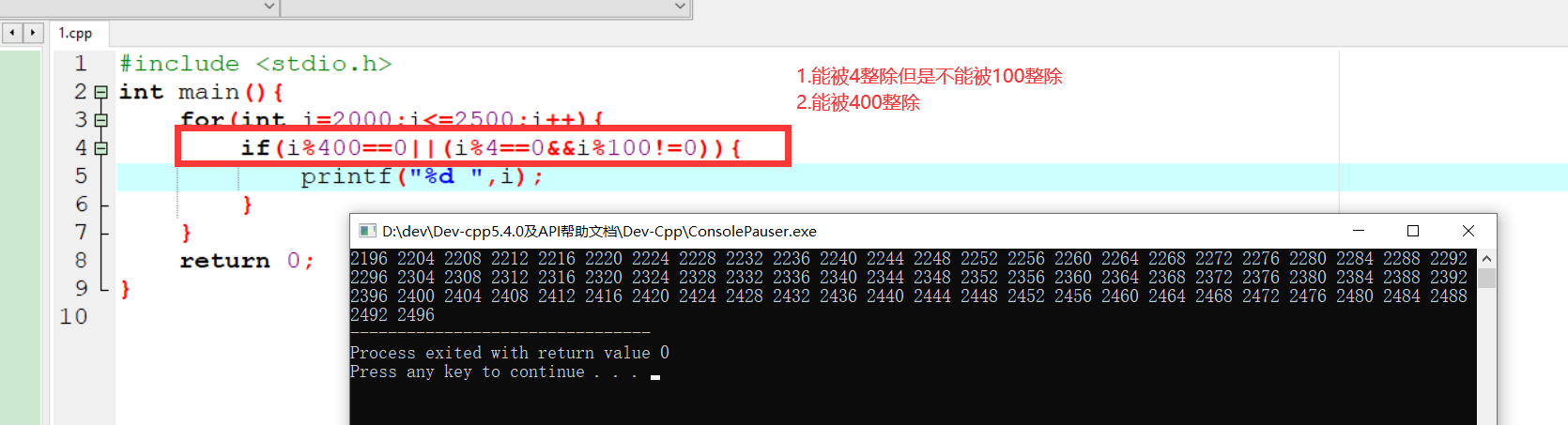
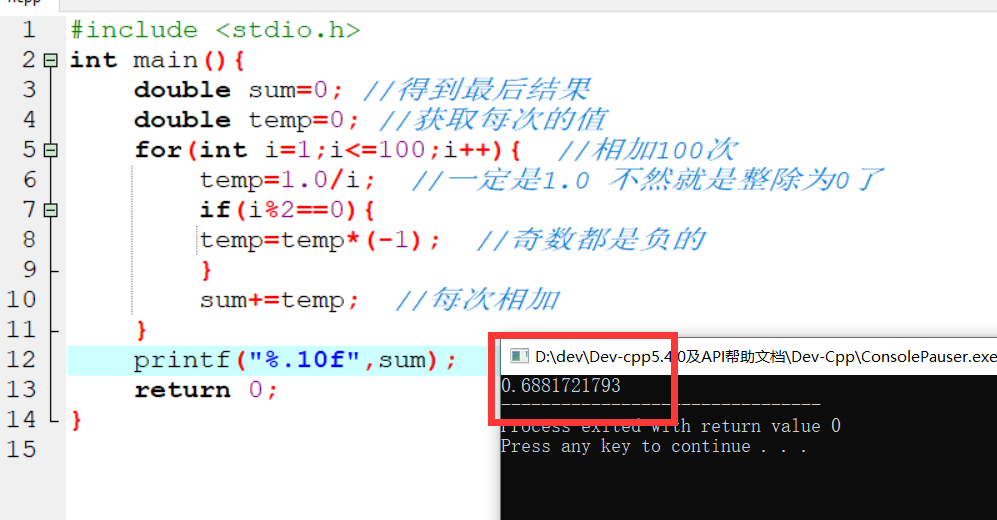
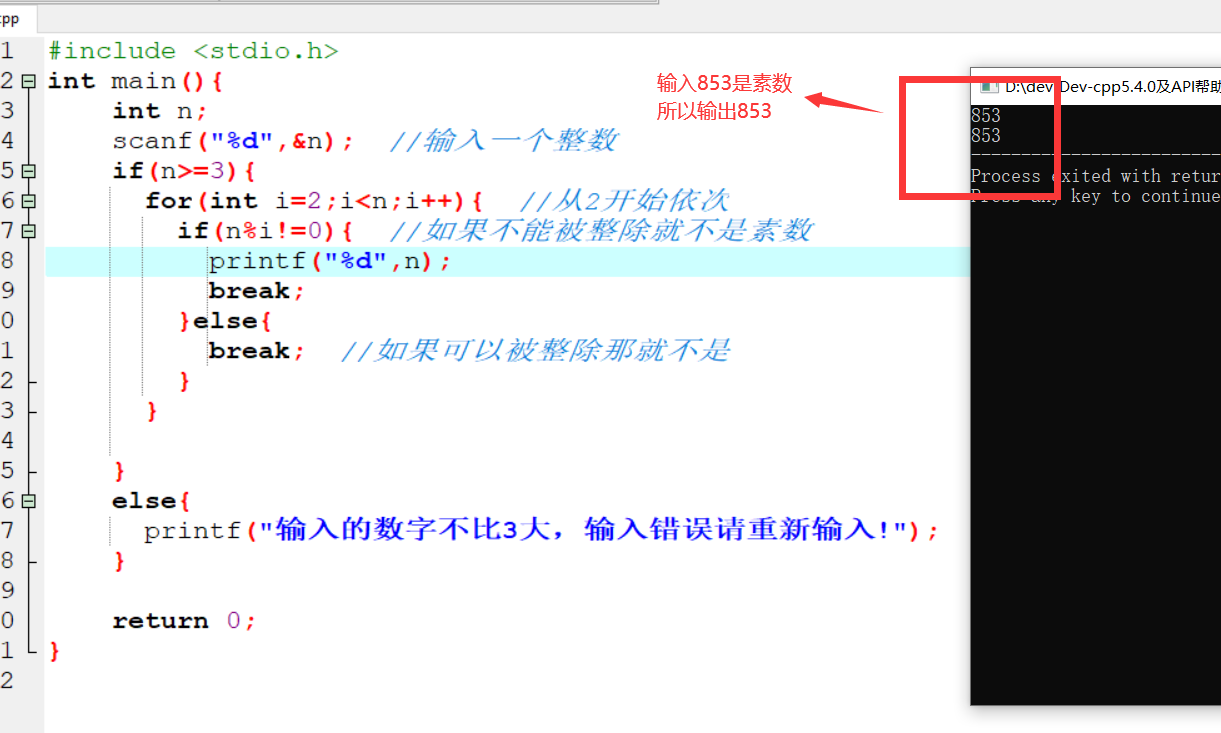
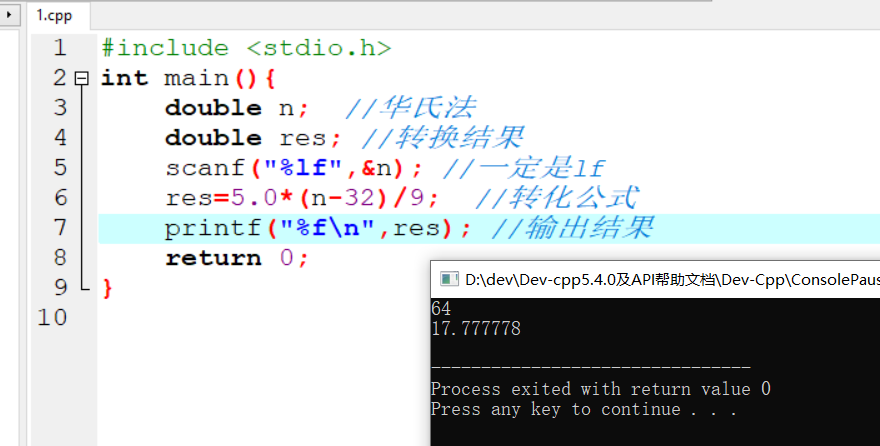
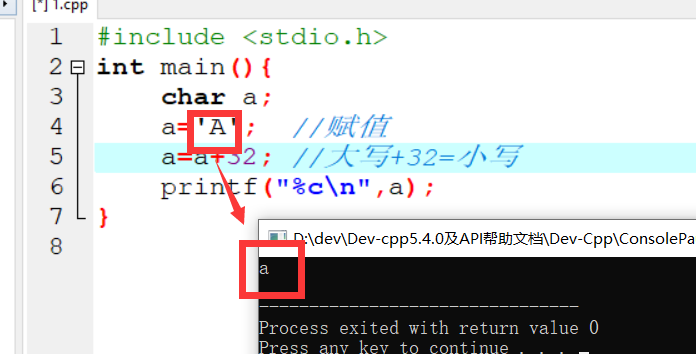
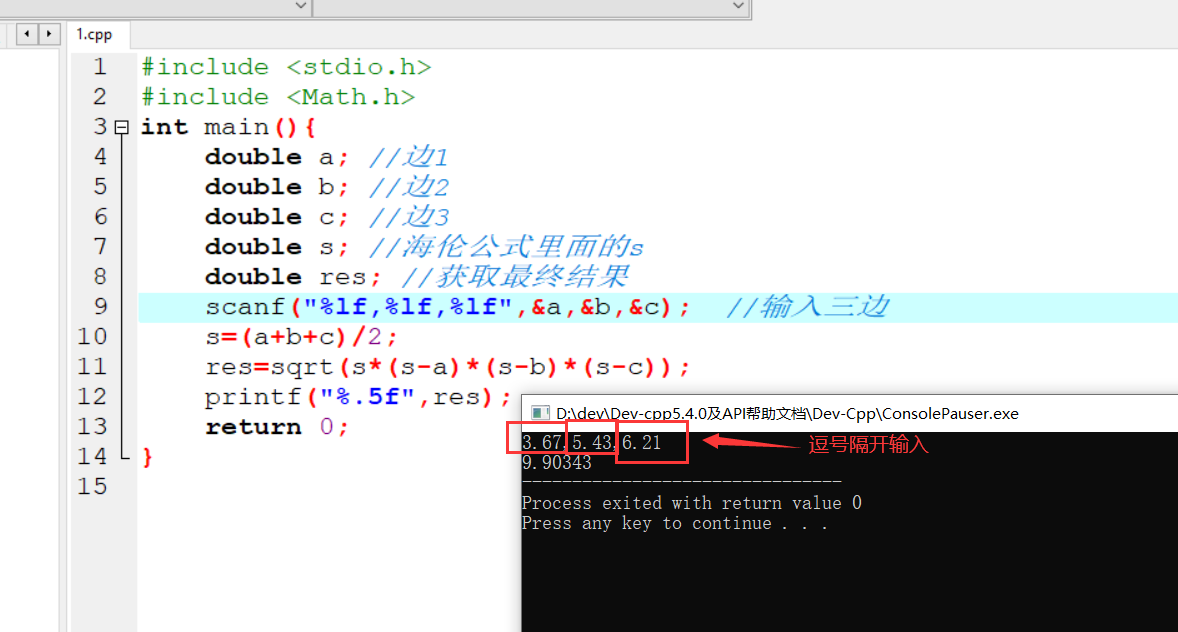
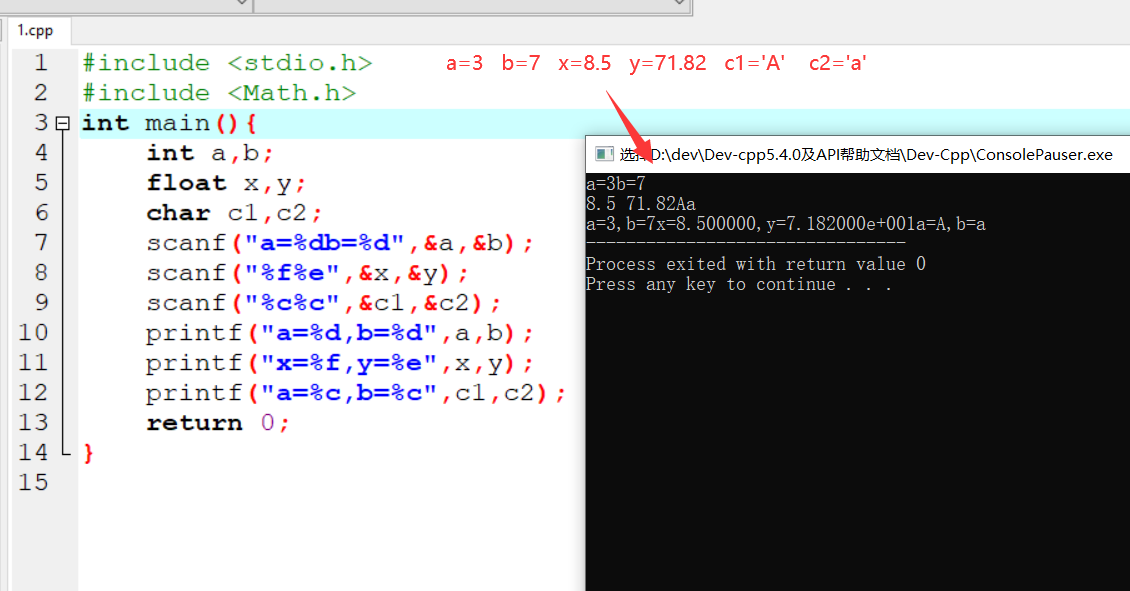
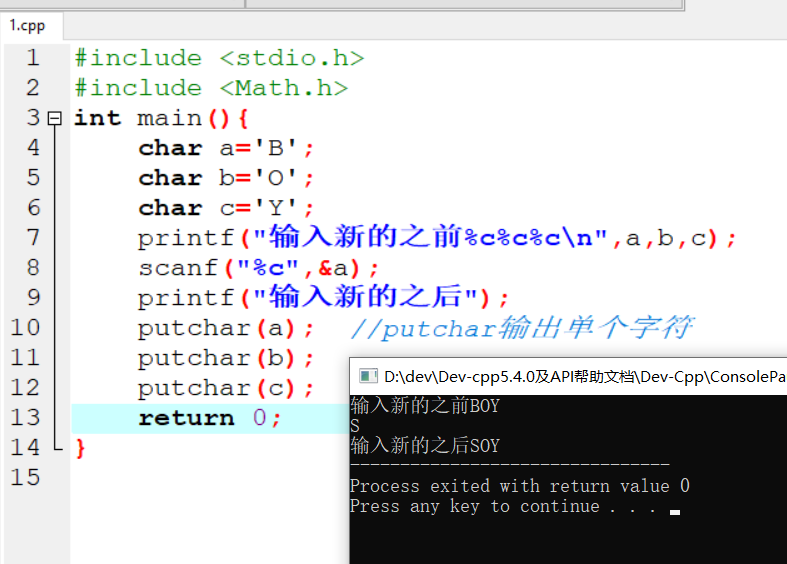
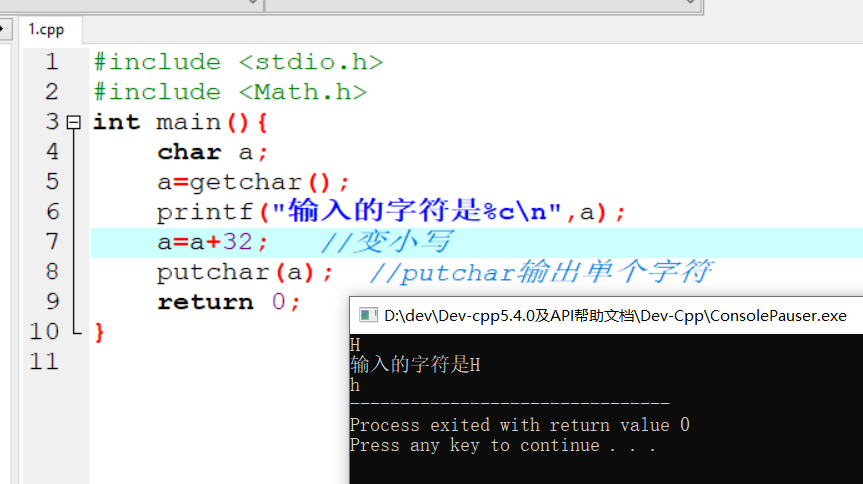
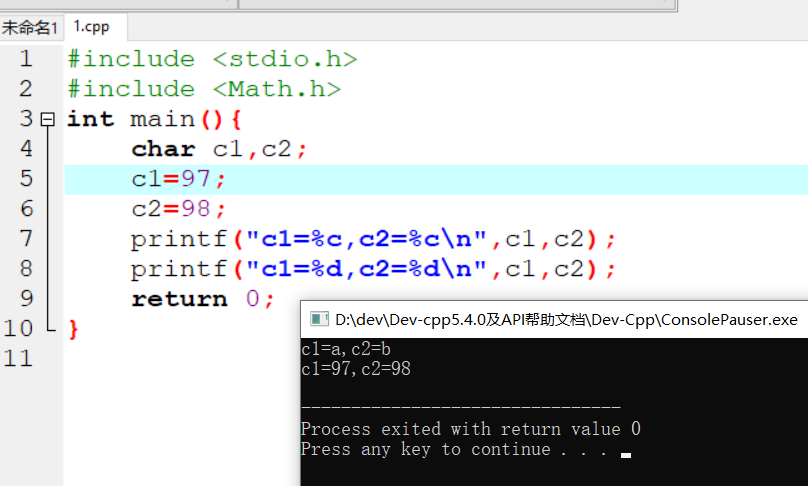
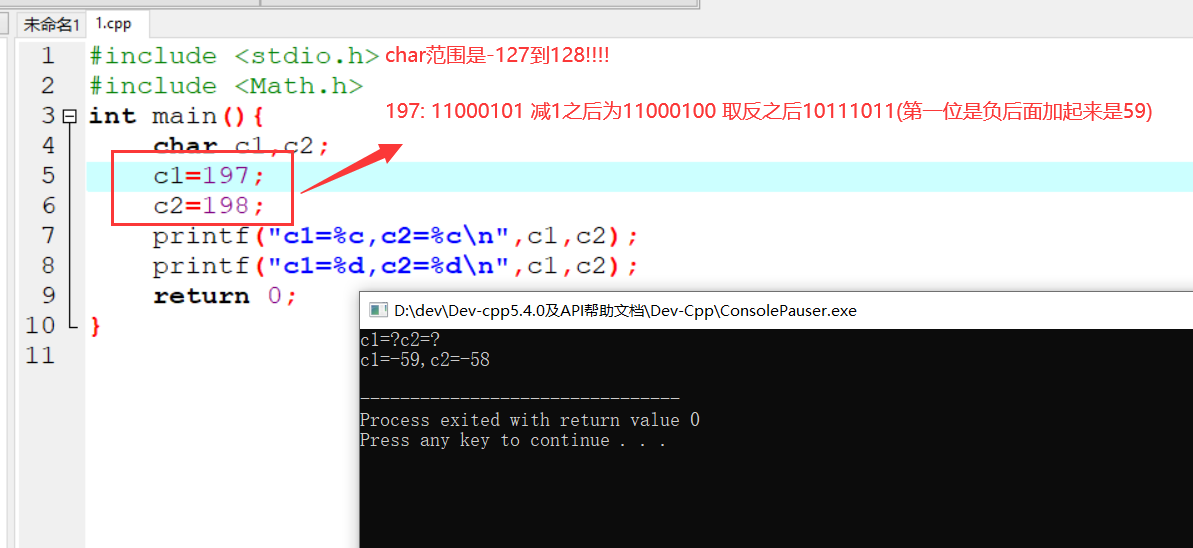
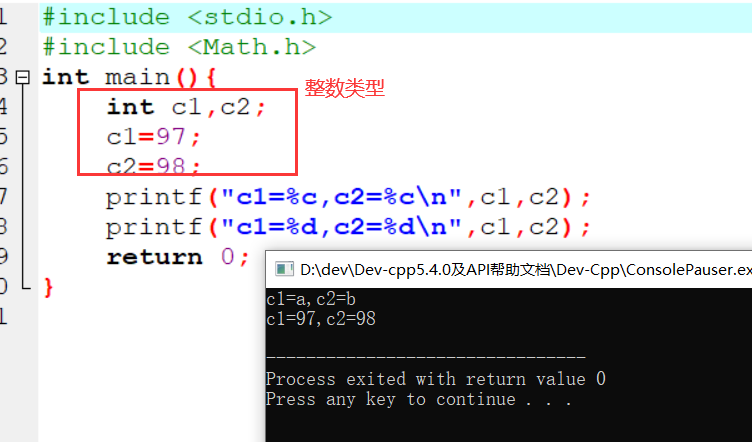
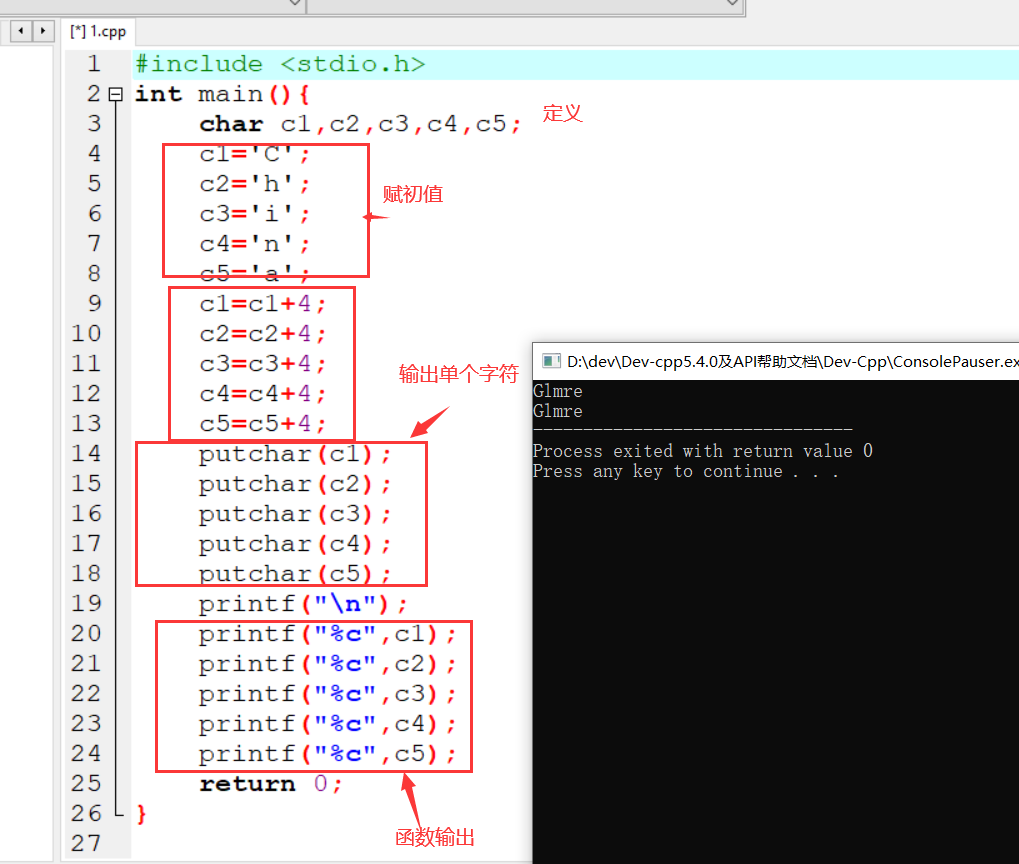
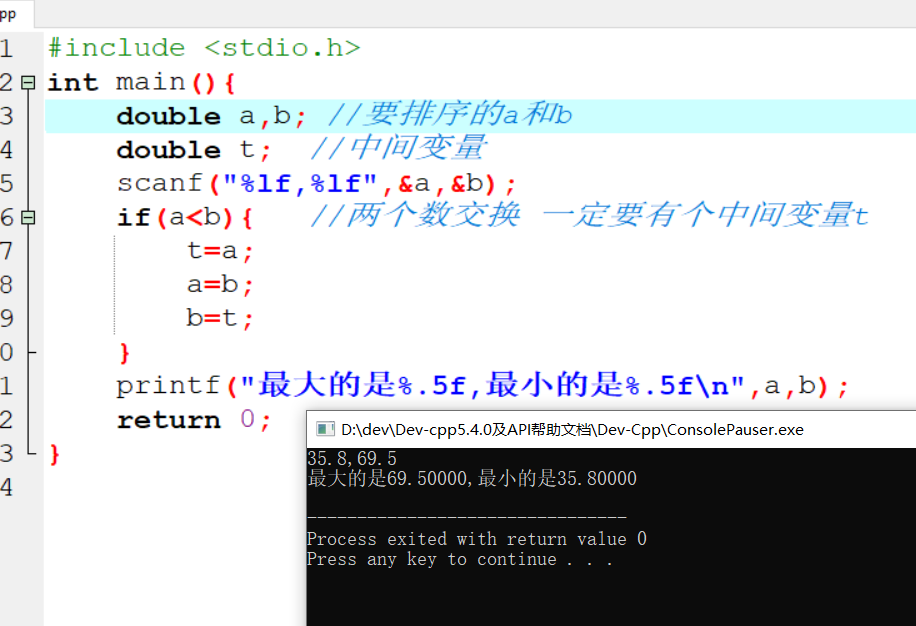
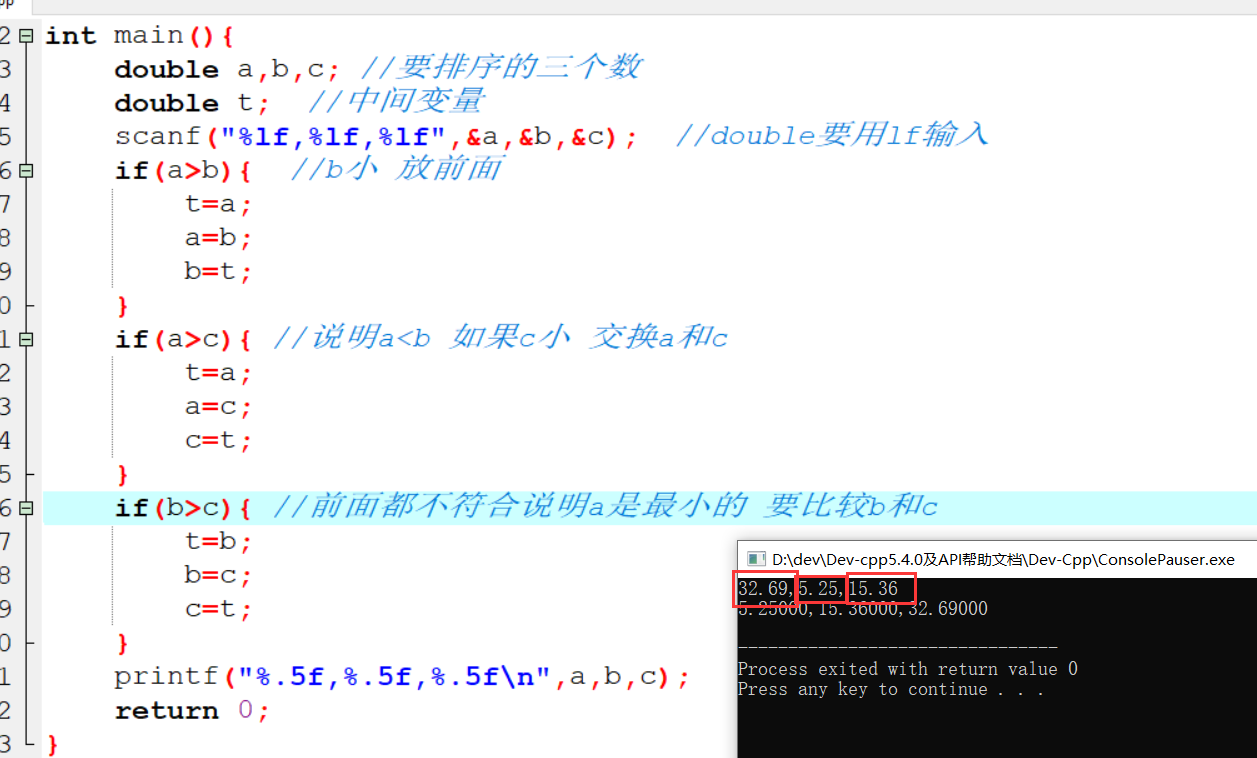
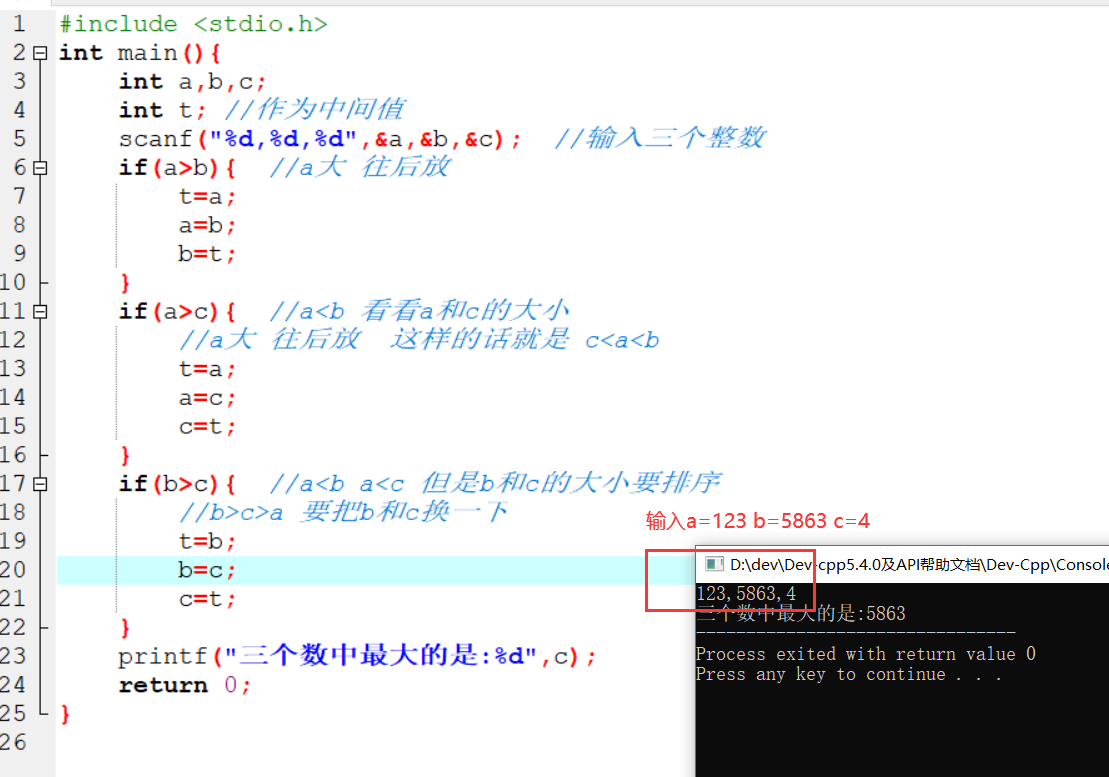
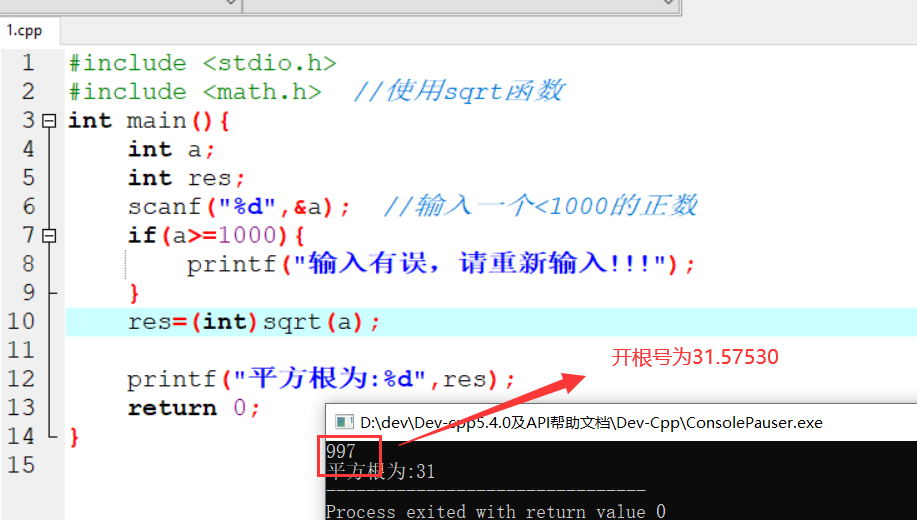
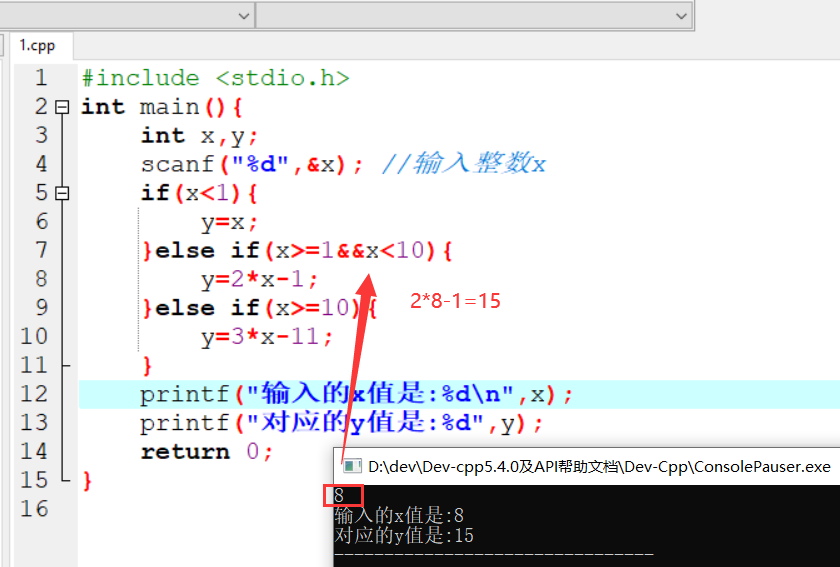
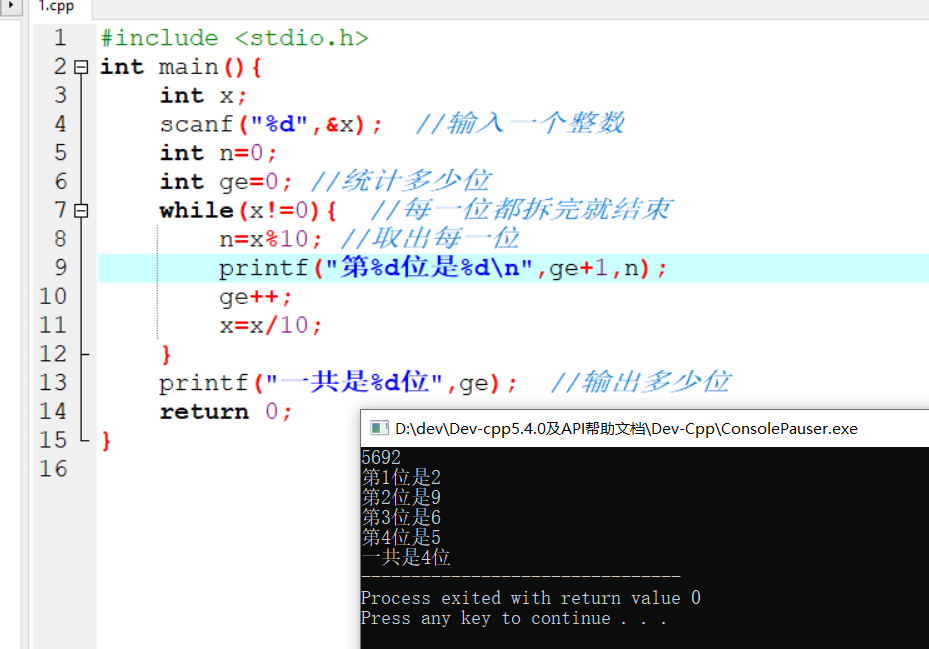
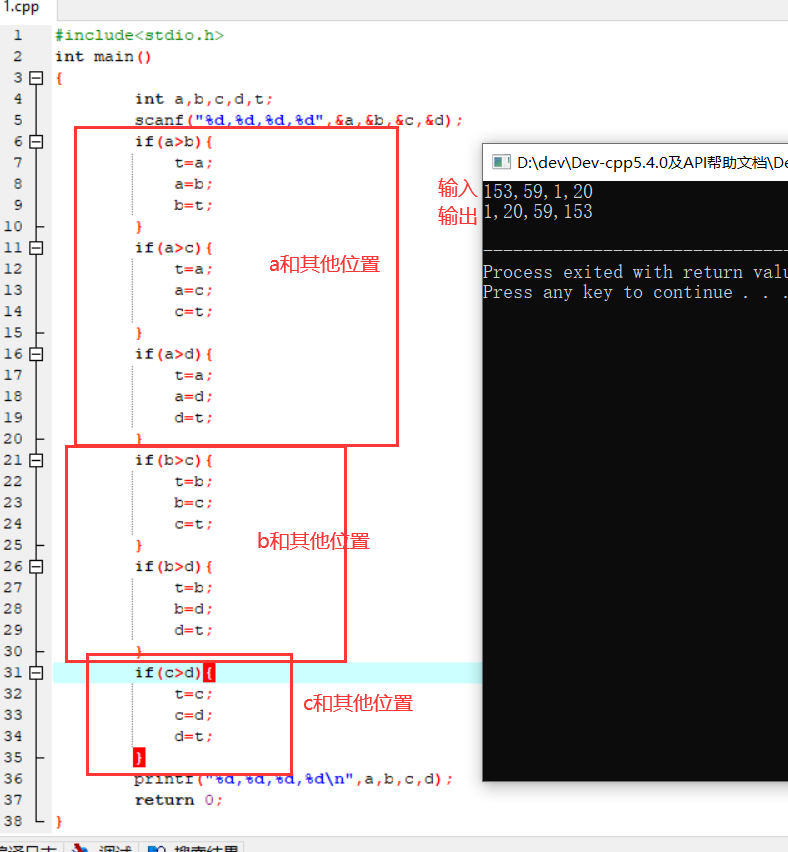
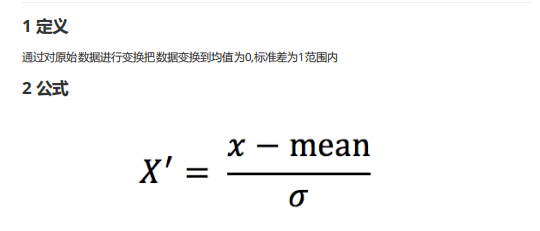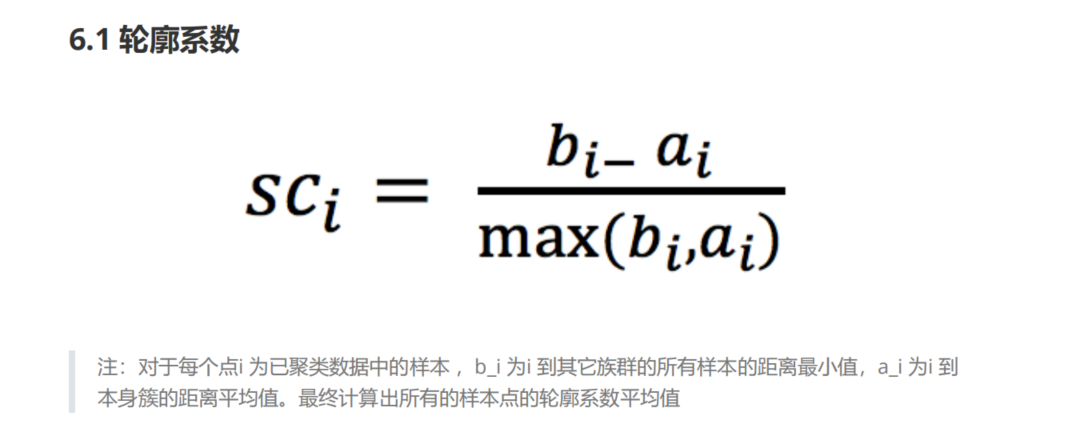变量
2.1 简单消息
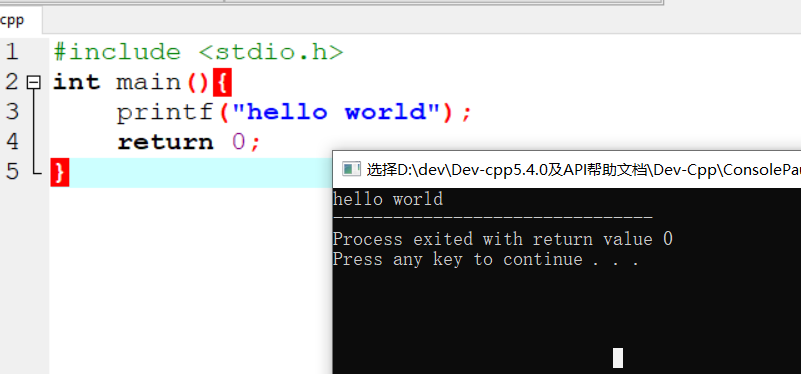
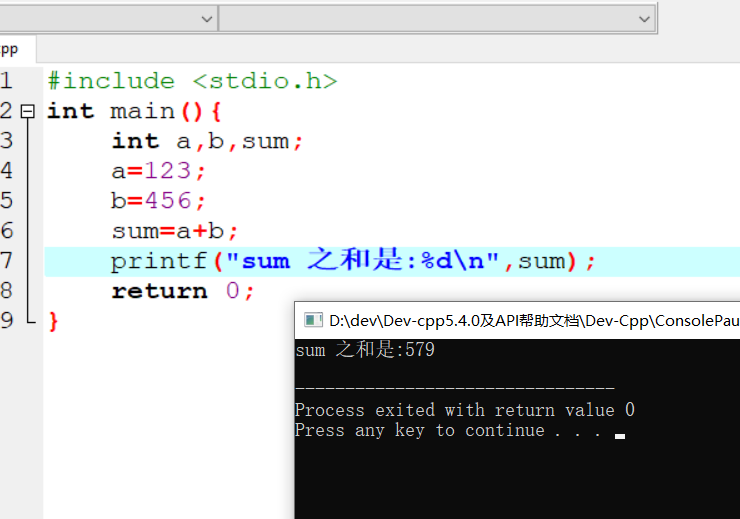
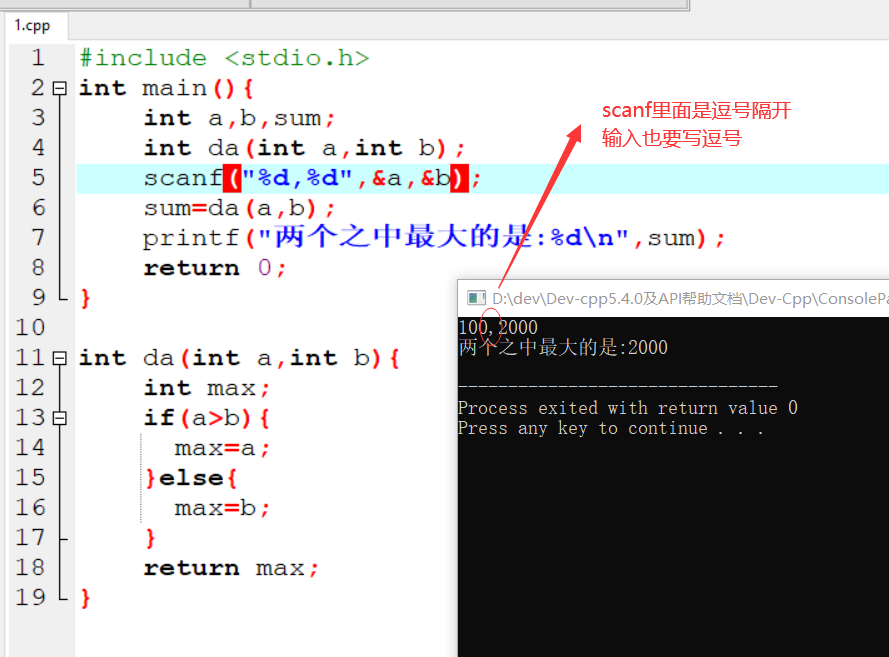
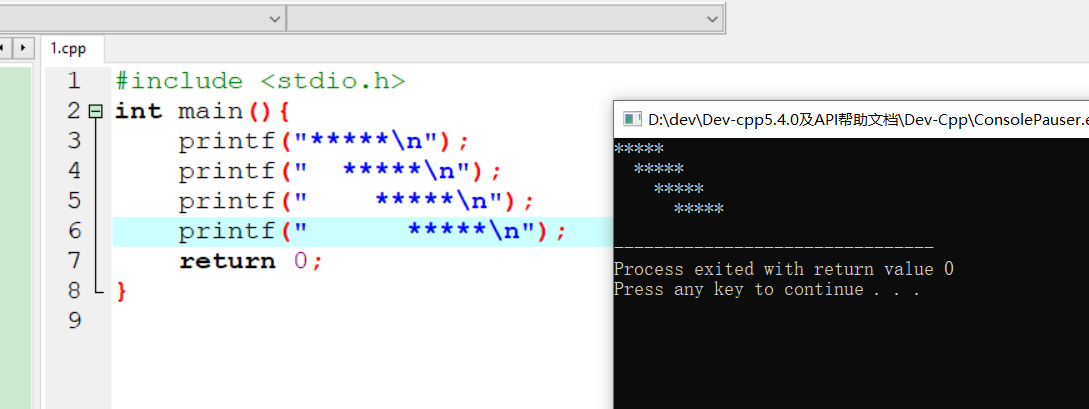
具体代码
1 |
|
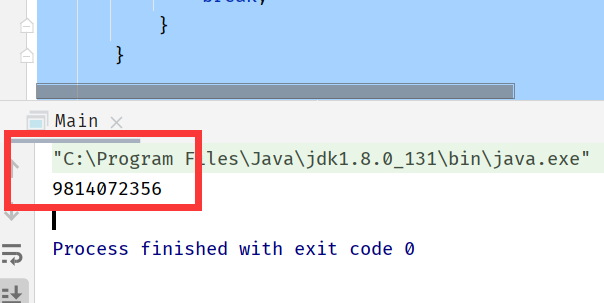
执行结果
2.2 多条简单消息
具体代码
1 |
|
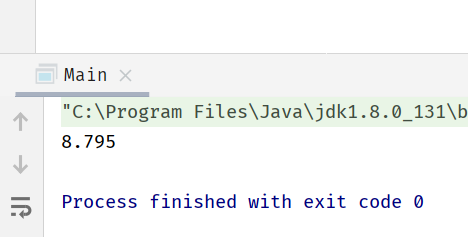
执行结果
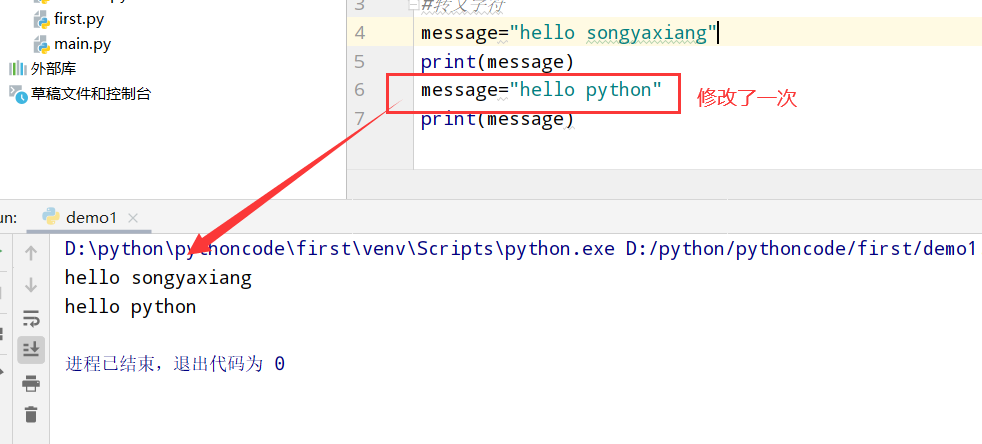
2.3 个性化消息
具体代码
1 |
|
执行结果

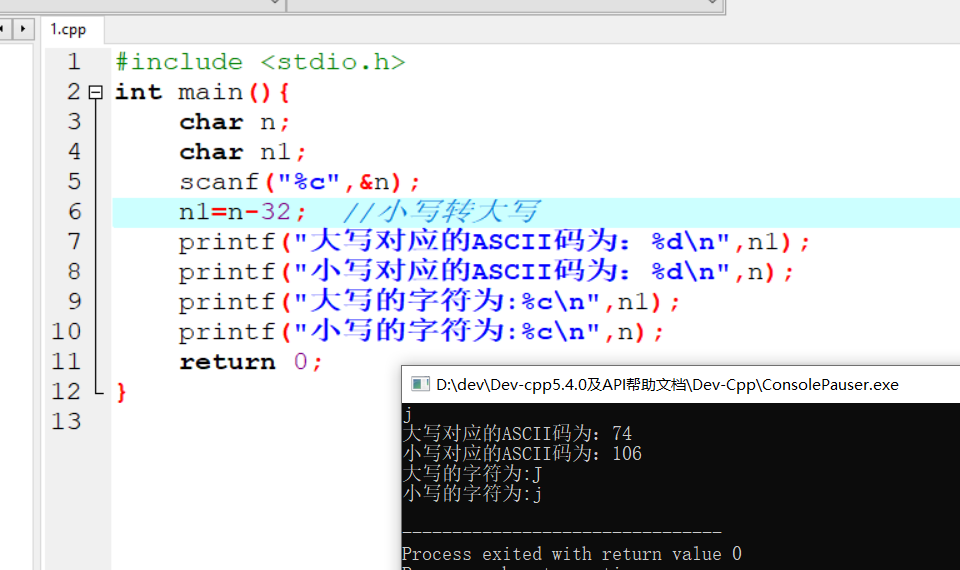
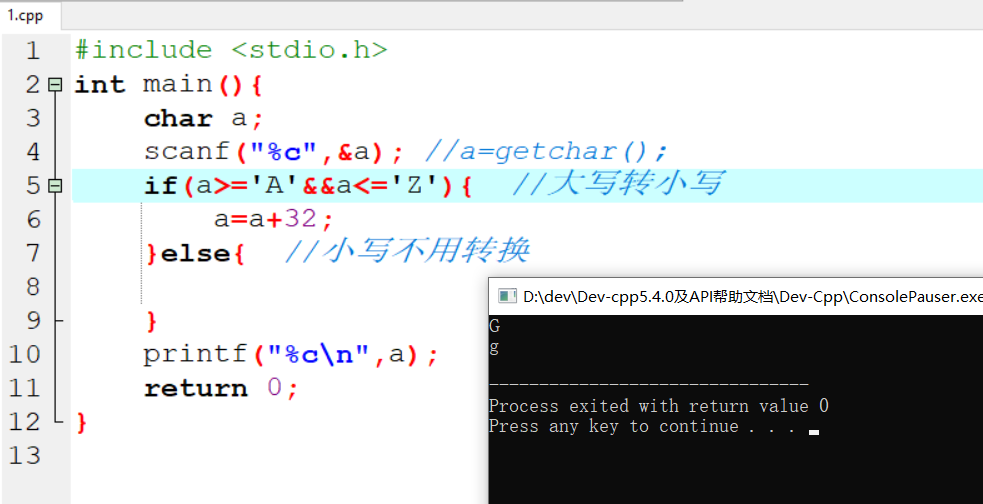
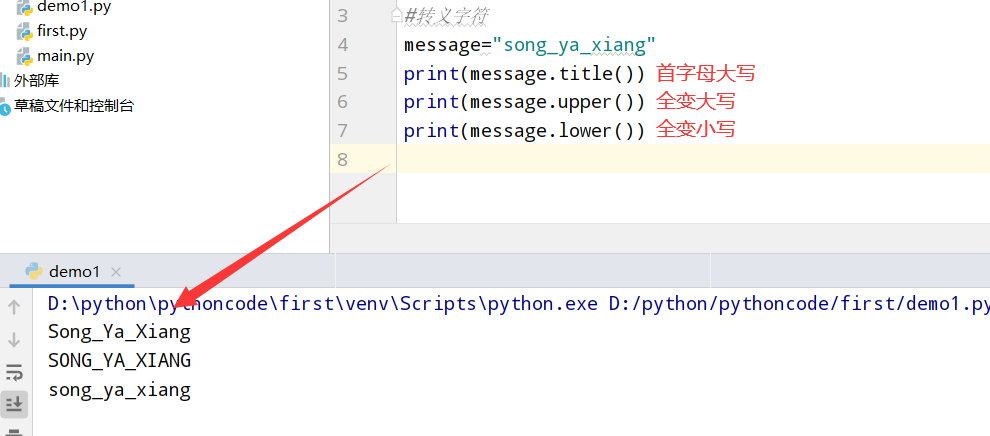
2.4 调整名字的大小写
具体代码
1 |
|
执行结果
2.5 名言
具体代码
1 |
|
执行结果

2.6 名言2
具体代码
1 |
|
执行结果

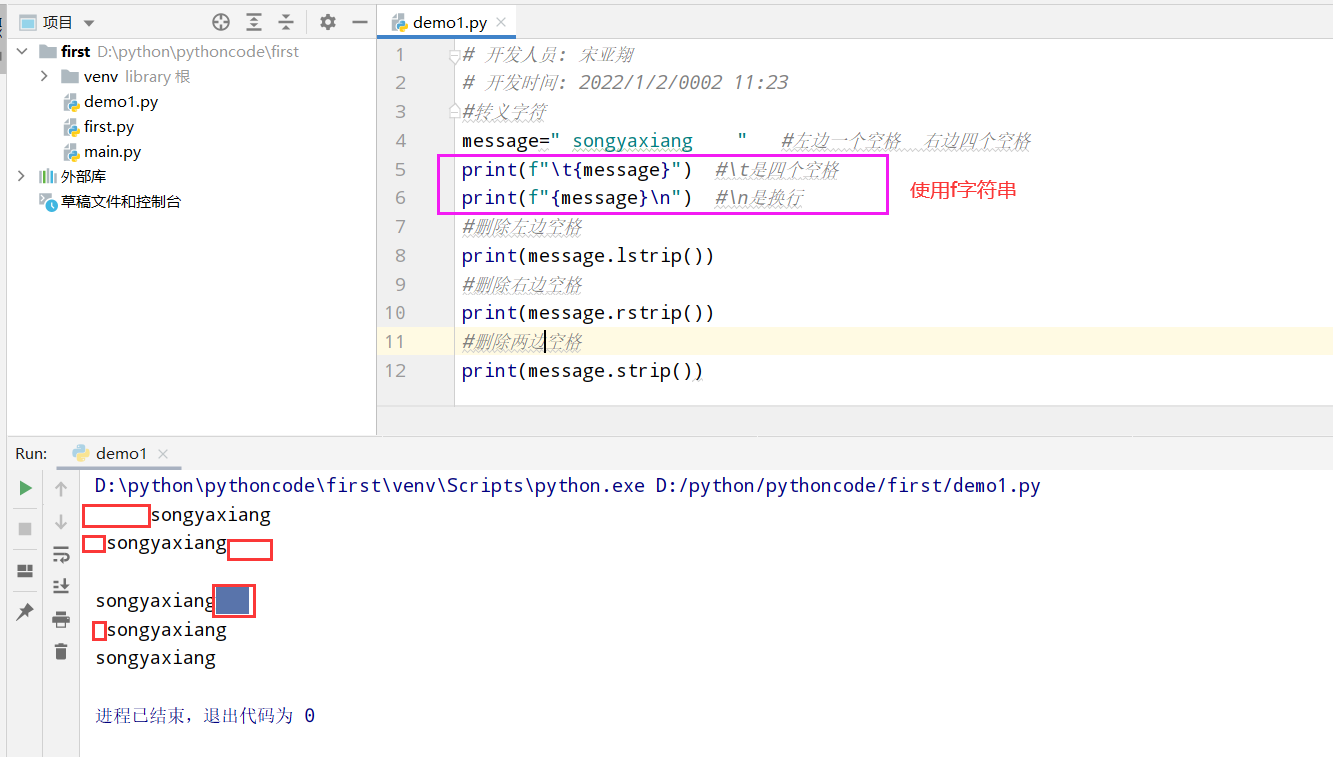
2.7 剔除人名中的空白
具体代码
1 |
|
执行结果
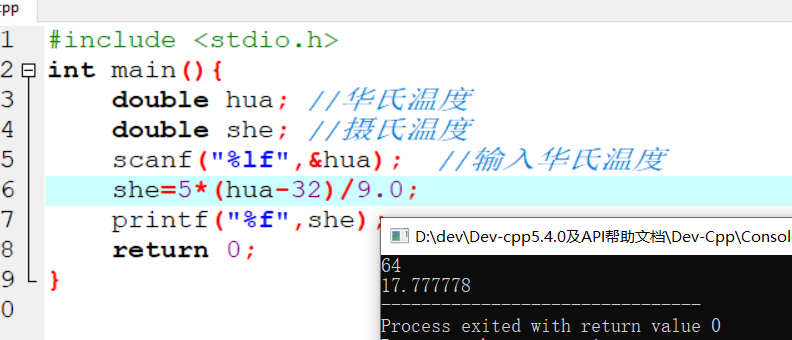
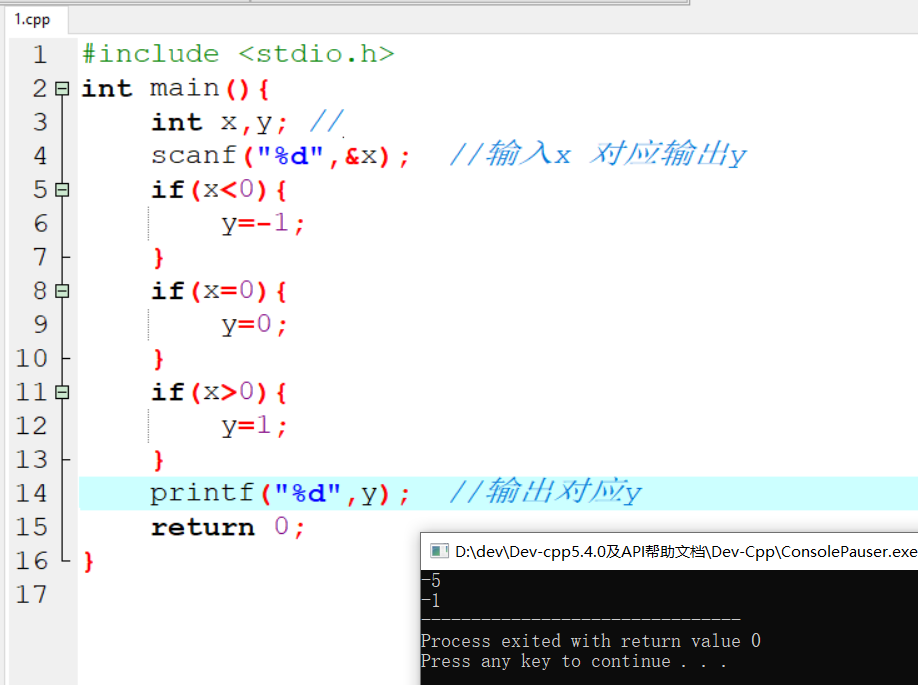
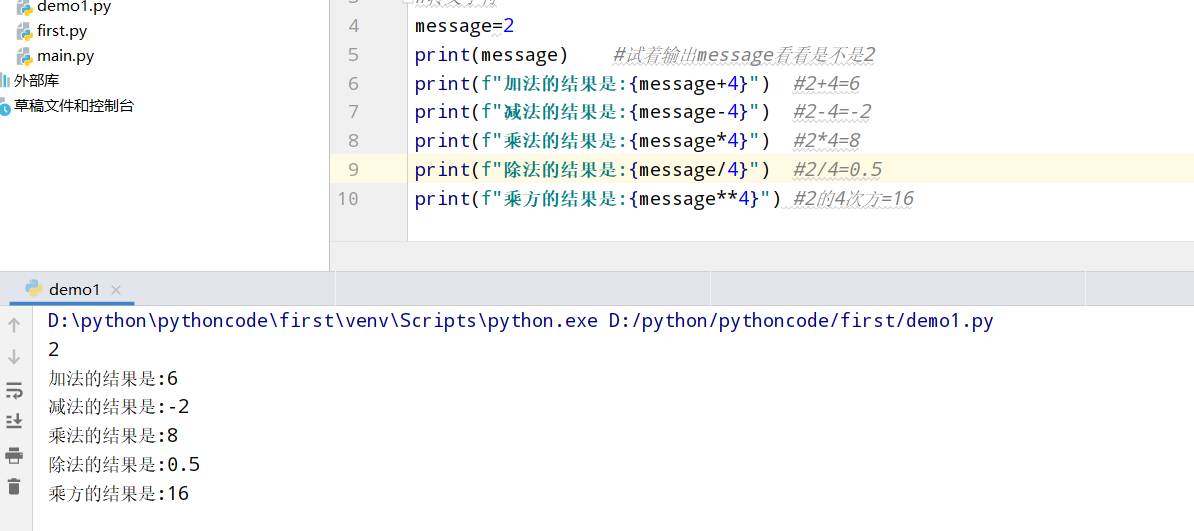
2.8 数字四则运算
具体代码
1 |
|
执行结果
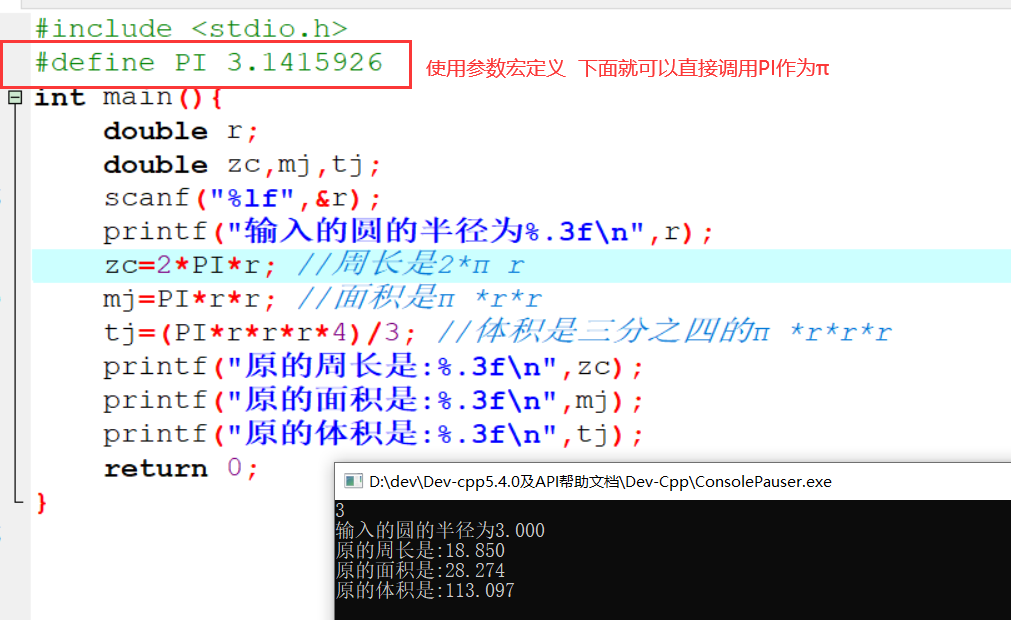
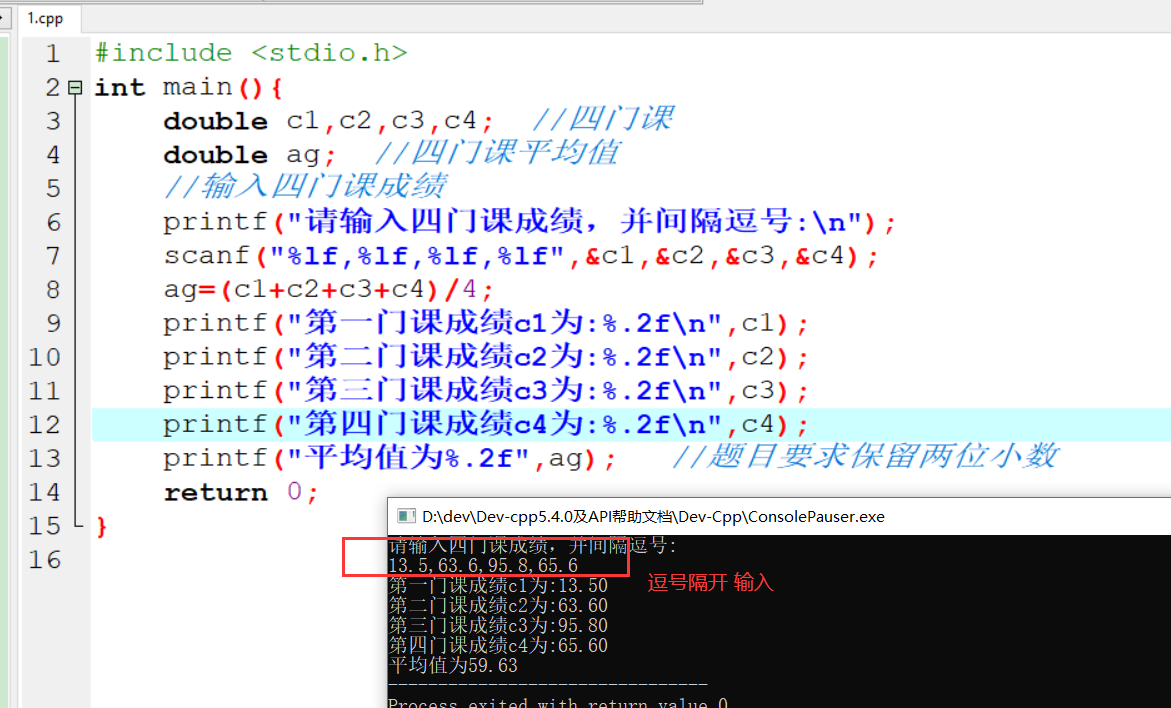
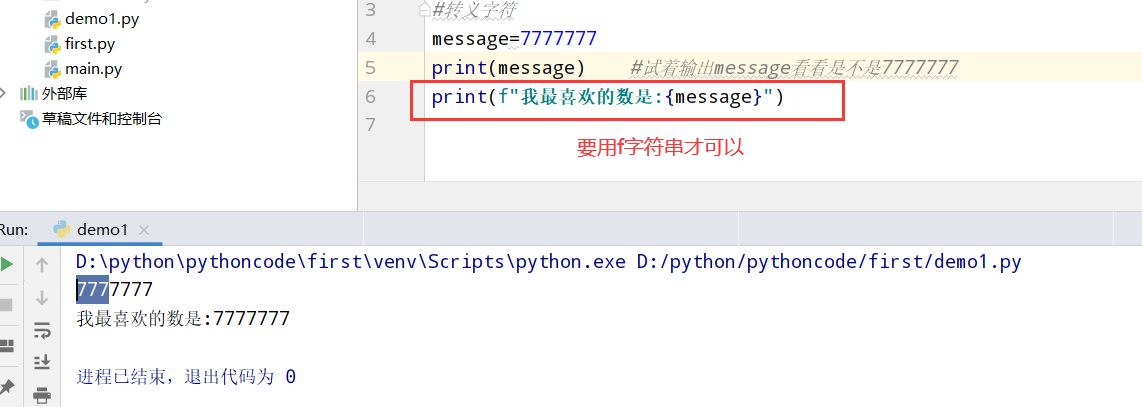
2.9 最喜欢的数
具体代码
1 |
|
执行结果
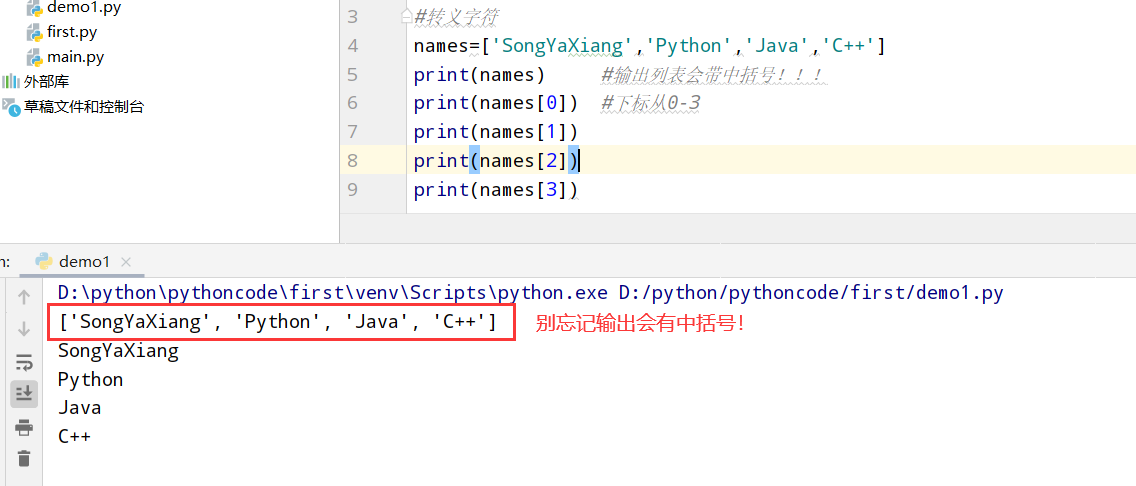
列表基本内容
3.1 姓名
具体代码
1 |
|
执行结果
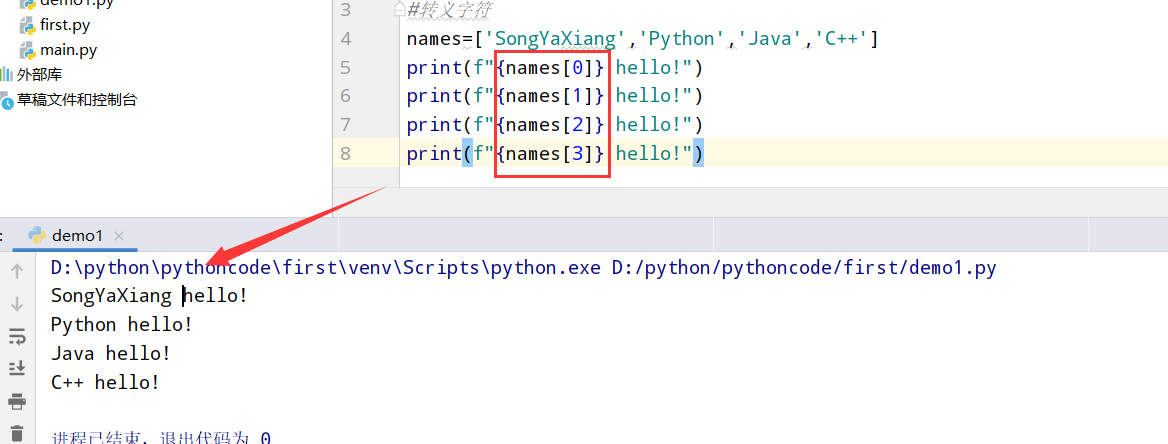
3.2 问候语
具体代码
1 |
|
执行结果
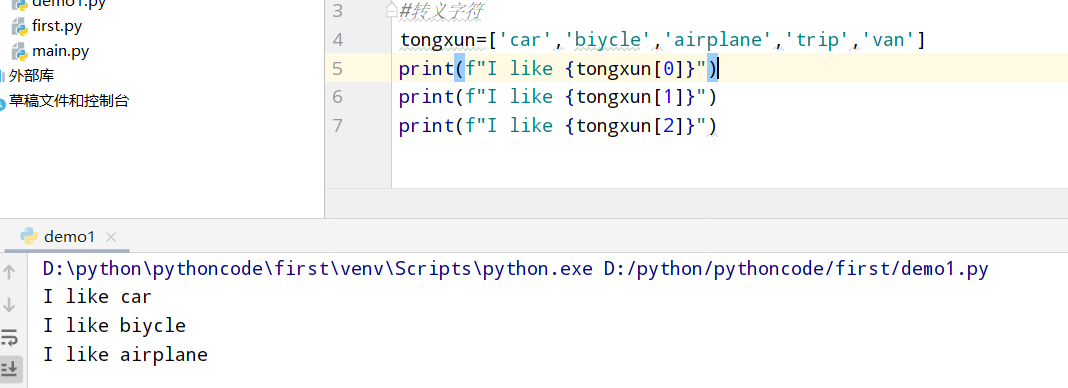
3.3 自己的列表
具体代码
1 |
|
执行结果
3.4-3.7 嘉宾名单
具体代码
1 |
|
执行结果

3.8 放眼世界(排序/翻转)
具体代码
1 |
|
执行结果

3.9 嘉宾长度
具体代码
1 |
|
执行结果
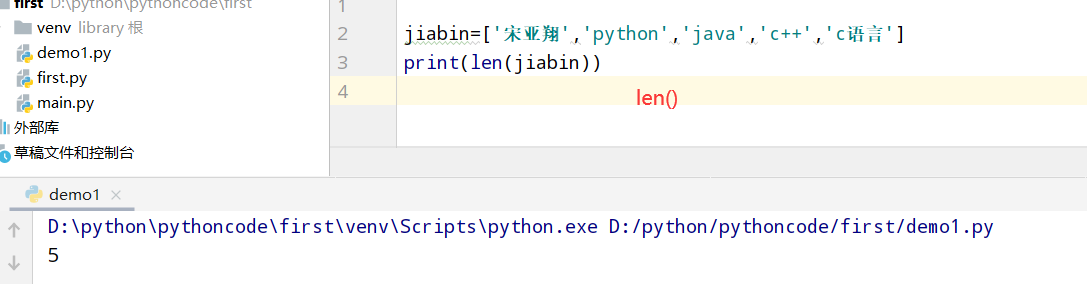
列表进阶内容
4.1 比萨
具体代码
1 |
|
执行结果
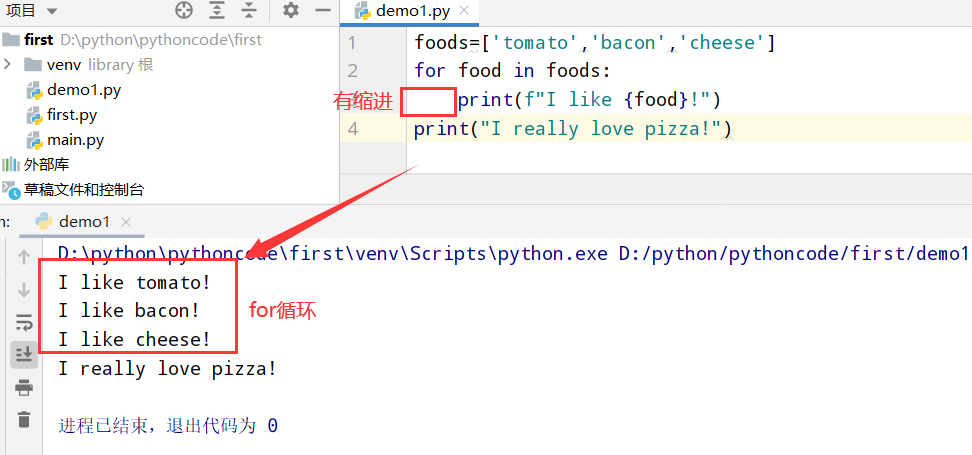
4.2 动物
具体代码
1 |
|
执行结果
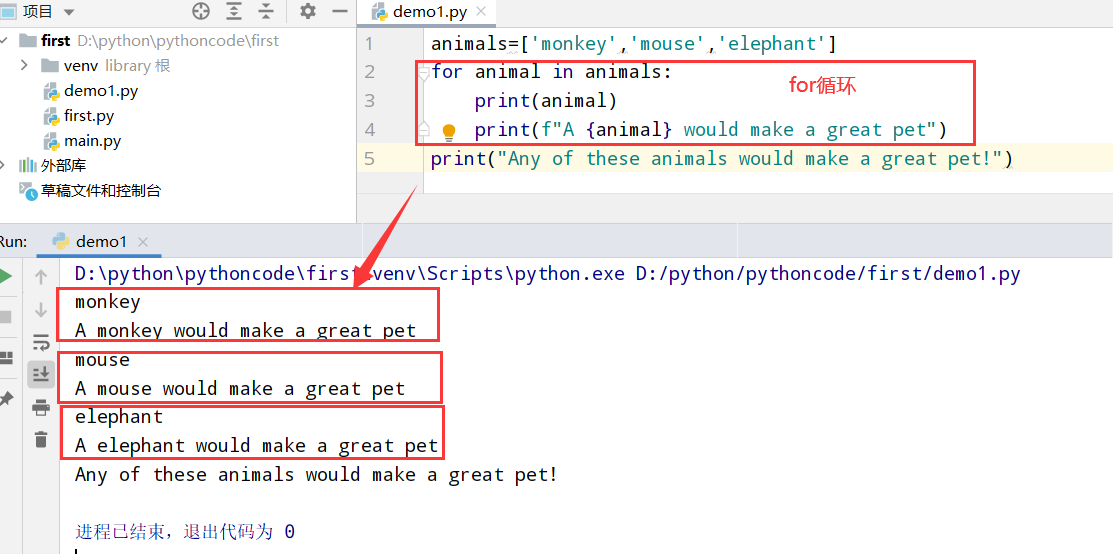
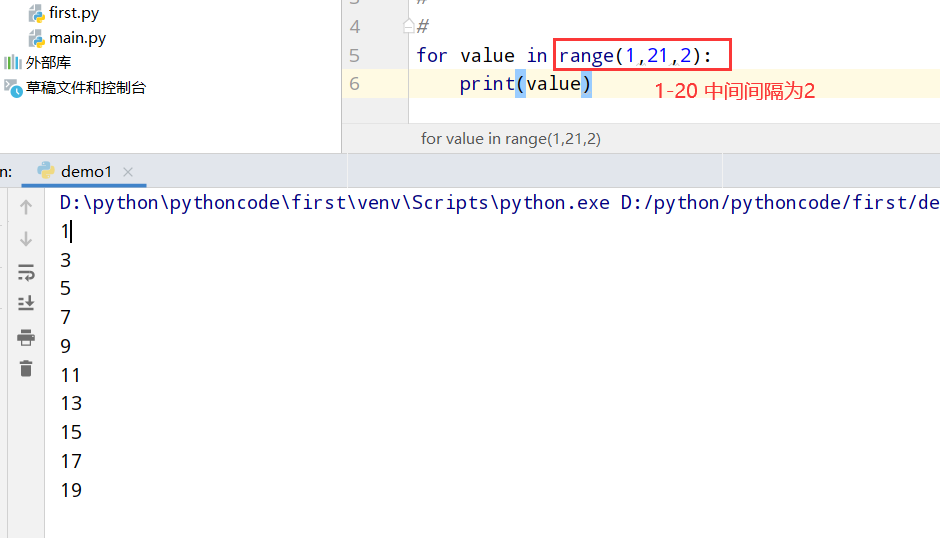
4.3 for循环输出1-20
具体代码
1 |
|
执行结果
4.4 一百万
具体代码
1 |
|
执行结果
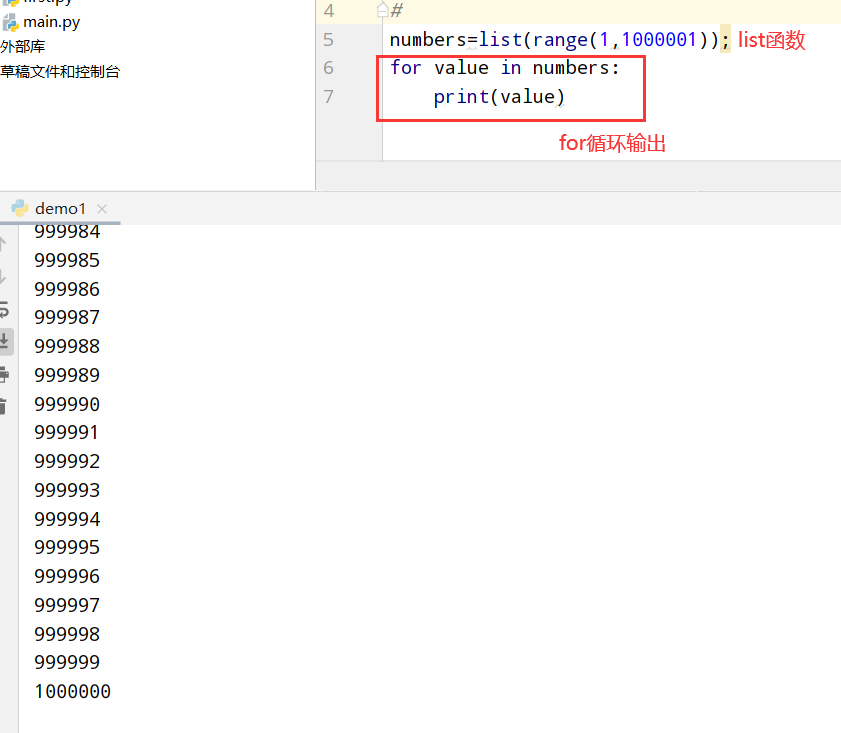
4.5 一百万求和
具体代码
1 |
|
执行结果
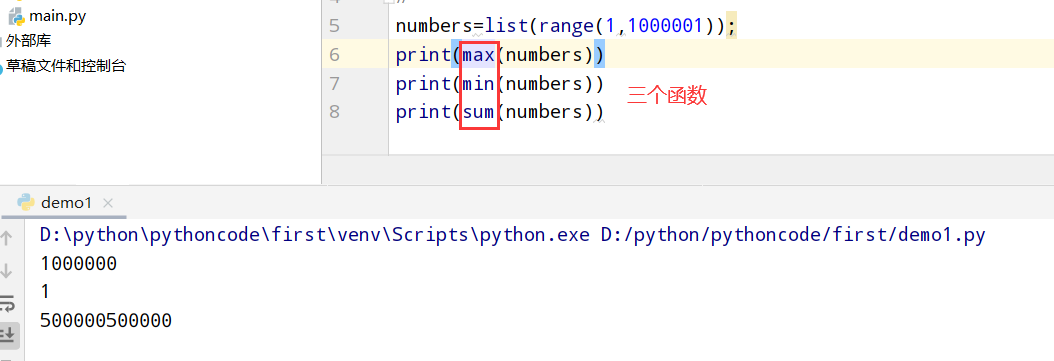
4.6 循环打印奇数
具体代码
1 |
|
执行结果
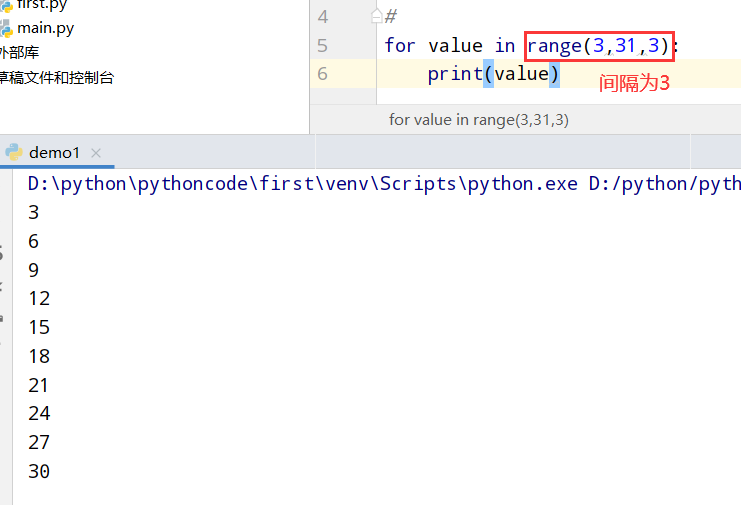
4.7 循环打印3的倍数
具体代码
1 |
|
执行结果
4.8 循环打印某些数的立方
具体代码
1 |
|
执行结果
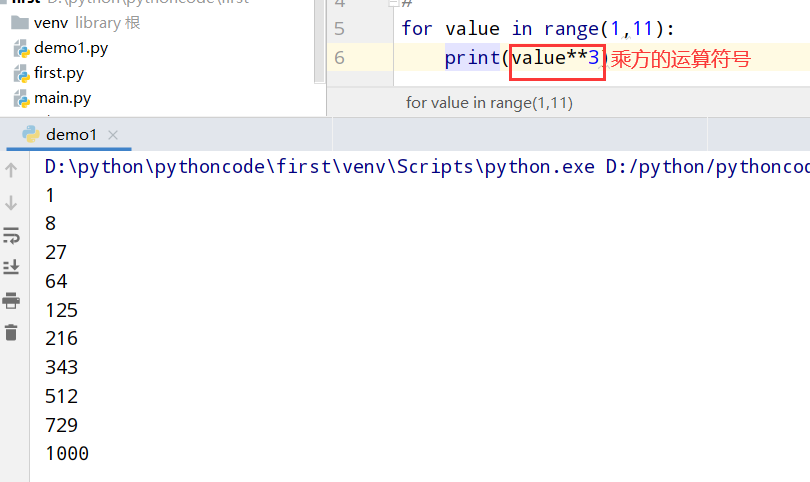
4.9 立方解析(列表解析)
具体代码
1 |
|
执行结果
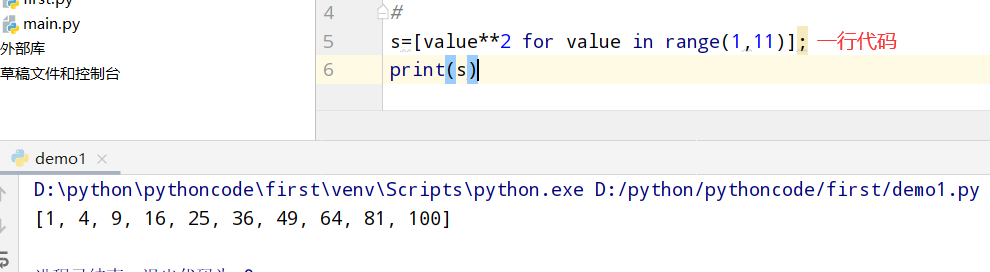
4.10 切片
具体代码
1 |
|
执行结果
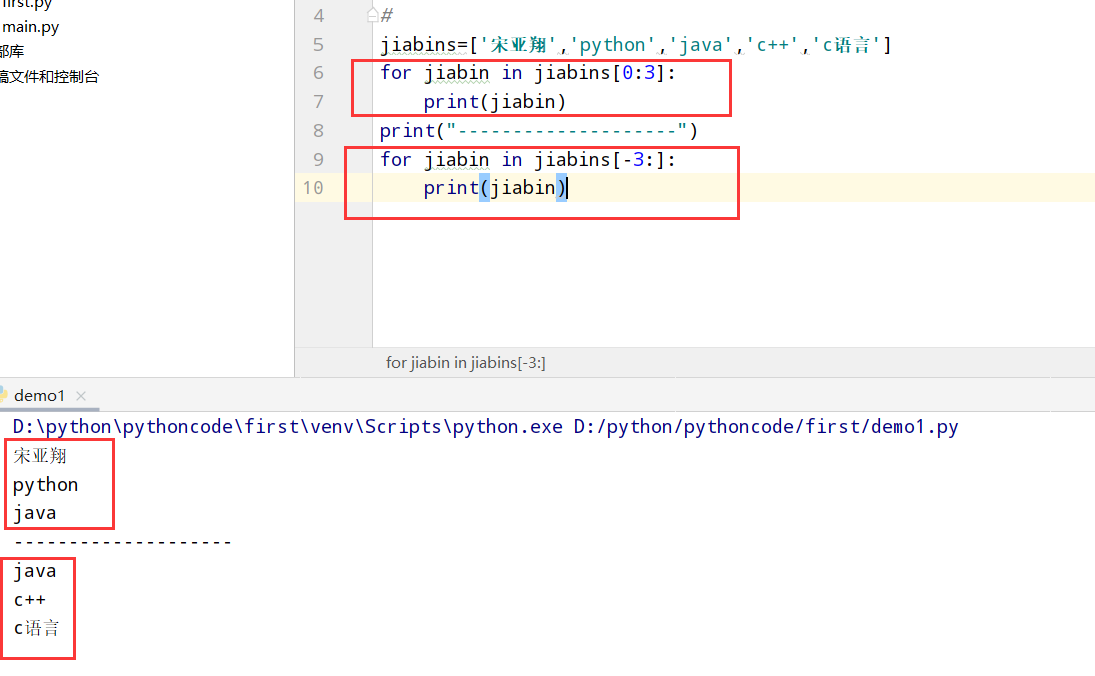
4.11 你的比萨,我的比萨
具体代码
1 |
|
执行结果
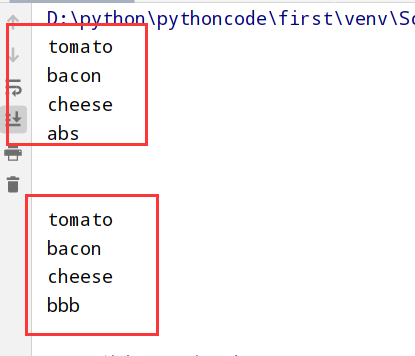
4.13 自助餐
具体代码
1 |
|
执行结果
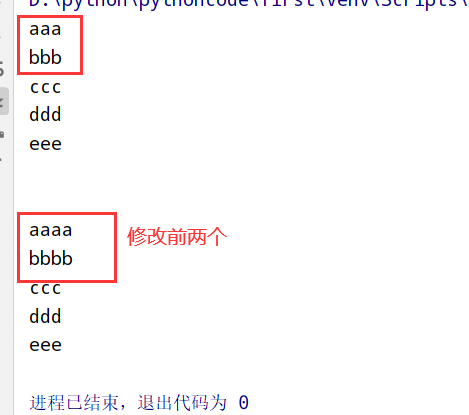
if语句
5.3 外星人颜色
具体代码
1 |
|
执行结果
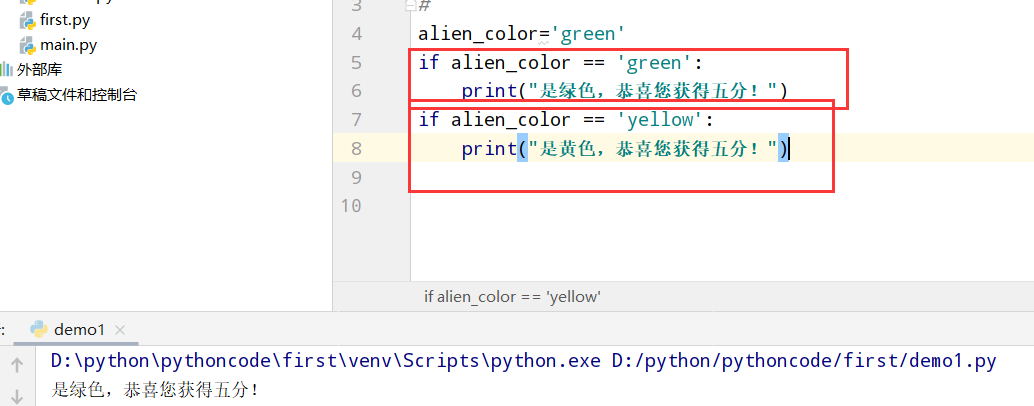
5.4 外星人颜色2
具体代码
1 |
|
执行结果
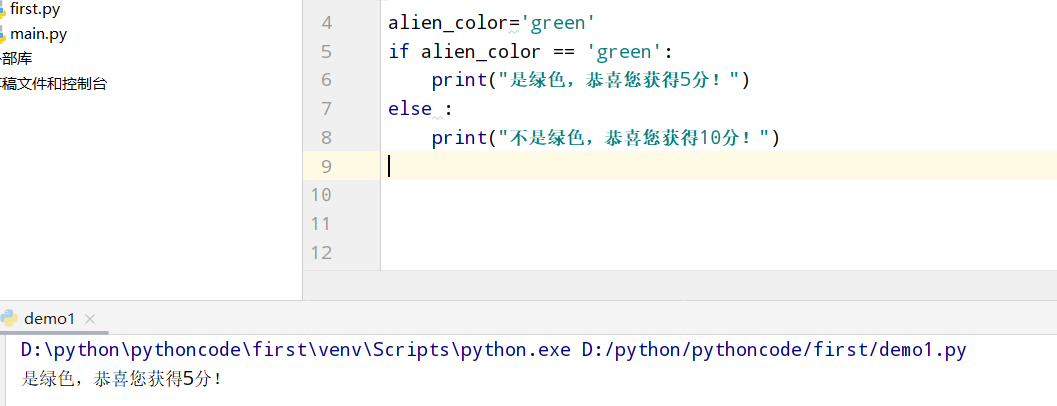
5.5 外星人颜色3
具体代码
1 |
|
执行结果
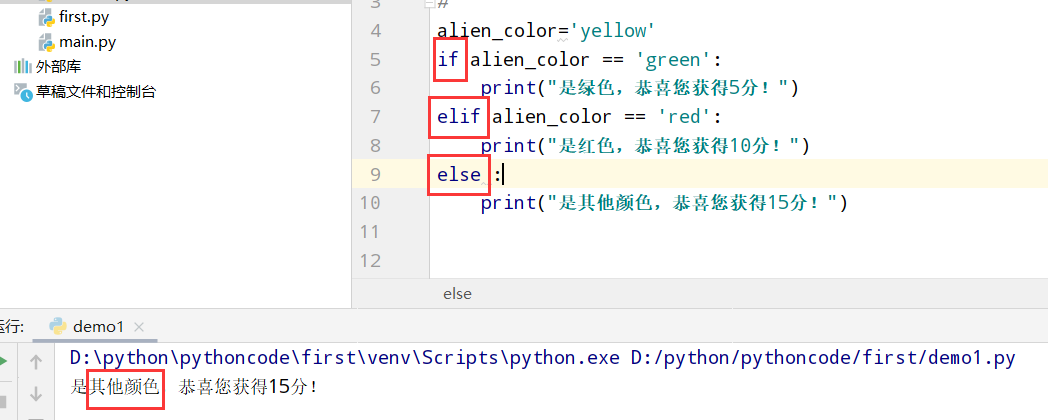
5.6 人生的不同阶段
具体代码
1 |
|
执行结果
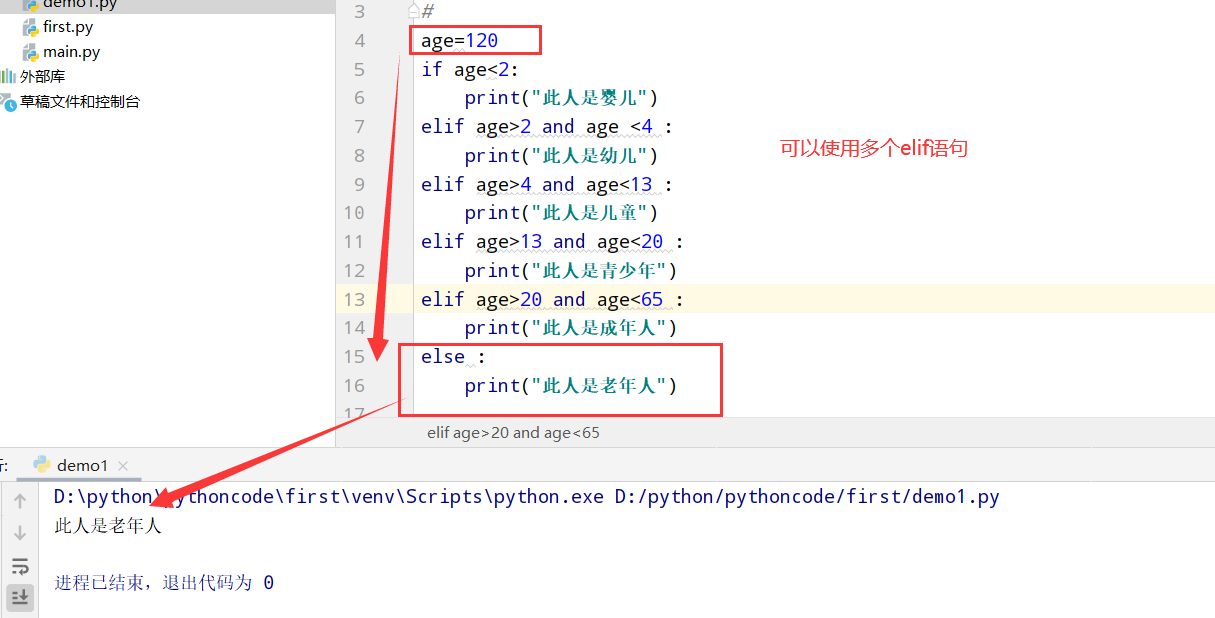
5.7 喜欢的水果
具体代码
1 |
|
执行结果
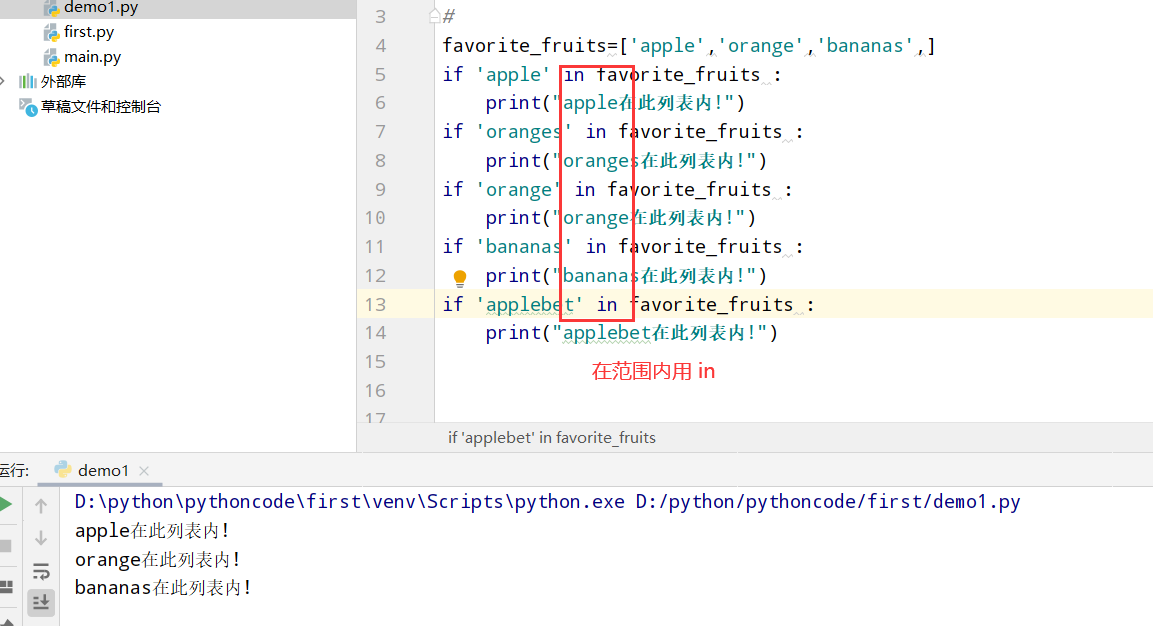
5.8 以特殊方式跟管理员打招呼
具体代码
1 |
|
执行结果
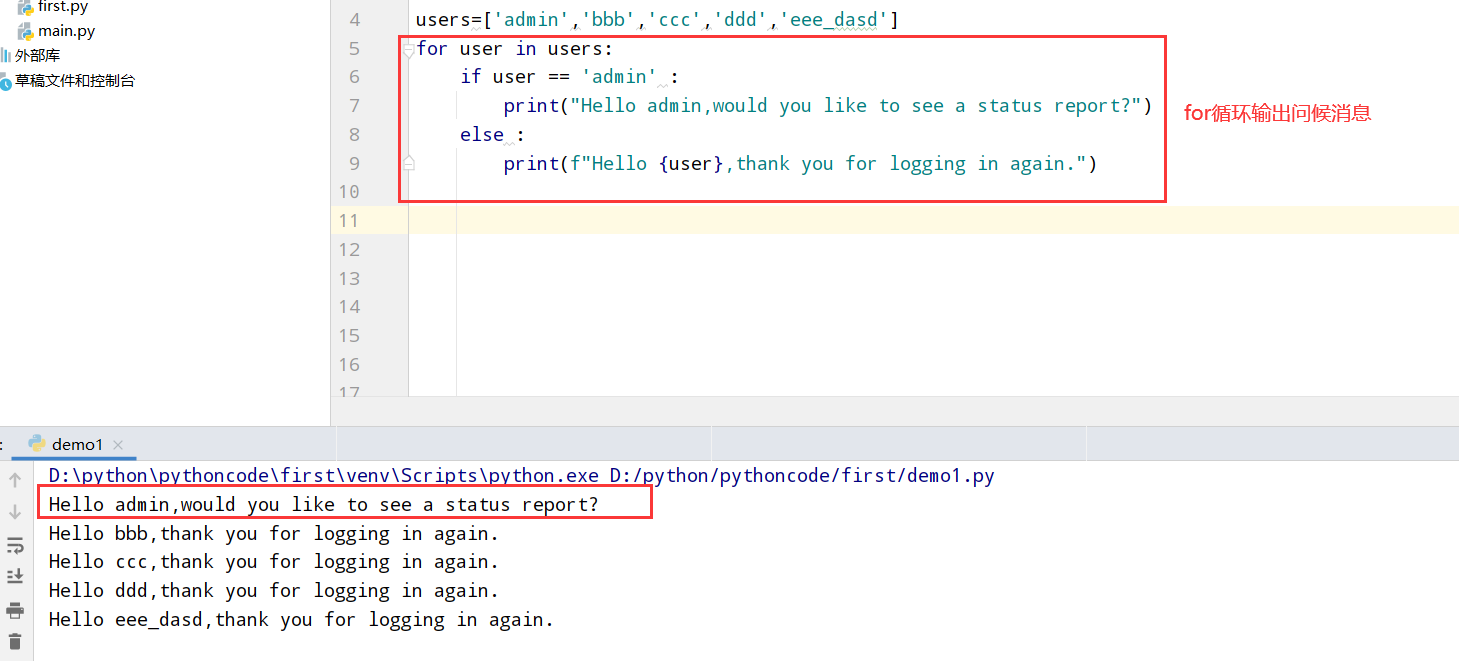
5.9 处理没有用户的情形
具体代码
1 |
|
执行结果
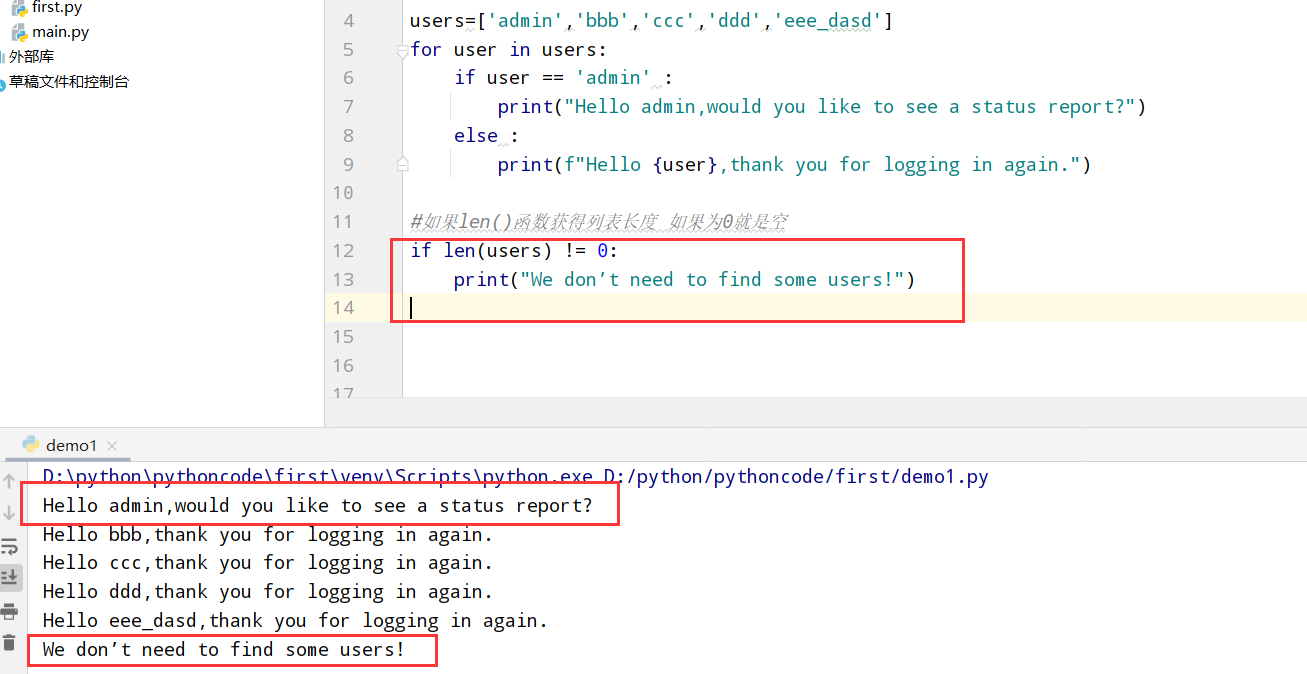
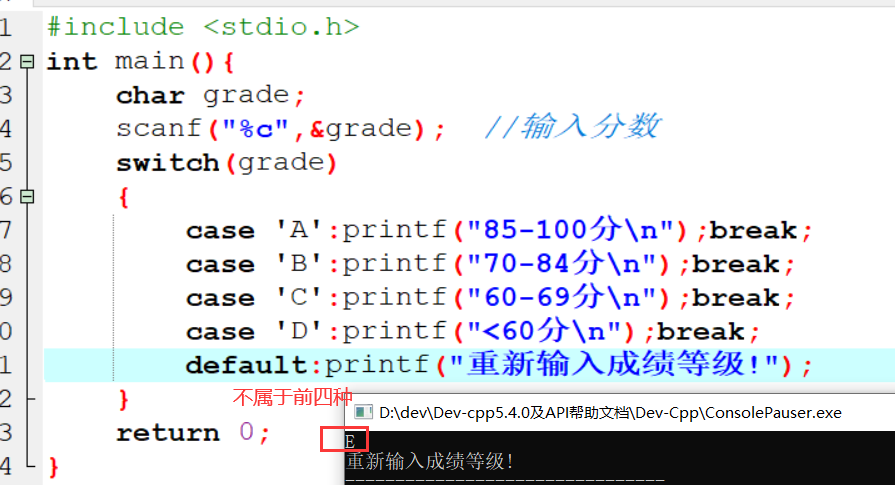
5.10 检查用户名
具体代码
1 |
|
执行结果
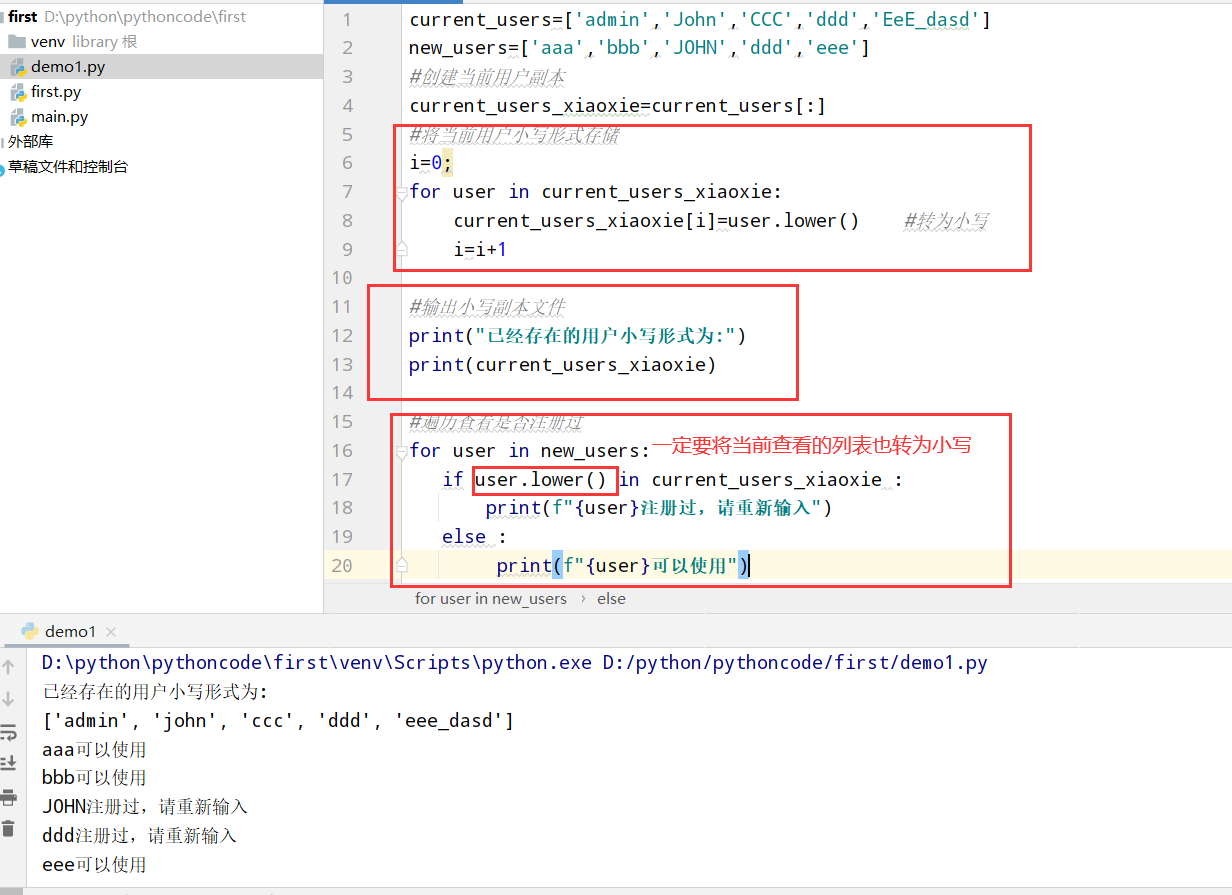
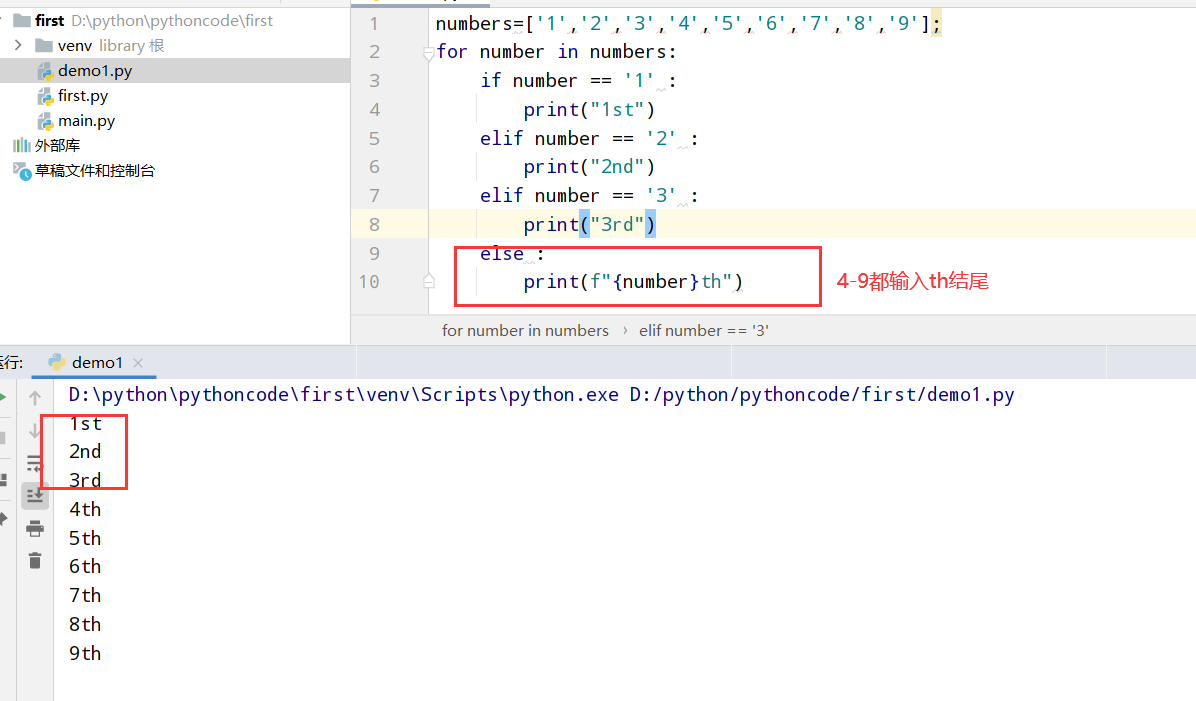
5.11 序数
具体代码
1 |
|
执行结果
字典
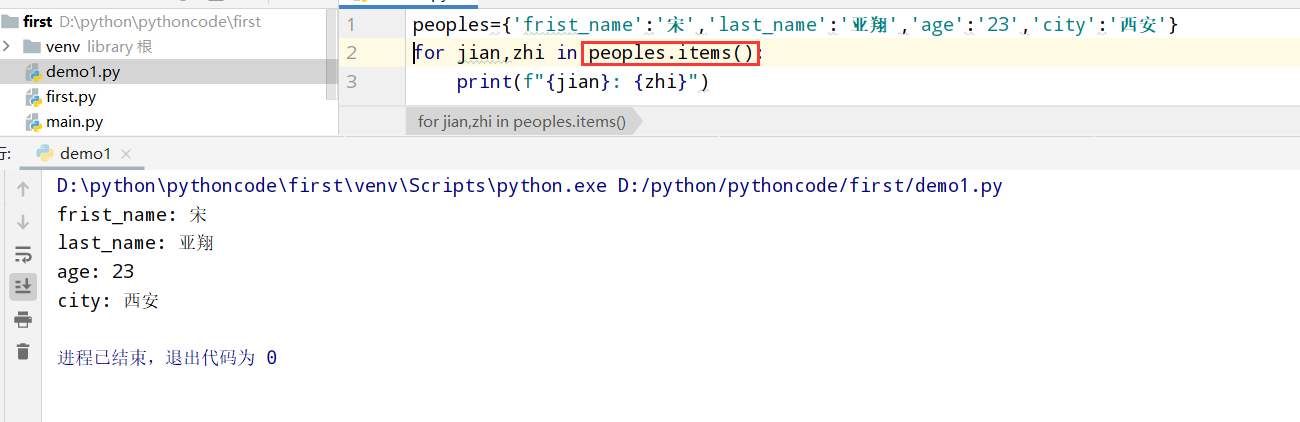
6.1 人
具体代码
1 |
|
执行结果
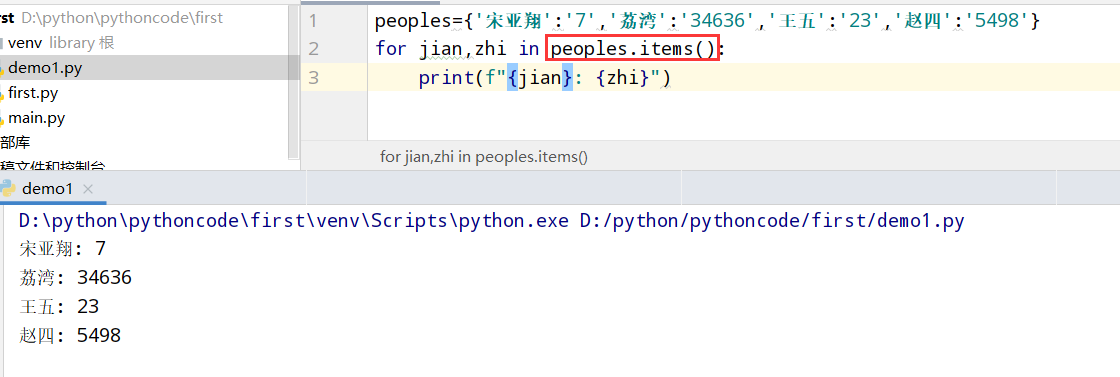
6.2 喜欢的数
具体代码
1 |
|
执行结果
6.3 词汇表
具体代码
1 |
|
执行结果
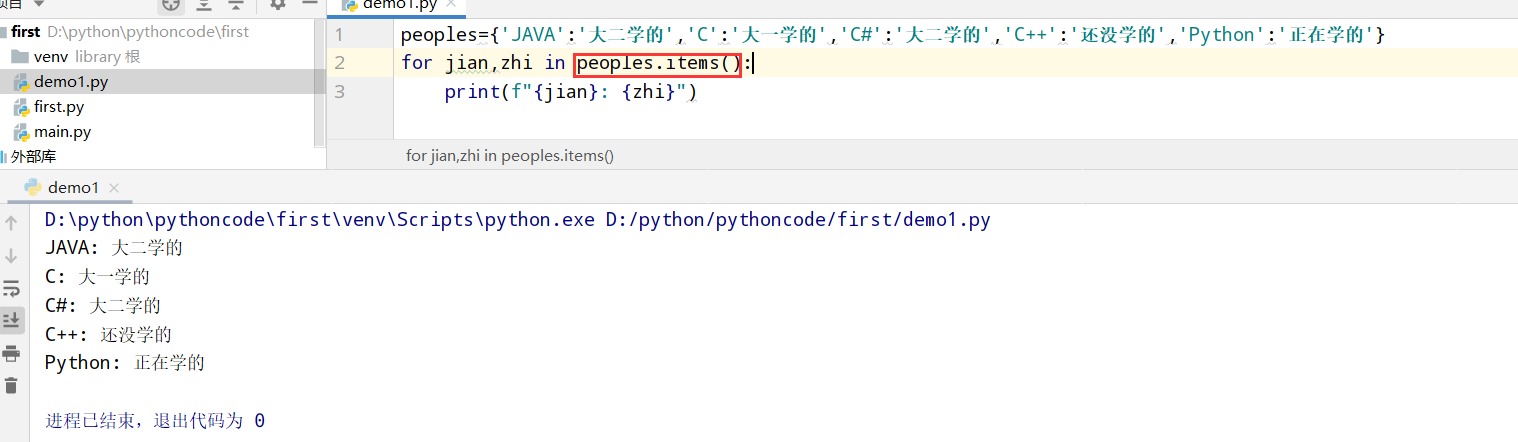
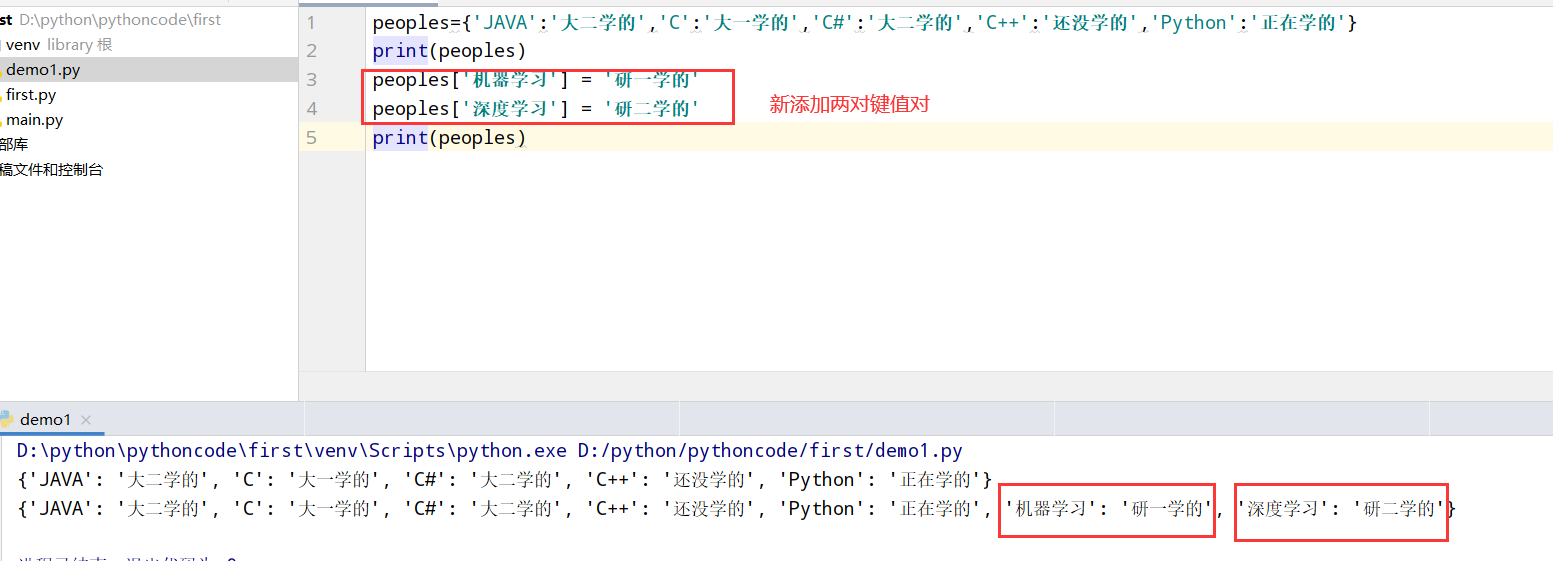
6.4 词汇表2
具体代码
1 |
|
执行结果
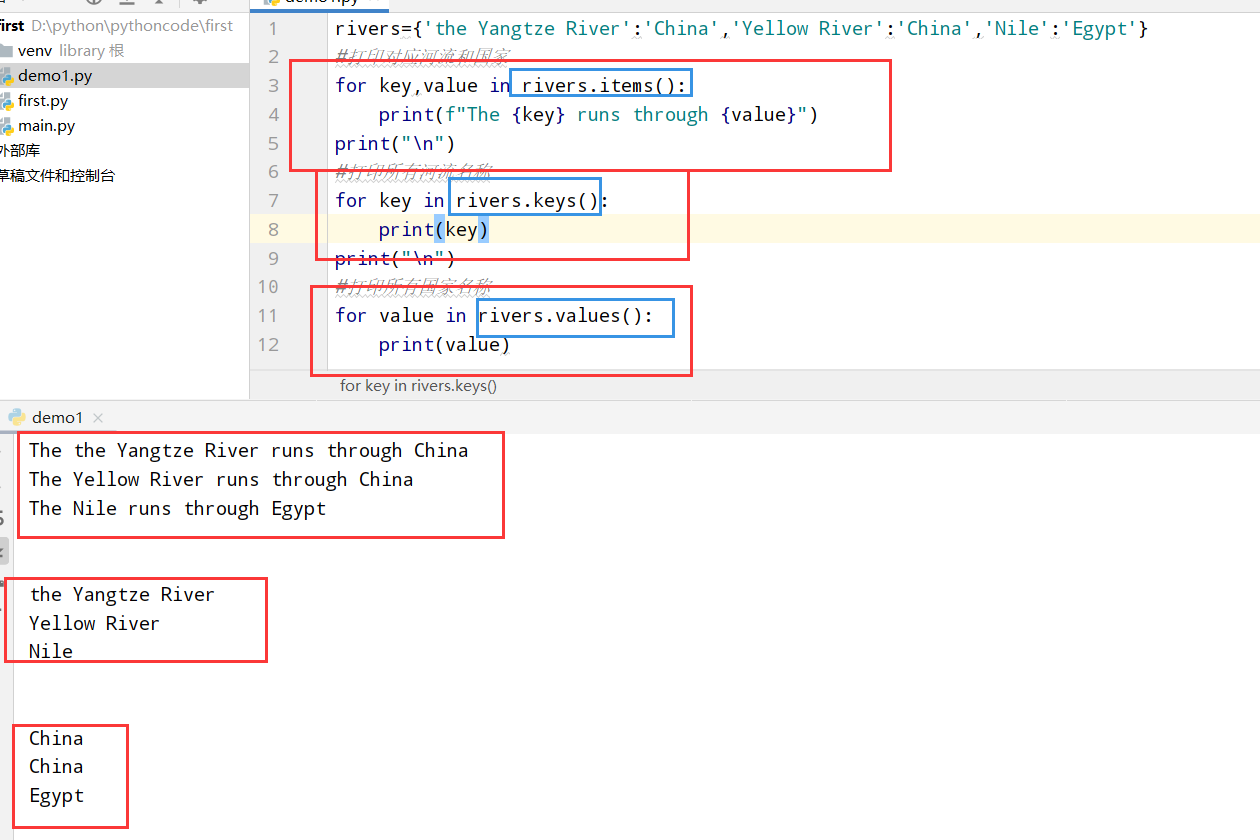
6.5 河流
具体代码
1 |
|
执行结果
6.6 调查
具体代码
1 |
|
执行结果
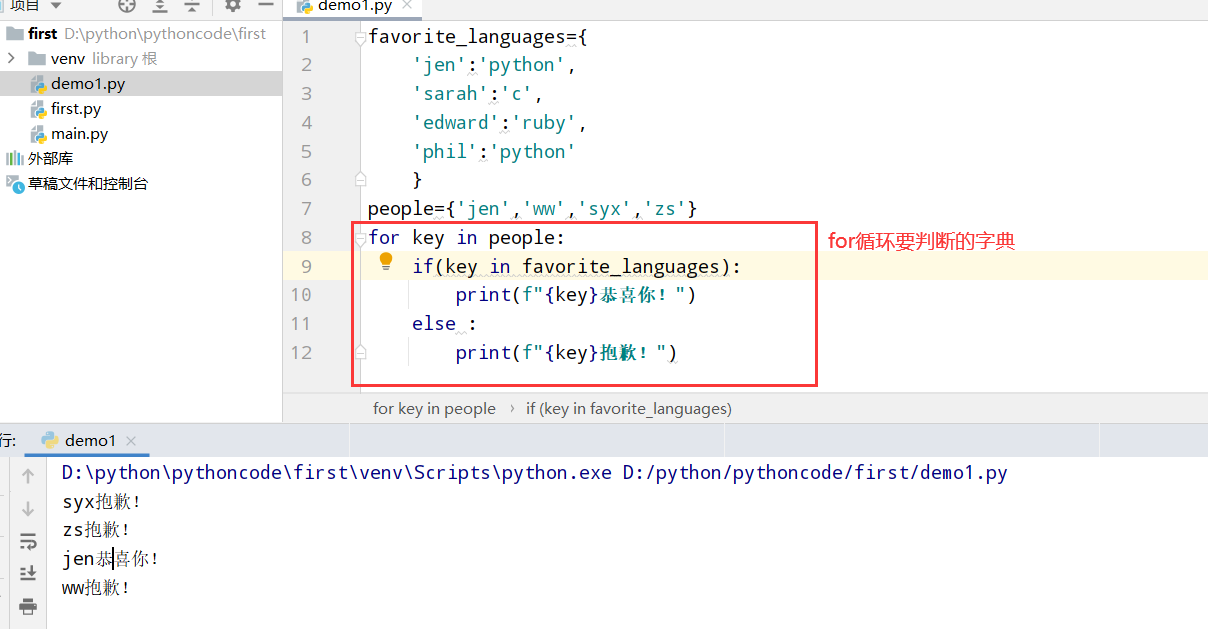
6.7 人们
具体代码
1 |
|
执行结果
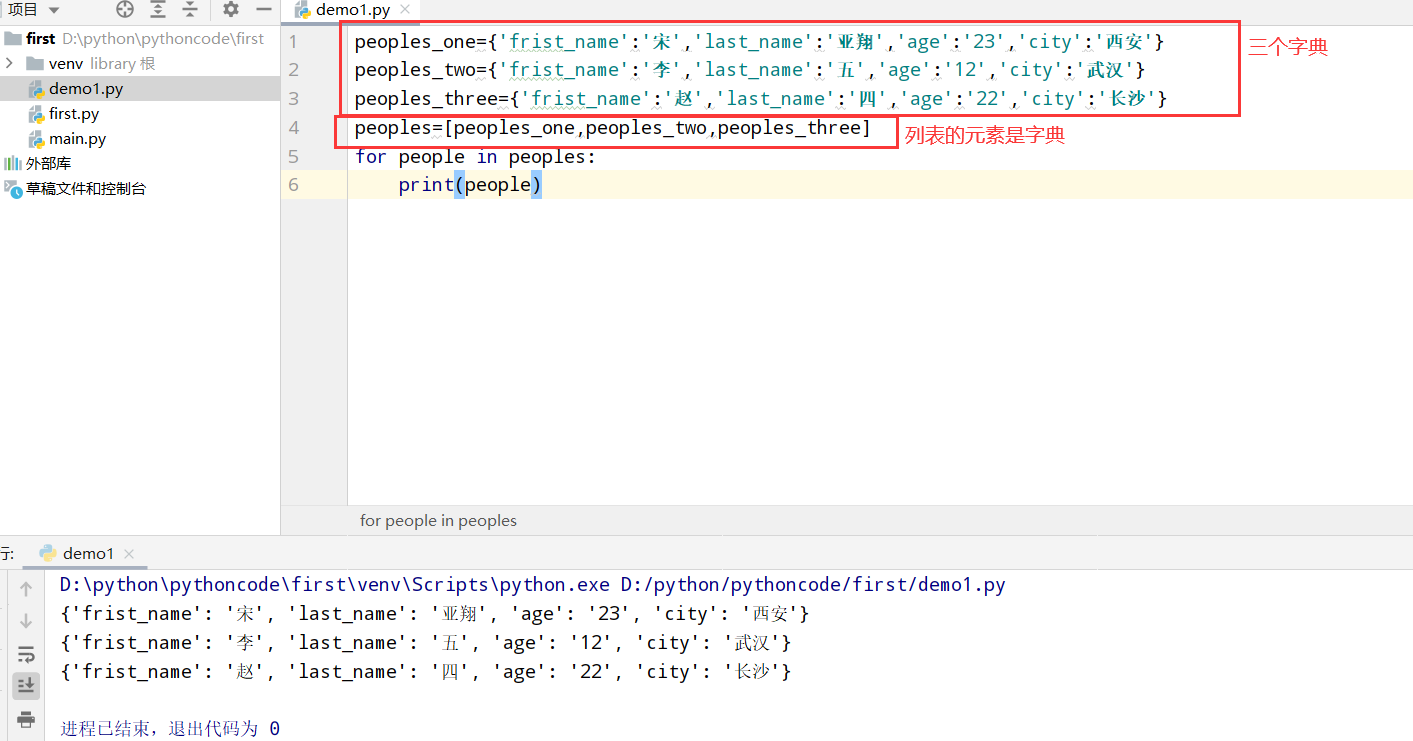
6.8 宠物
具体代码
1 |
|
执行结果
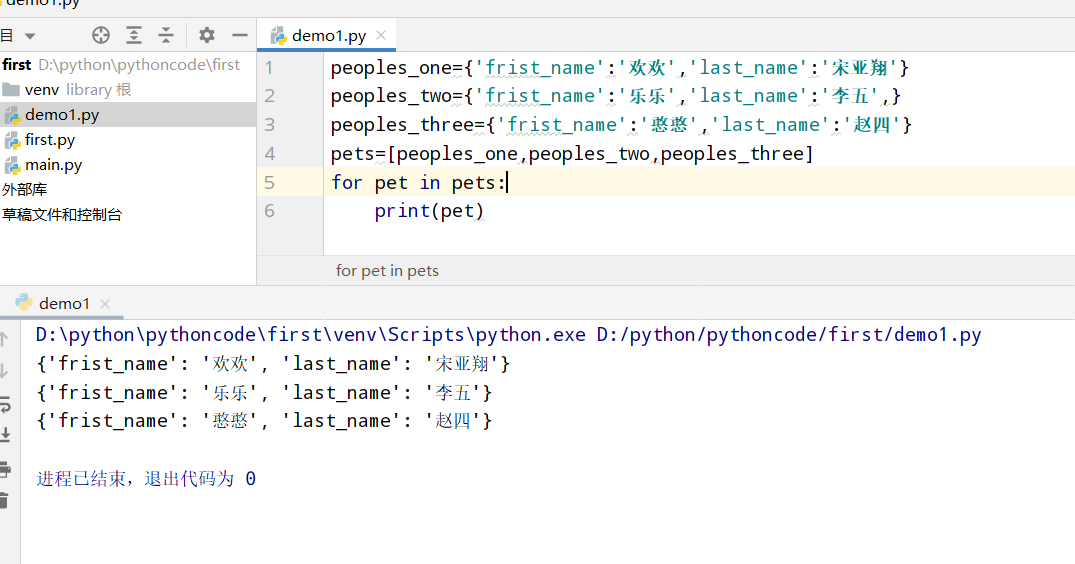
6.9 喜欢的地方
具体代码
1 |
|
执行结果
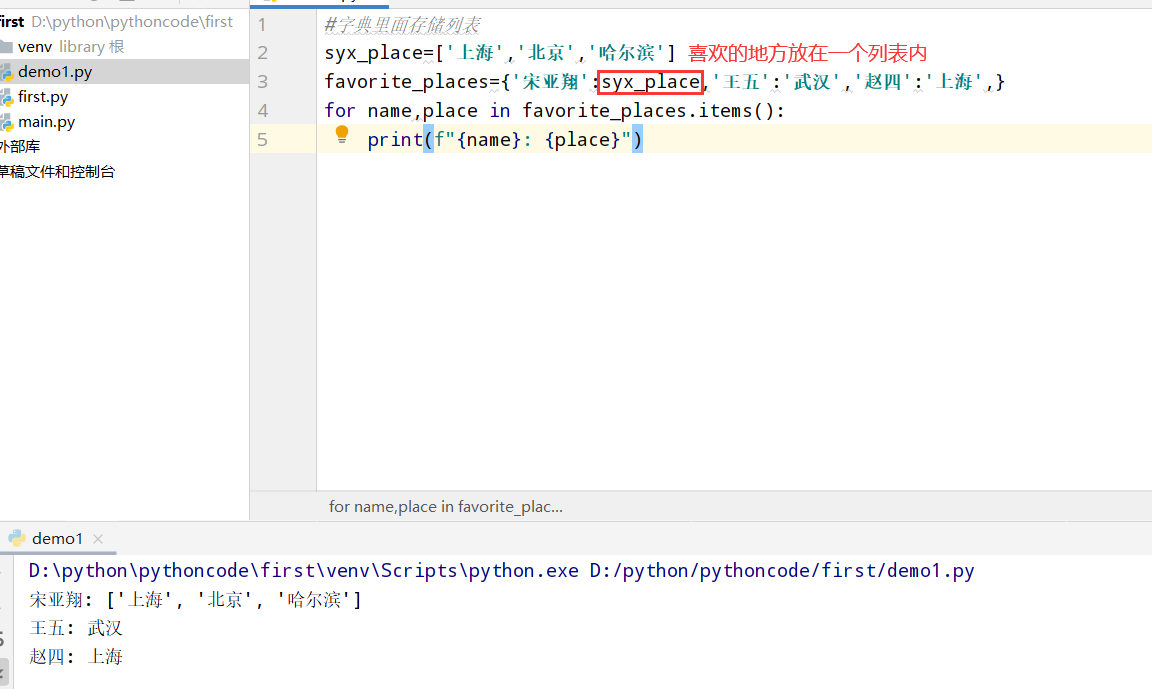
6.10 喜欢的数2
具体代码
1 |
|
执行结果
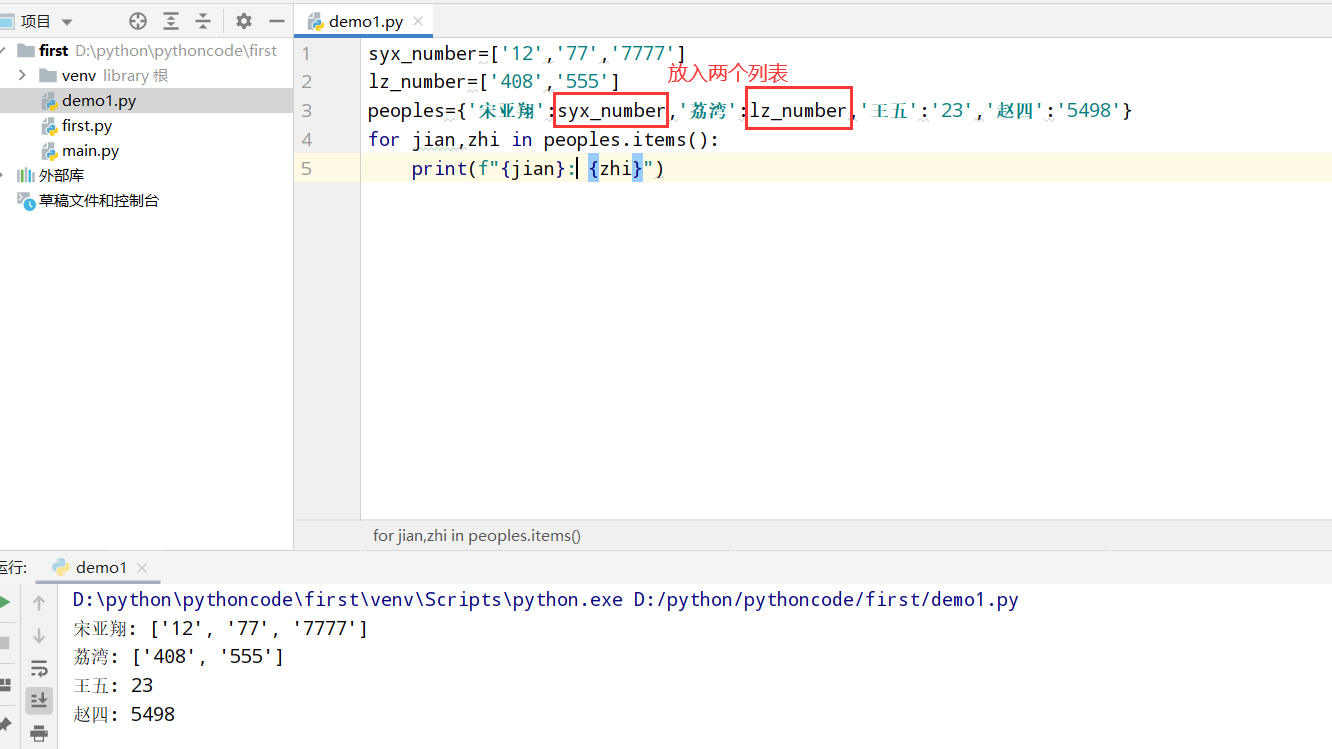
6.11 城市
具体代码
1 |
|
执行结果
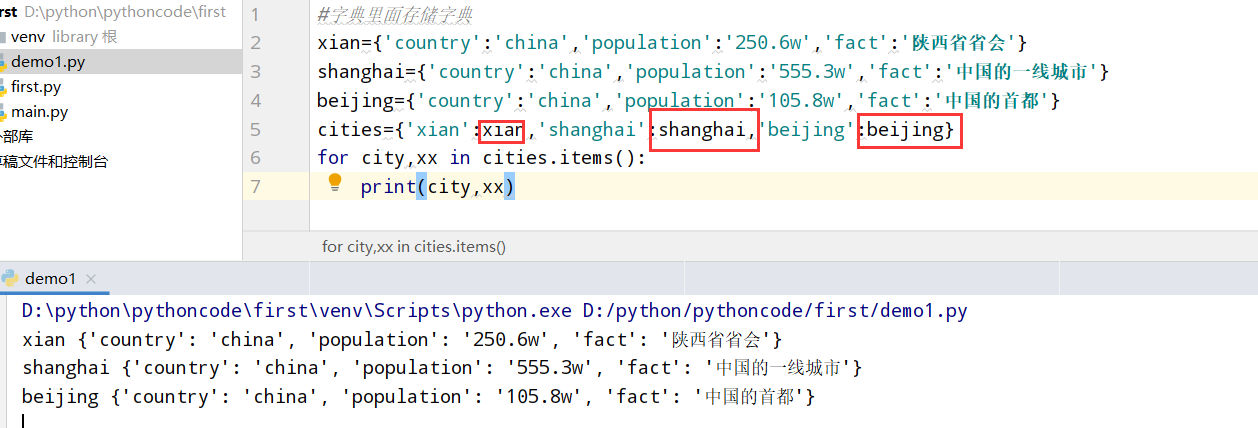
while循环
7.1 汽车租赁
具体代码
1 |
|
执行结果
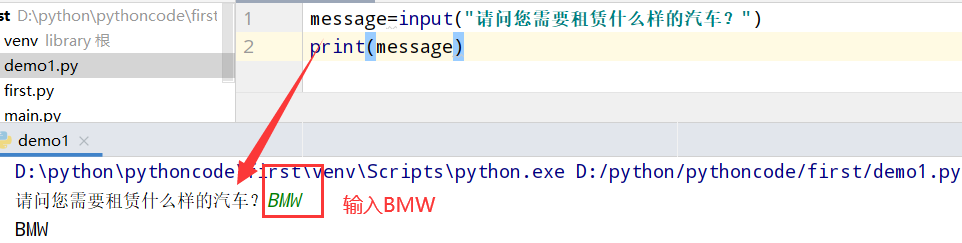
7.2 餐馆订位
具体代码
1 |
|
执行结果
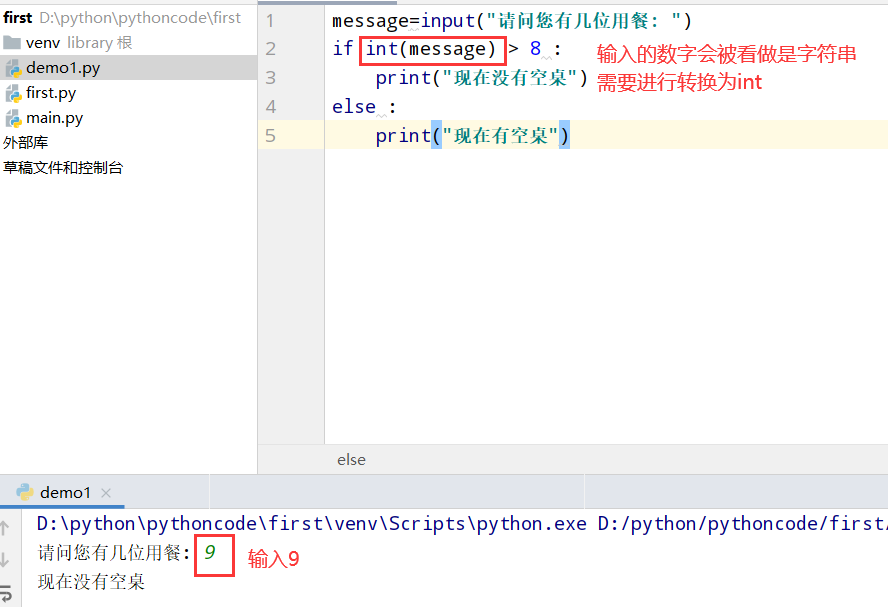
7.3 10的整数倍
具体代码
1 |
|
执行结果
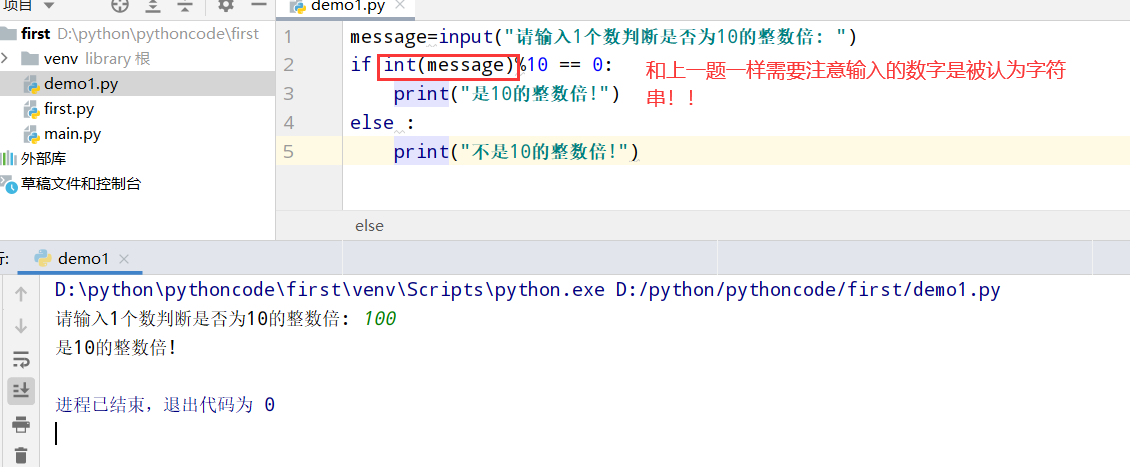
7.4 比萨配料
具体代码
1 |
|
执行结果
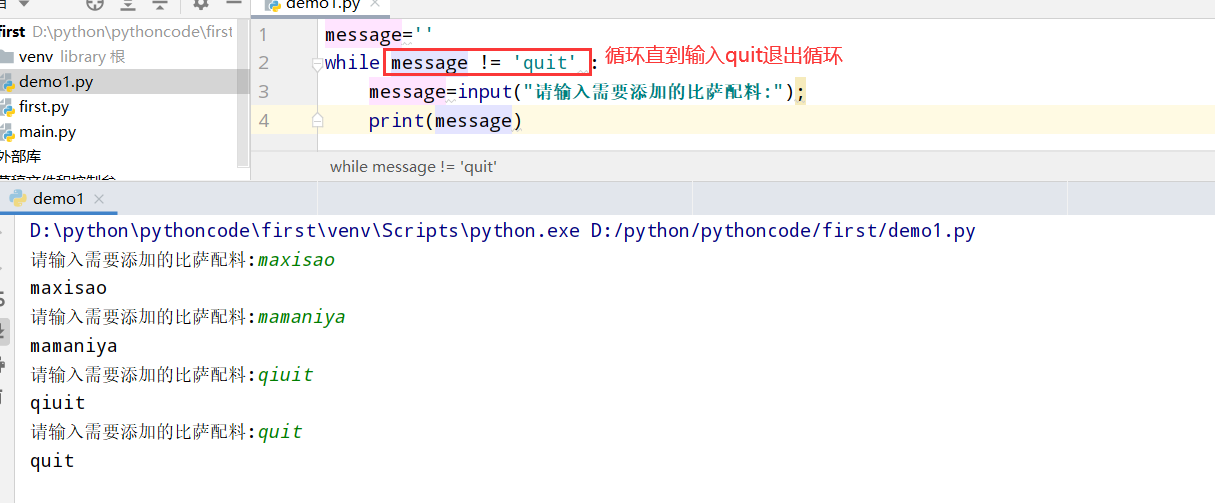
7.5 电影票
具体代码
1 |
|
执行结果
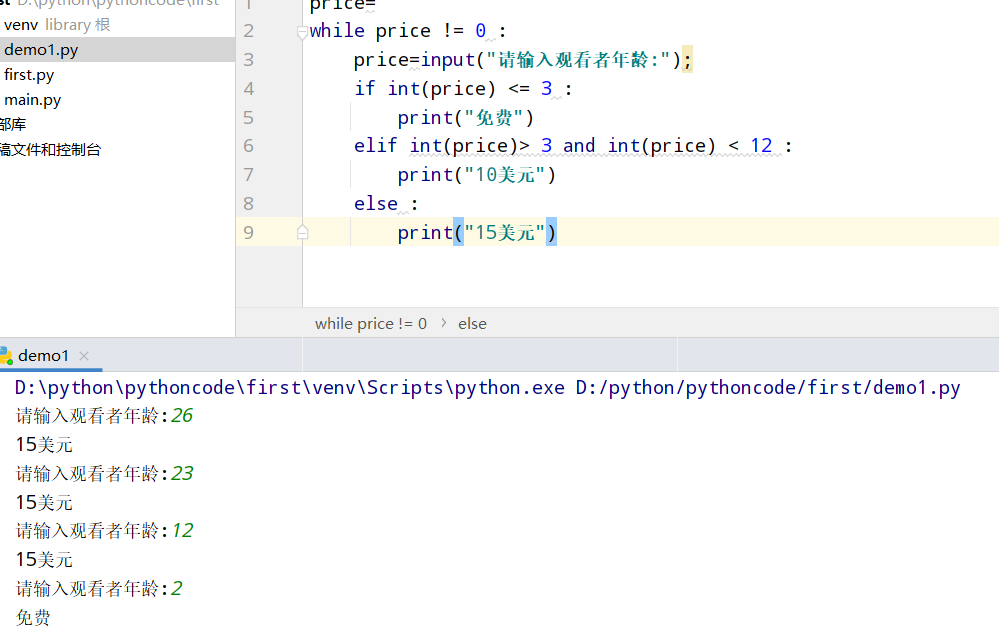
7.8 熟食店
具体代码
1 |
|
执行结果
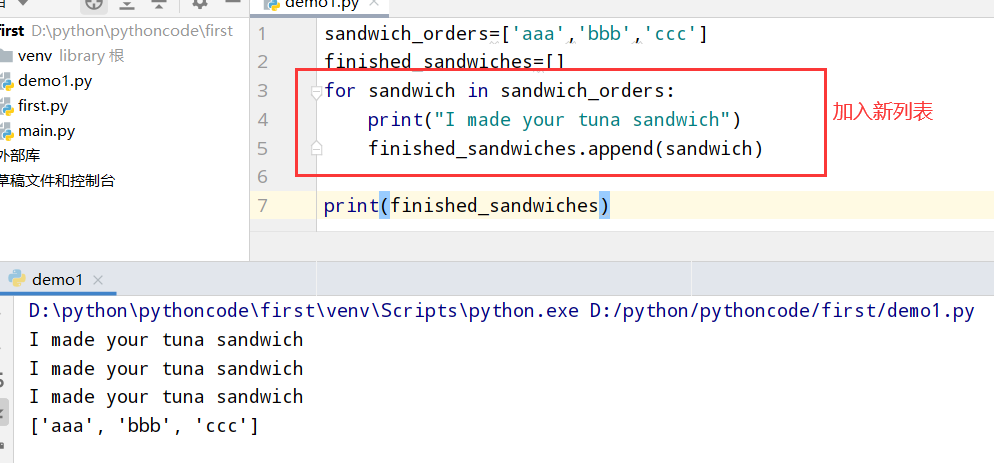
7.9 五香烟熏牛肉卖完了
具体代码
1 |
|
执行结果
7.10 梦想的度假胜地
具体代码
1 |
|
执行结果
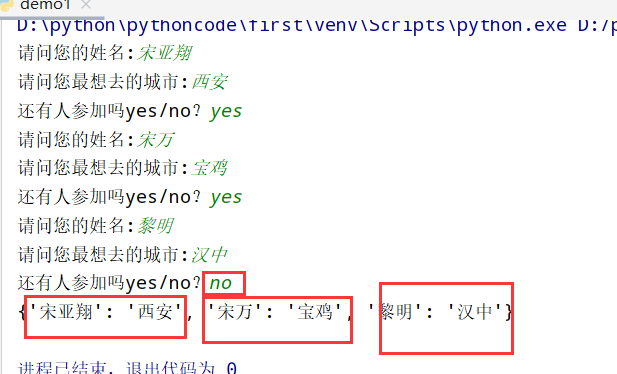
函数
8.1 消息
具体代码
1 |
|
执行结果
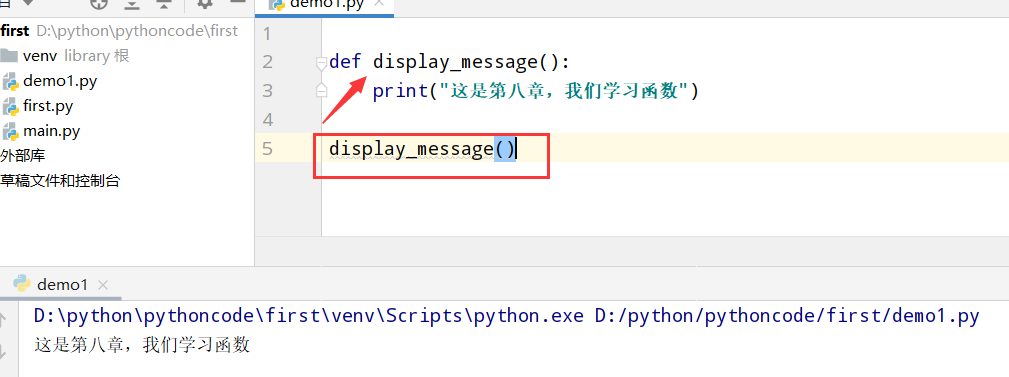
8.2 喜欢的图书
具体代码
1 |
|
执行结果
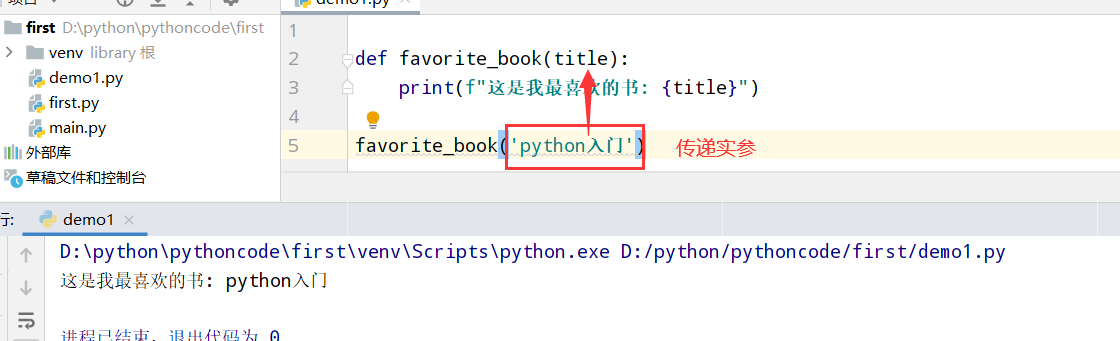
8.3 T恤
具体代码
1 |
|
执行结果
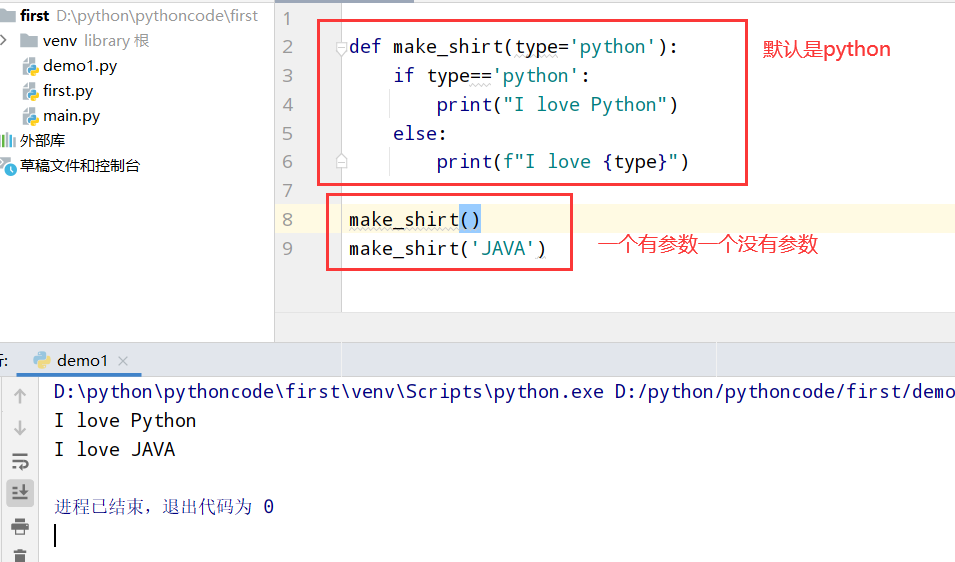
8.4 大号T恤
具体代码
1 |
|
执行结果
8.5 城市
具体代码
1 |
|
执行结果
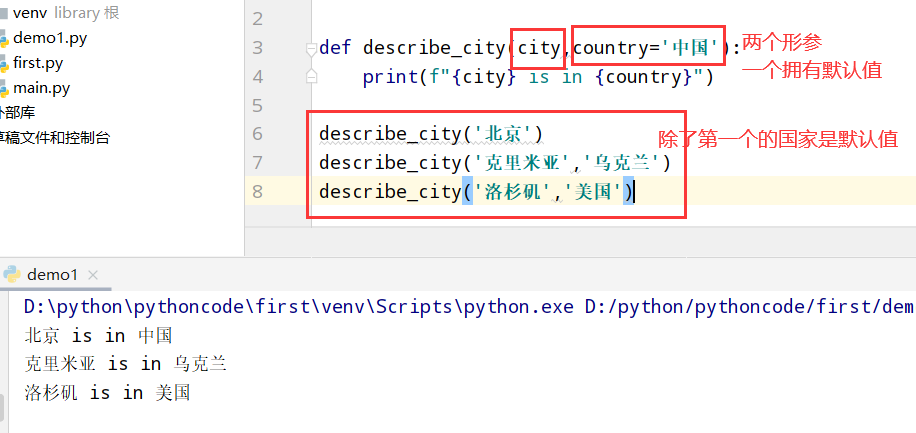
8.6 城市名
具体代码
1 |
|
执行结果
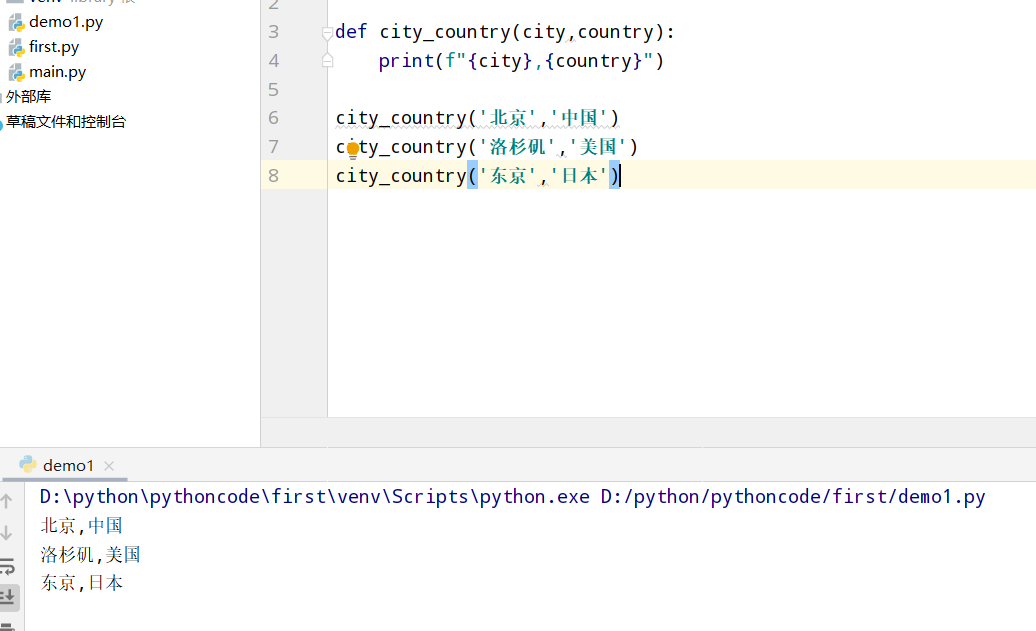
8.7 专辑
具体代码
1 |
|
执行结果
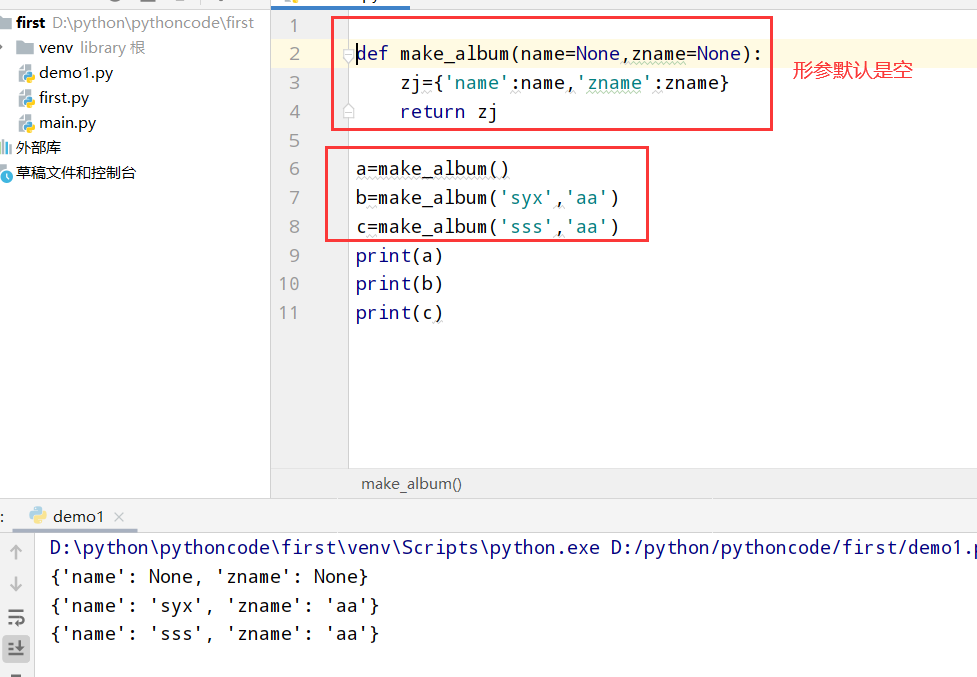
8.8 用户的专辑
具体代码
1 |
|
执行结果
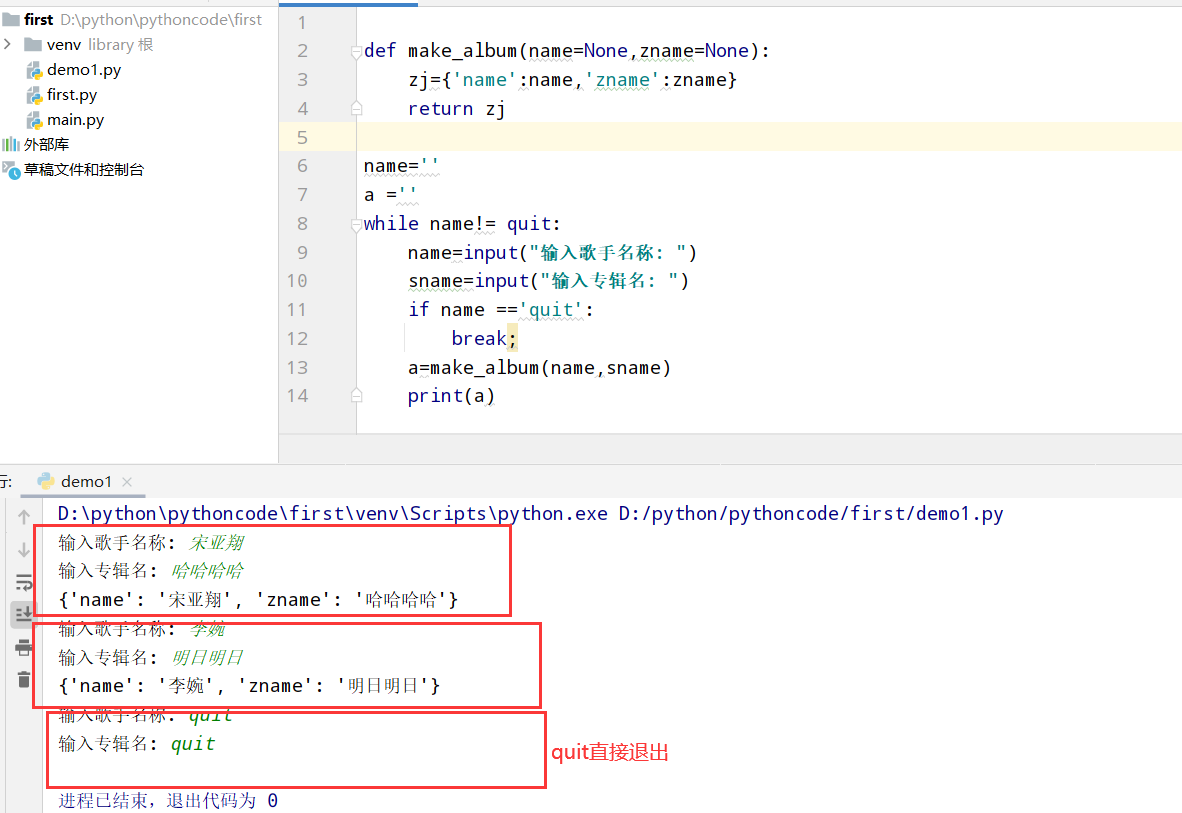
8.9 消息
具体代码
1 |
|
执行结果
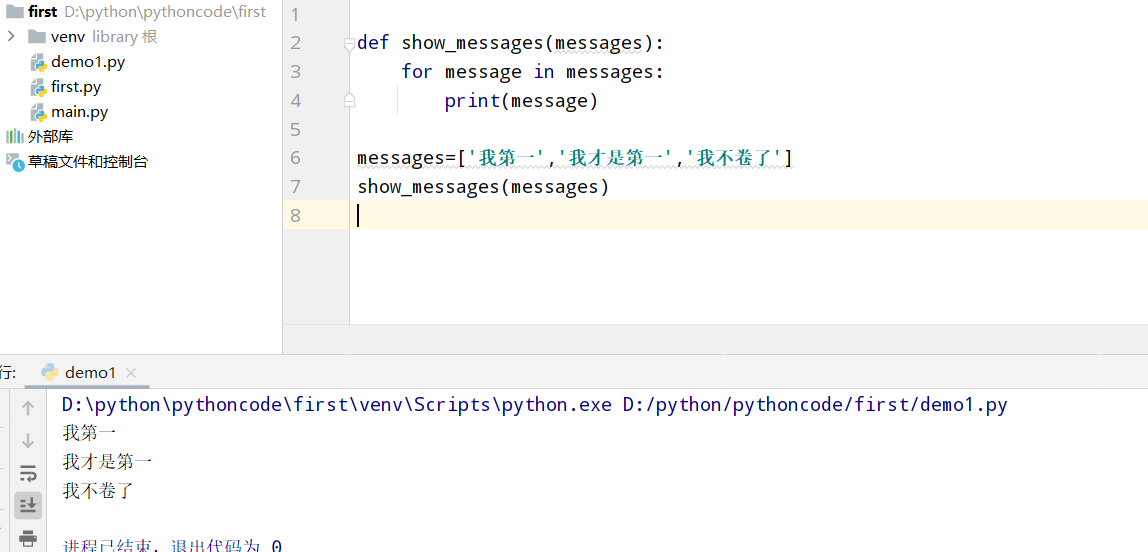
8.10 发送消息
具体代码
1 |
|
执行结果
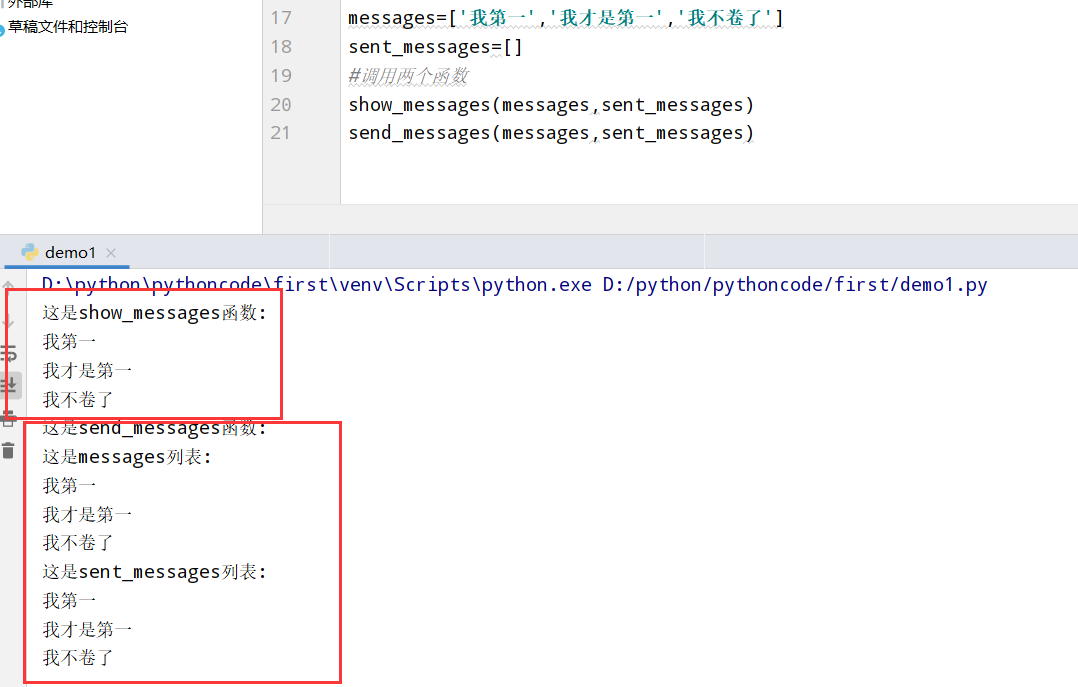
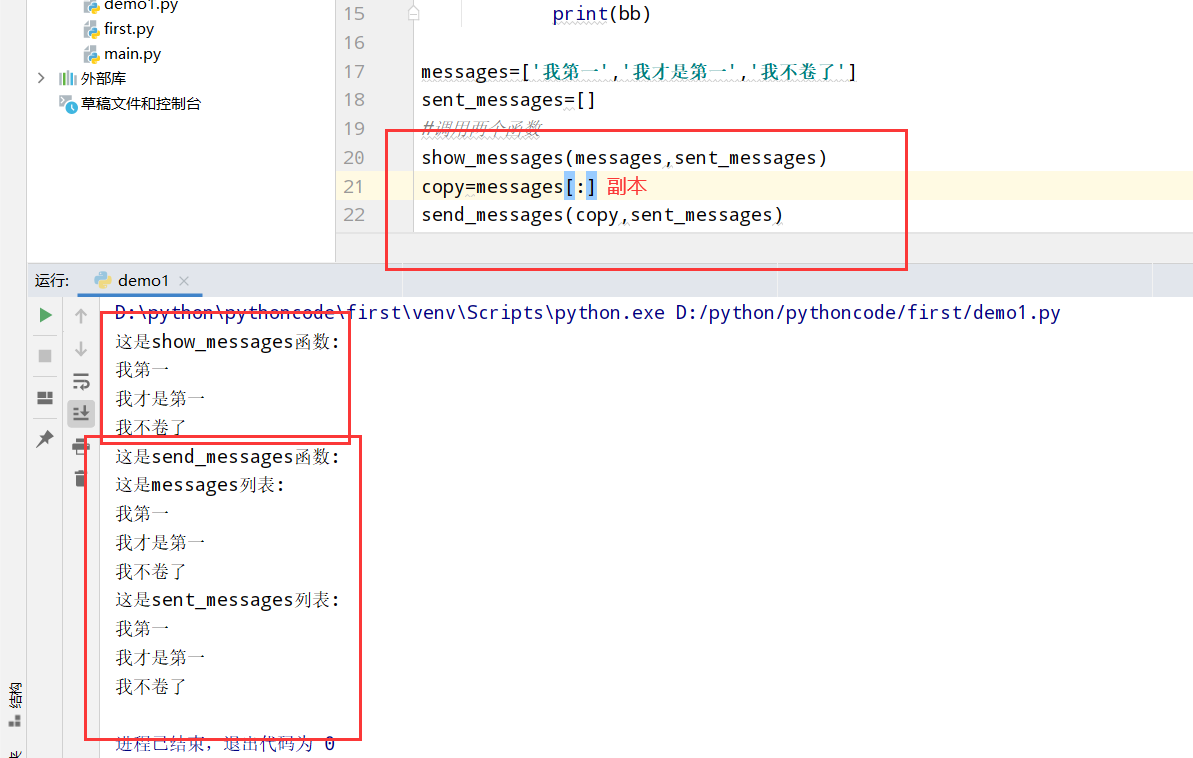
8.11 消息归档
具体代码
1 |
|
执行结果
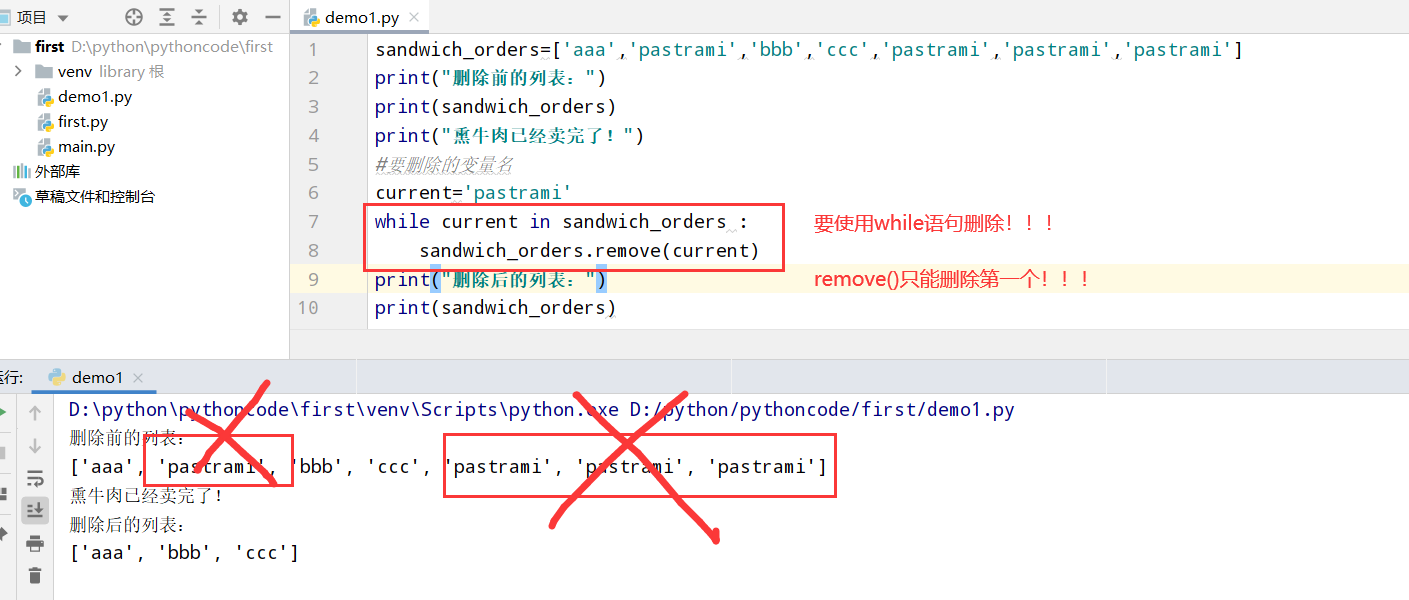
8.12 三明治
具体代码
1 |
|
执行结果
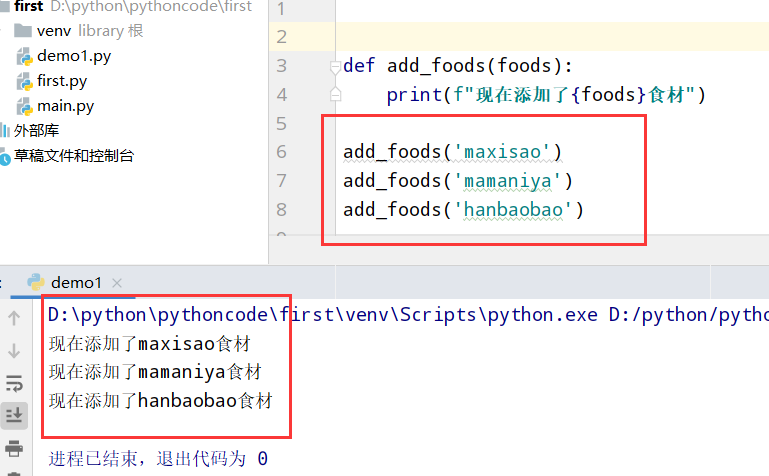
8.13 用户简介
具体代码
1 |
|
执行结果
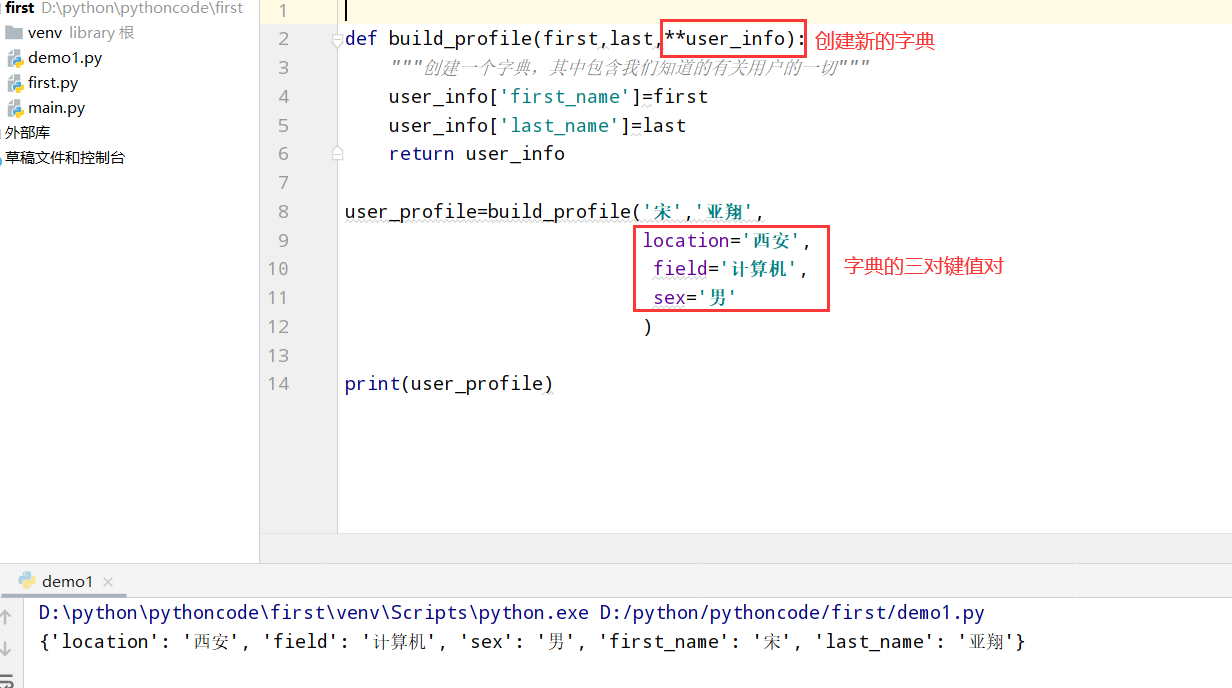
8.14 汽车
具体代码
1 |
|
执行结果

类
9.1 餐馆
具体代码
1 |
|
执行结果
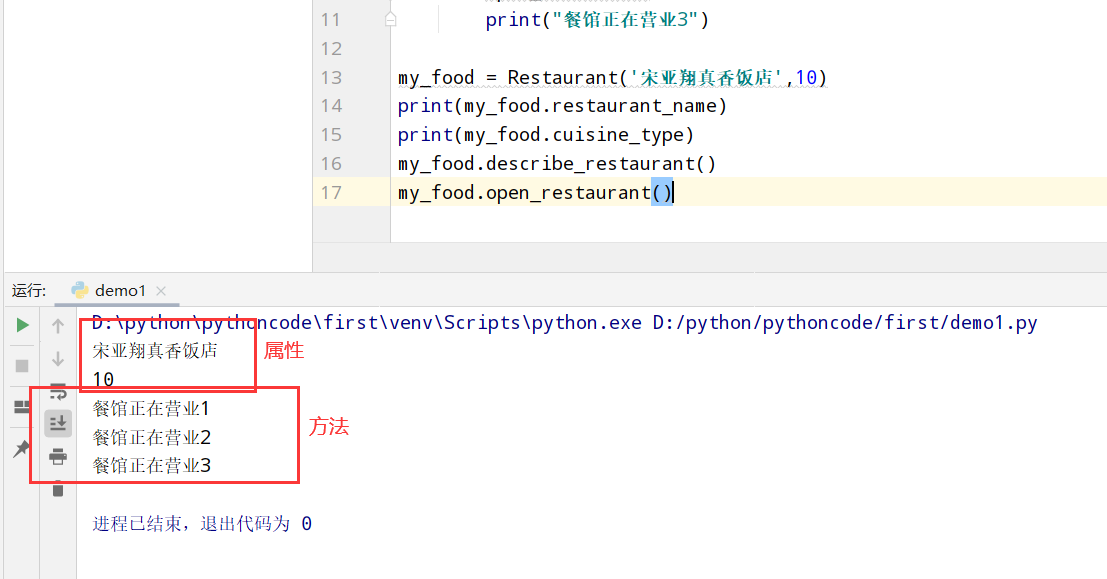
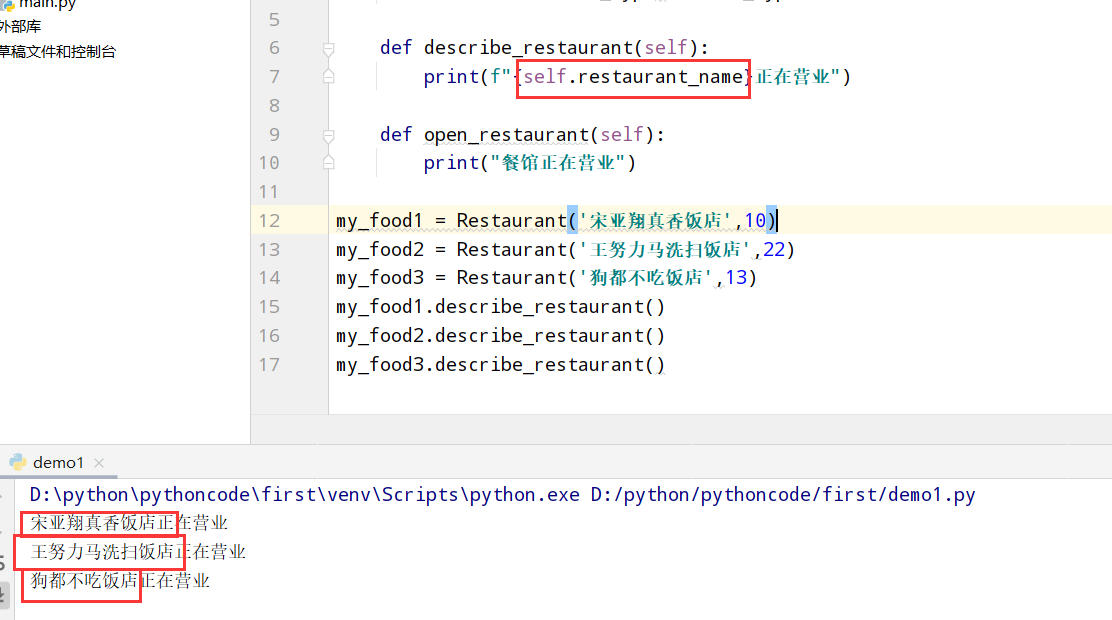
9.2 三家餐馆
具体代码
1 |
|
执行结果
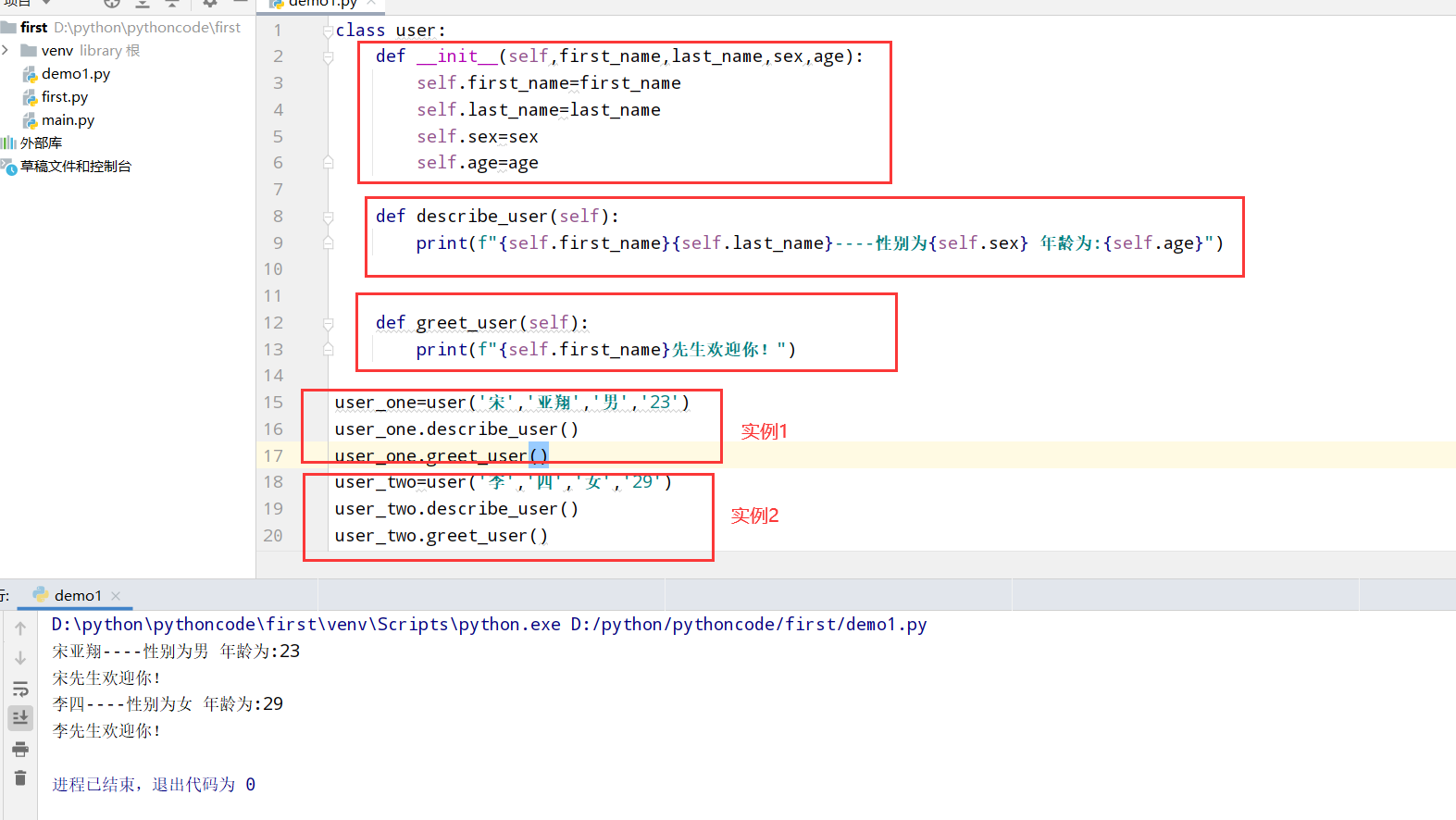
9.3 用户
具体代码
1 |
|
执行结果
9.4 就餐人数
具体代码
1 |
|
执行结果
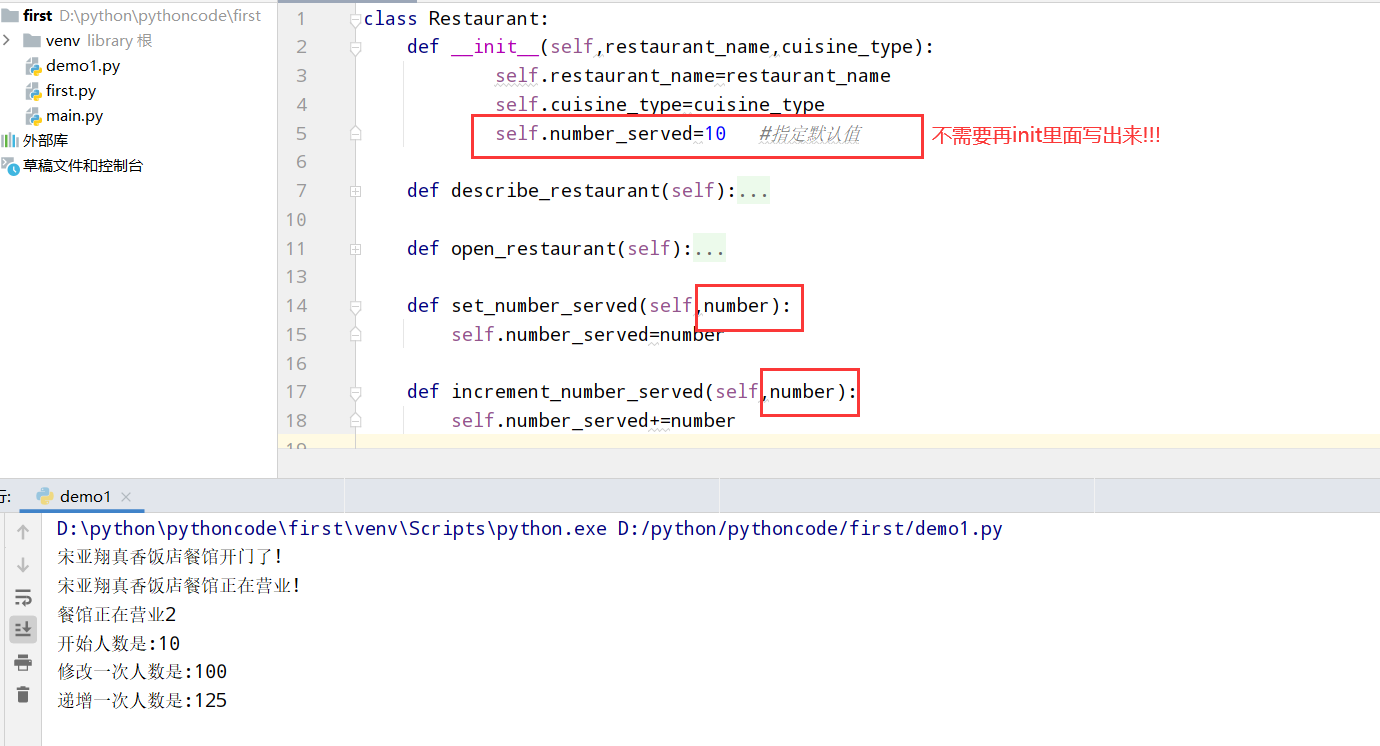
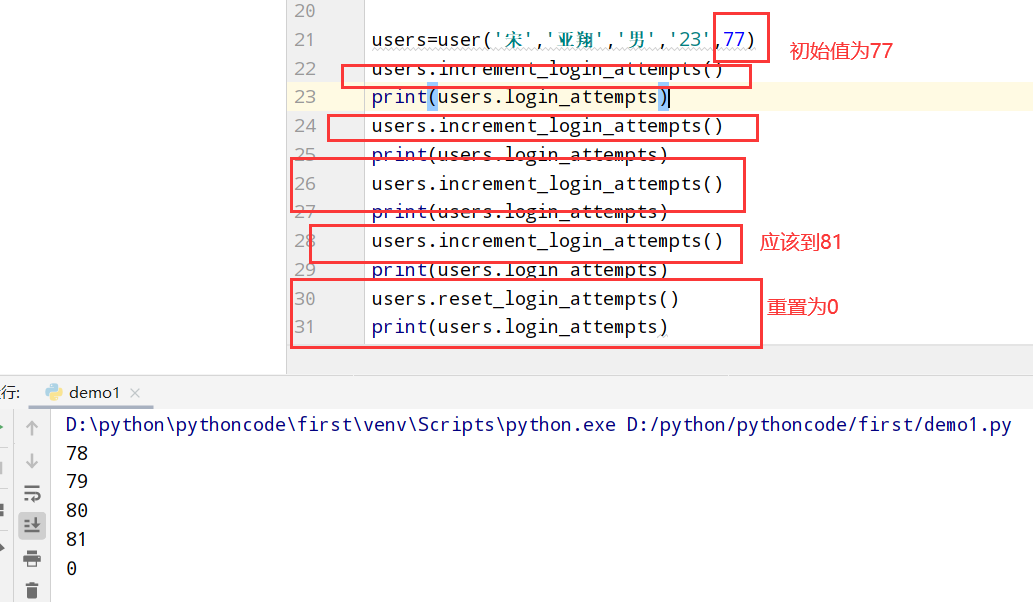
9.5 尝试登录次数
具体代码
1 |
|
执行结果
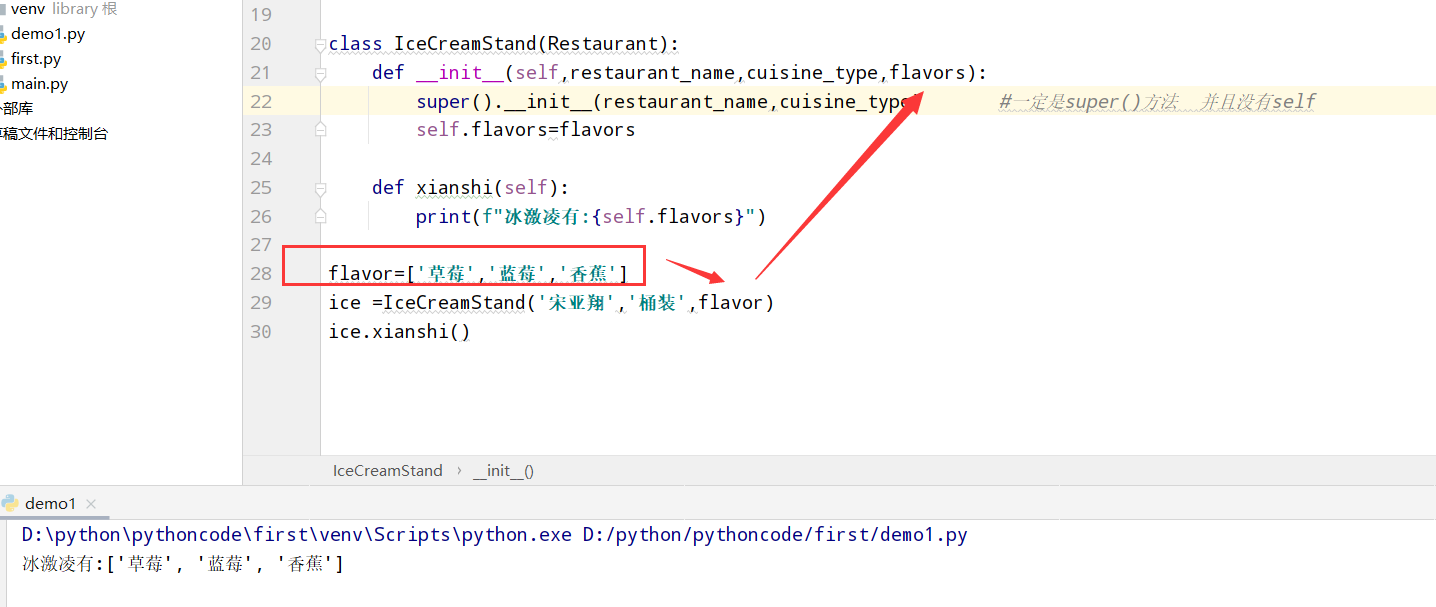
9.6 冰淇淋小店
具体代码
1 |
|
执行结果
9.7 管理员
具体代码
1 |
|
执行结果
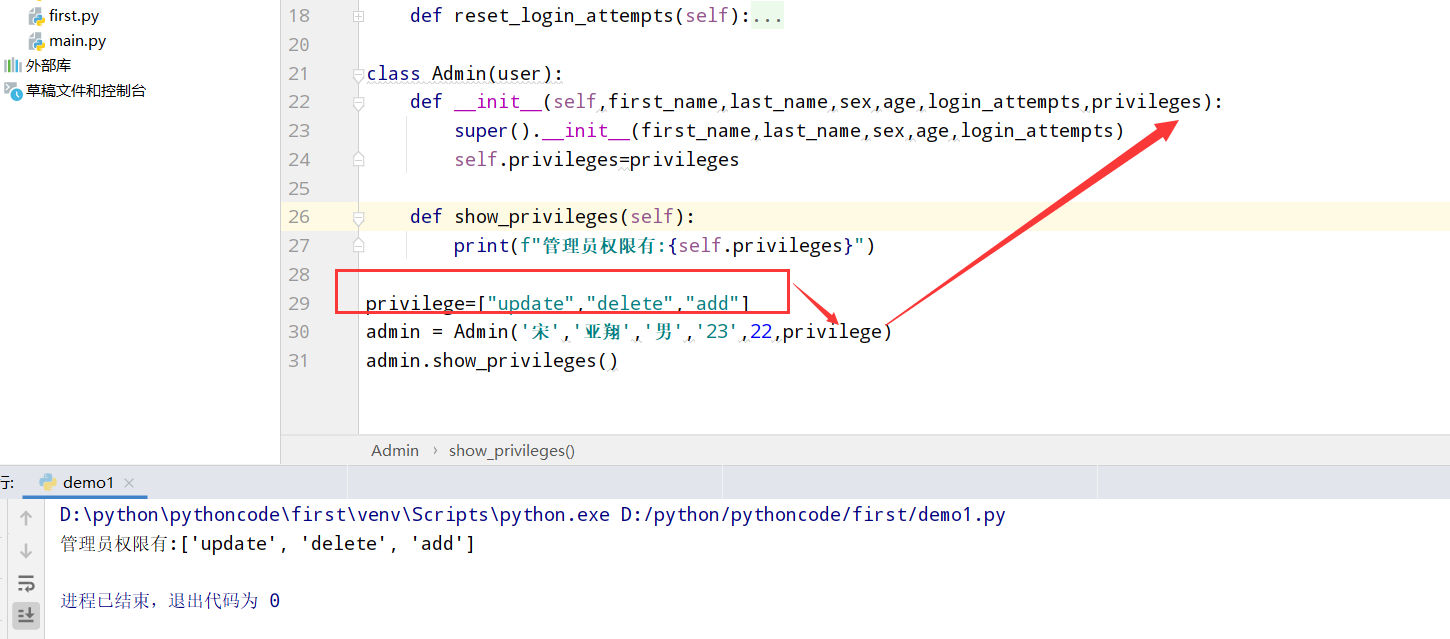
9.8 权限
具体代码
1 |
|
执行结果
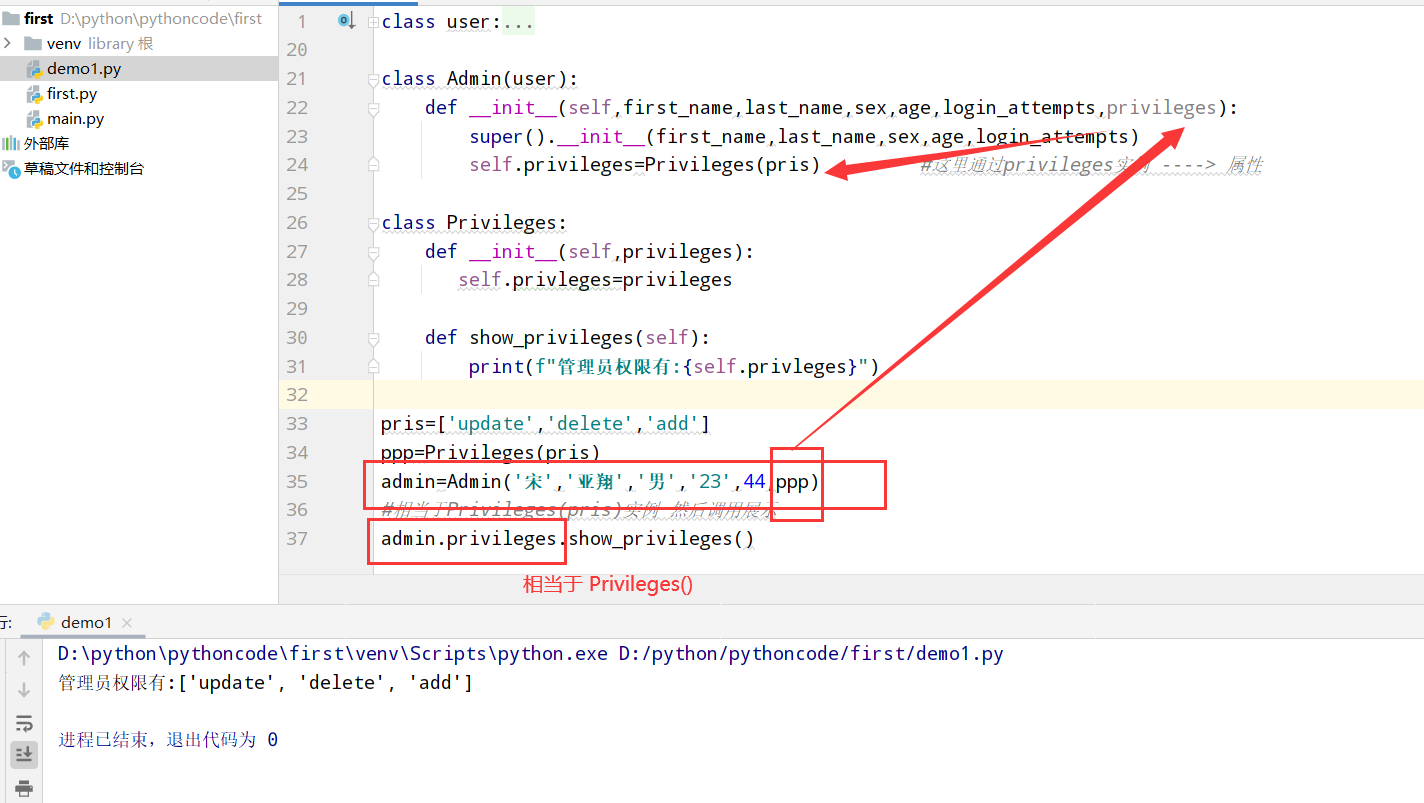
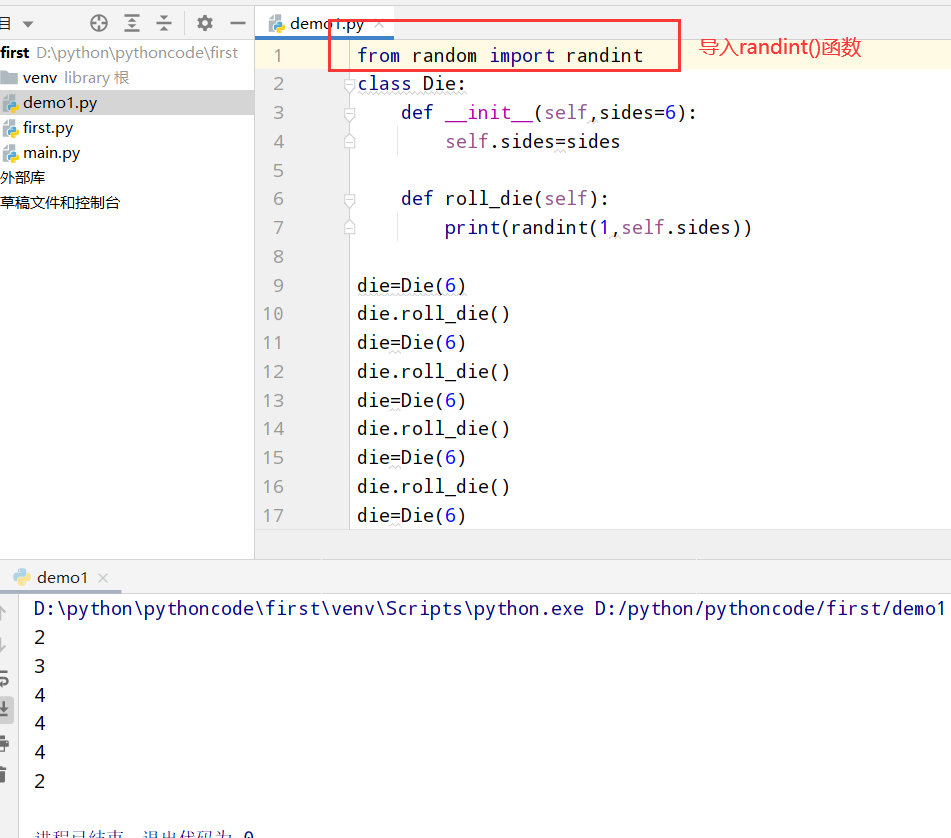
9.13 骰子
具体代码
1 |
|
执行结果
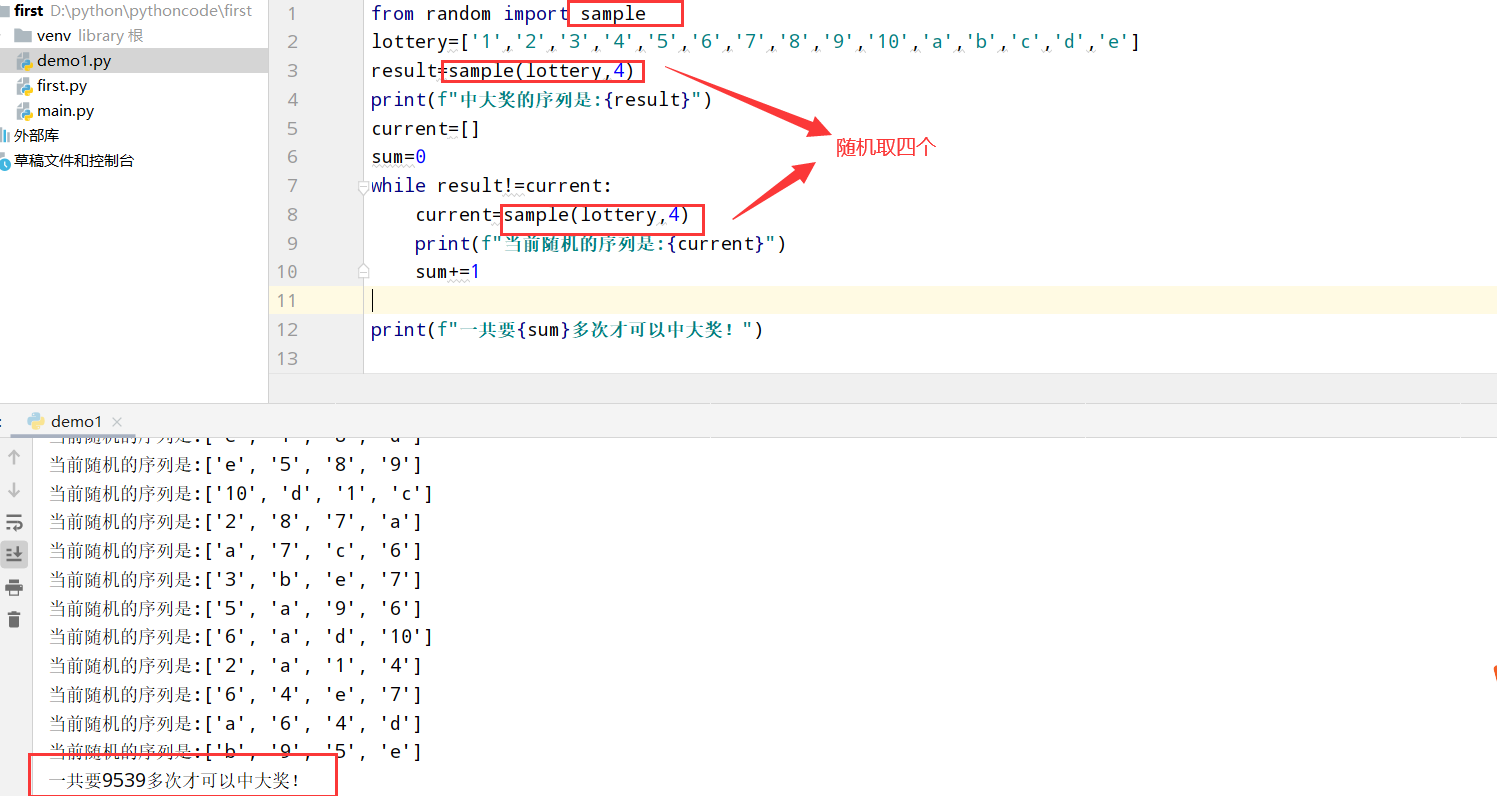
9.14 彩票
具体代码
1 |
|
执行结果

9.15 彩票分析
具体代码
1 |
|
执行结果
文件和异常
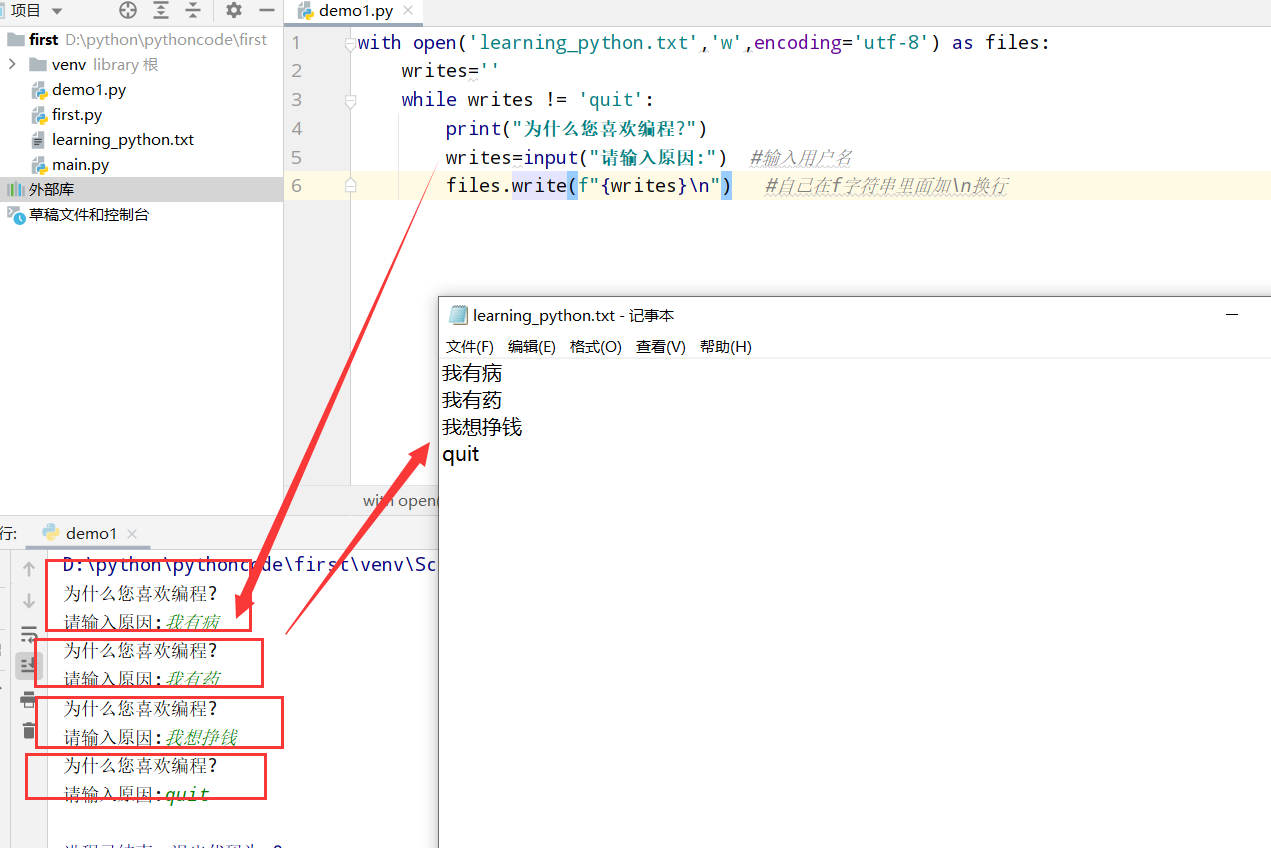
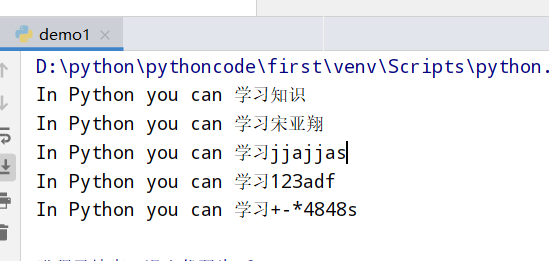
10.1 python学习笔记
具体代码
1 |
|
执行结果
10.2 C语言学习笔记
具体代码
1 |
|
执行结果
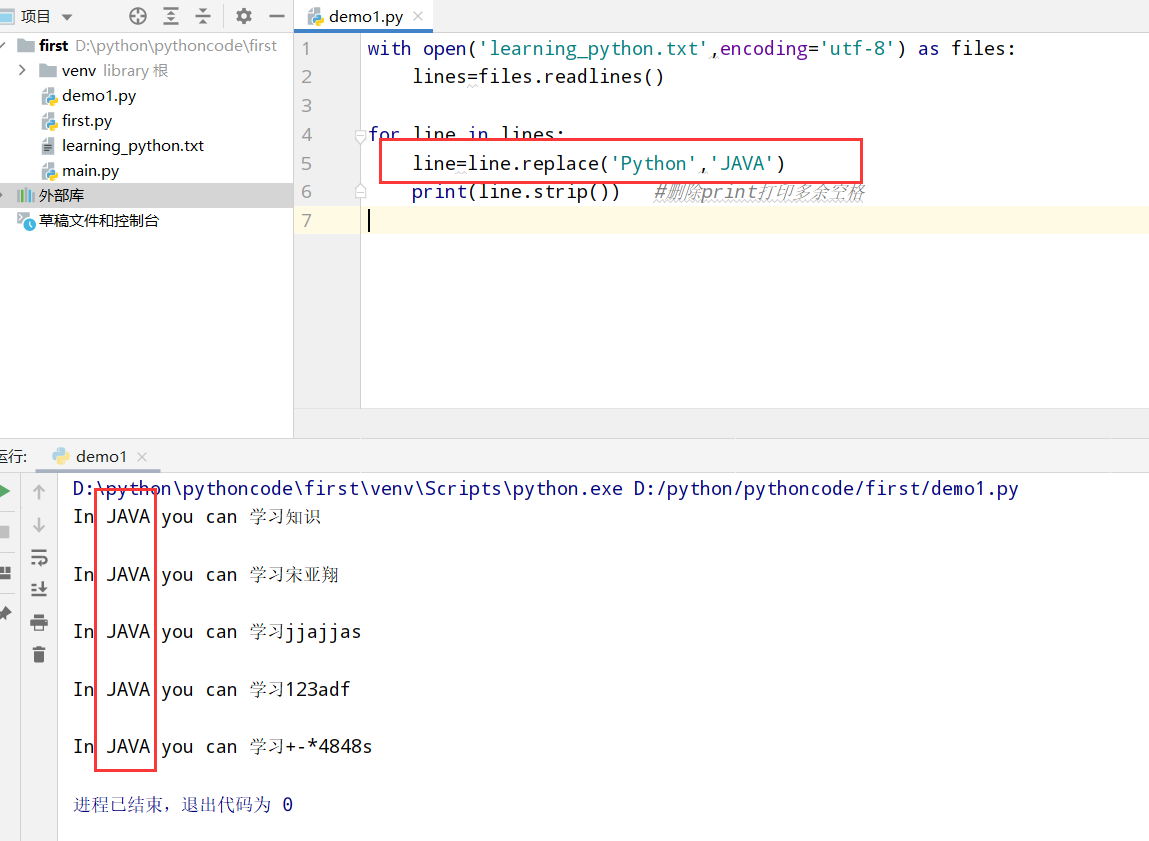
10.3 访客
具体代码
1 |
|
执行结果
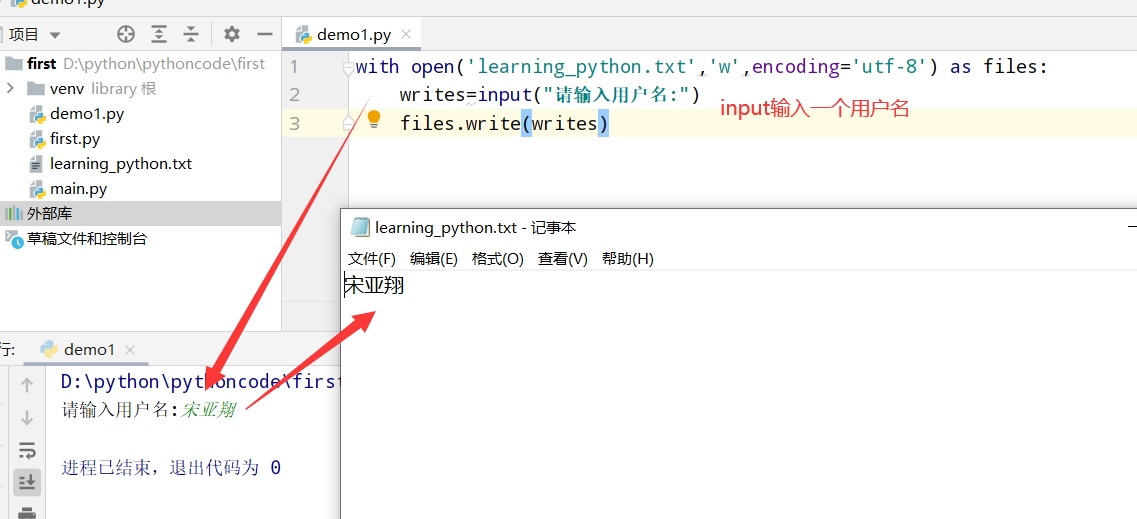
10.4 访客名单
具体代码
1 |
|
执行结果
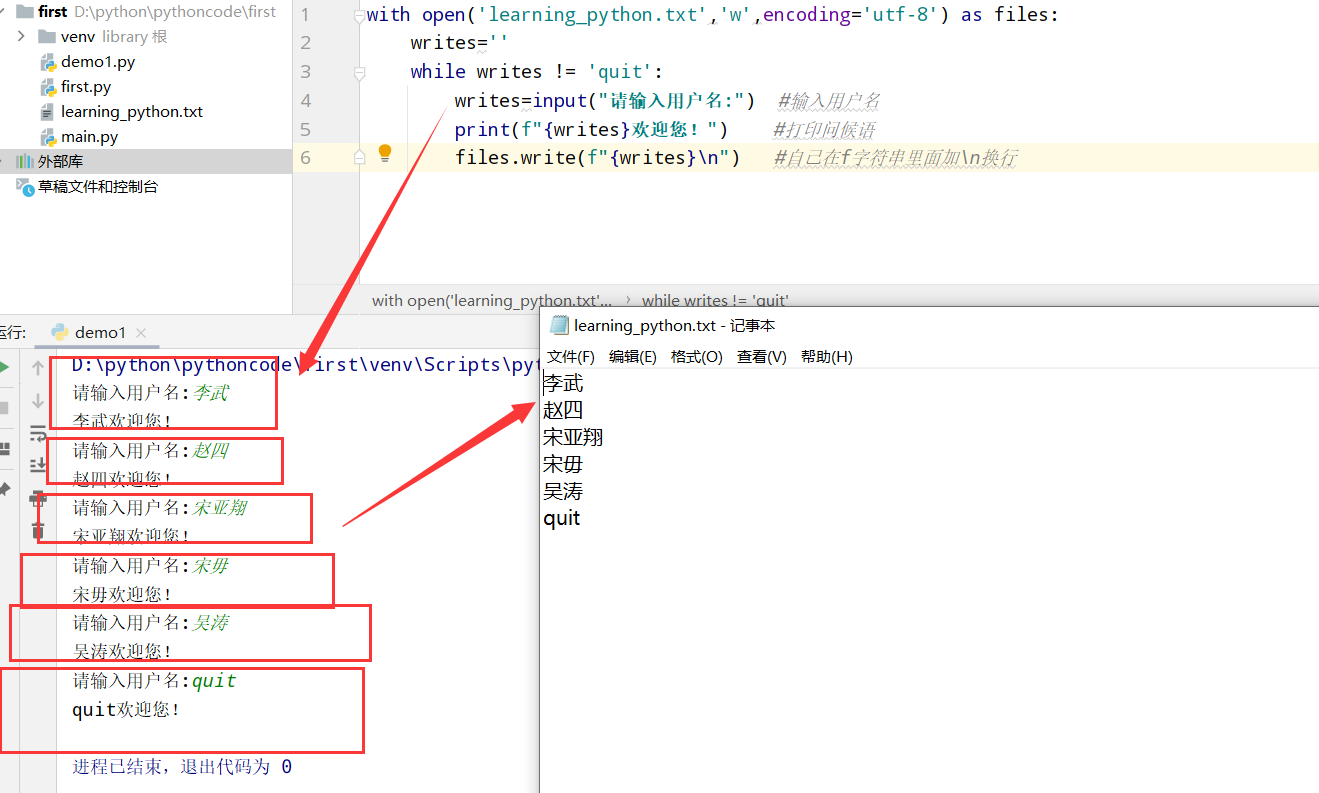
10.5 调查
具体代码
1 |
|
执行结果